Matt Weingarten is a Senior Data Engineer who writes about his work and perspectives on the data space on his Medium blog—go check it out!
Disclaimer
This is the continuation of a series of posts I will be doing in collaboration with Validio. These posts are by no means sponsored and all thoughts are still my own, using their whitepaper on a next-generation data quality platform (DQP for short) as a driver. This post or collaboration does not imply any vendor agreement between my employer and Validio.
Introduction
In our previous post about data quality platforms, we discussed the need to support end-to-end data validation. In short, most platforms today only connect to the warehouse layer for validations, but that’s not a proactive strategy, and it’s therefore imperative to support checks as they flow into the system in real-time.
What types of checks does a DQP need to support? Just like we want to have end-to-end validation in place, a good DQP also needs to support all types of rules. Let’s dive in.
Validation Rules
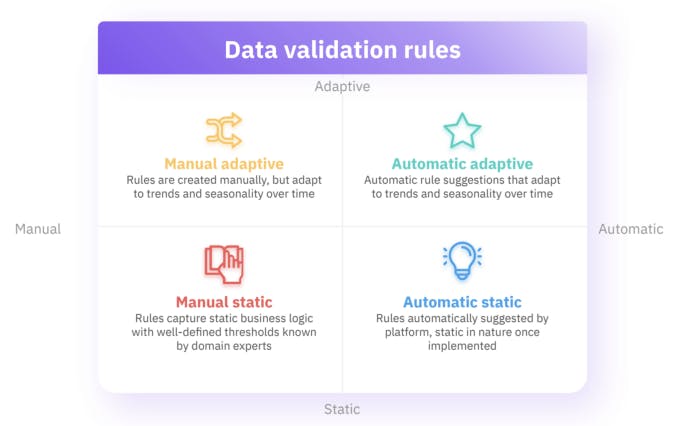
Data validation rules fall into two dimensions:
- Manual vs. automatic rules: Manual rules are those that are created manually by a person (unit testing, essentially), while automatic rules are automatically configured/suggested by the DQP through analysis
- Adaptive vs. static rules: Adaptive rules adjust dynamically to the data over time (seasonality or other trends), while static rules stay the same regardless of what happens to the data (fixed values)
Combining these two dimensions results in the following four quadrants of rules:
- Manual adaptive
- Manual static
- Automatic adaptive
- Automatic static
We’ll now take a more detailed look into those rules and how a DQP can support them.