Matt Weingarten is a Senior Data Engineer who writes about his work and perspectives on the data space on his Medium blog—go check it out!
Disclaimer
This is the continuation of a series of posts I will be doing in collaboration with Validio. These posts are by no means sponsored and all thoughts are still my own, using their whitepaper on a next-generation data quality platform (DQP for short) as a driver. This post or collaboration does not imply any vendor agreement between my employer and Validio.
Introduction
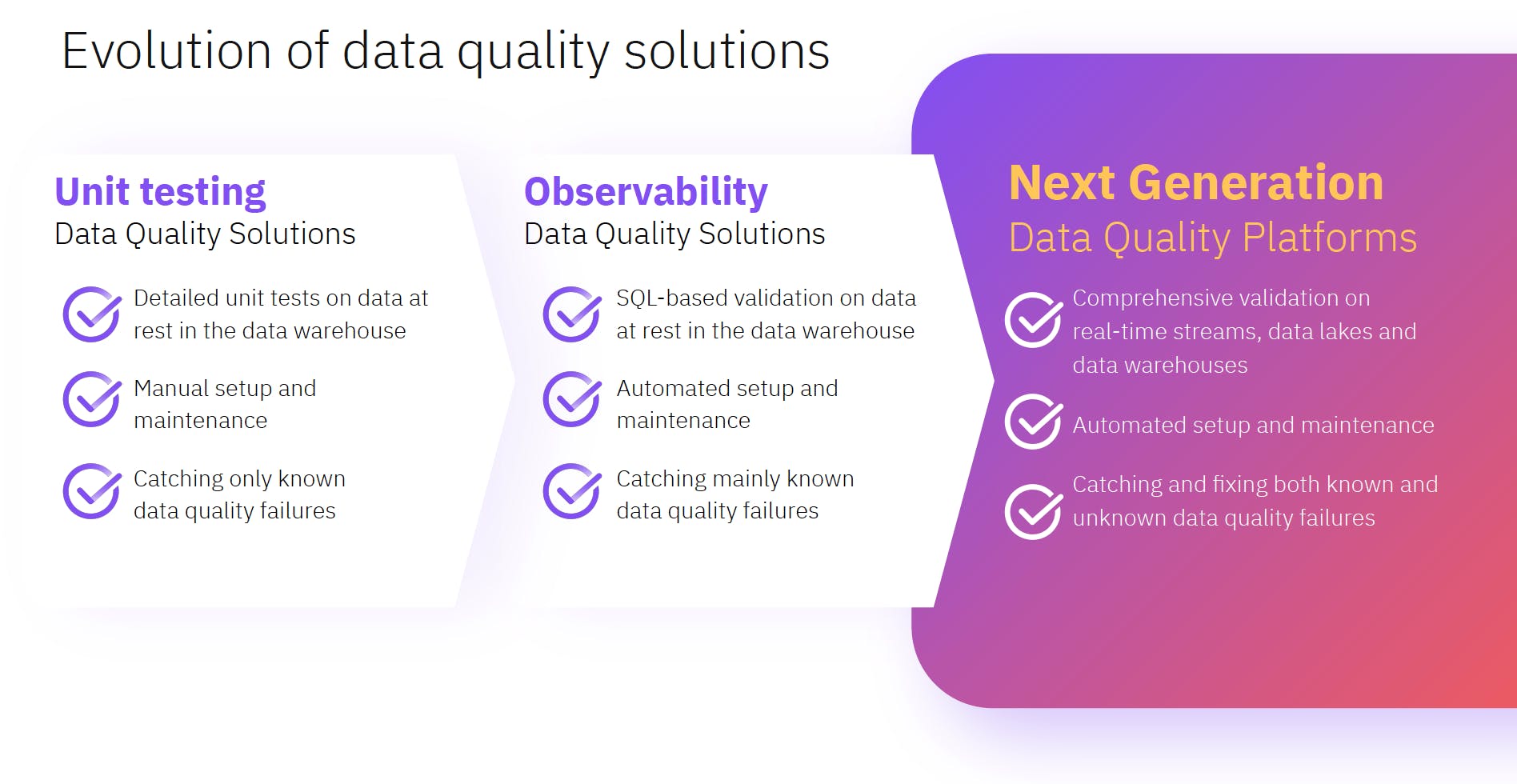
Now that we’ve covered end-to-end data validation and the different types of validation rules (manual, automatic, static, and adaptive), our tour of a proper DQP continues with an examination of how to validate everything comprehensively. Essentially, what technical capabilities need to be in place to catch “unknown” data quality failures?
Partitioning Data
As data engineers, we’re already quite familiar with the concept of partitioning data for faster access. How does that relate to data quality? Essentially, it’s the ability for a DQP to perform data validation on an individual segment rather than the full dataset. This in turn allows for proper multi-value segmentation (breaking down by multiple fields). Partitioning is necessary for performing data quality at scale and for doing proper root-cause analysis.
This is a part of my team’s data reconciliation process. Since every data feed we receive is a separate entity, we partition the data on that field and look at the KPI metrics for each of those feeds in isolation. Only certain feeds may have issues while others are perfectly fine, which narrows down the range of what needs to be reprocessed when the time comes (process only what needs to be reprocessed rather than the full dataset).
Univariate/Multivariate Validation
Univariate validation, focusing on the validating of a single data feature, is relatively straightforward, and definitely the norm when it comes to data quality. Multivariate validation, or validating relationships between multiple data features, is a bit more complicated. We may not be able to know what the correlation of two variables should be, but we can use trend analysis to figure out what that should look like over time so that it can be tracked accordingly for anomalies.
For example, two of the KPIs our reconciliation process checks are hits and visitors. If the amount of hits on a website goes up, the amount of visitors generally has gone up as well. It would certainly be anomalous for that not to be the case.
Metadata, Dataset, and Data Point Validation
There’s a lot of things that can go wrong with data (thanks, Captain Obvious). That’s why it’s important to have validation built into metadata, datasets, and data points themselves, so that we capture every aspect of the data.
Metadata validation refers to looking at concepts like freshness, schema, data ingestion rate, and row count. These are all important metrics within data observability, so it’s definitely not a surprise that metadata validation would focus on them. How are data observability and next-generation data quality related? Next-generation data quality is one step ahead of observability as it focuses on not only catching bad data, but also fixing it.
Dataset validations look at summary metrics like mean, standard deviation, cardinality, and that the distribution of a dataset does not remarkably change over time. Data point validations look at each row of the data to make sure the data points looks as expected. Essentially, all three of these validations are integrity checks that we ensure hold before even doing any further checks from a validation rule standpoint, and it’s important that all of them are implemented. If you deploy a change, for example, to your processing that changes the logic for a particular column or set of columns, you can have a normal row count that would pass the metadata validation, but the data point validations would catch the fact that the values are not what they should be.