Validating Data In The Data Warehouse
The data warehouse is the traditional place where data quality takes place these days. Connecting to a warehouse is fairly straightforward and from there, you can generate reports and dashboards in a streamlined manner.
In my current role as a data engineer, our team’s data reconciliation reports currently work in this format. After our data is dumped into Snowflake, we generate daily reports of the KPIs across all our different data feeds, so that we can see where any issues occurred. While this works, there’s more that can be done, as we’re not seeing any issues until the data lands in the warehouse, limiting our ability to be proactive.
Validating Data In The Data Lake
Data lakes tend to store more unstructured data than data warehouses, which is why warehouses are regarded as the “proper” location to set up a data quality platform. However, there are plenty of worthwhile data sources that never trickle into the warehouse, meaning that a platform also needs to be in place on a data lake so that their quality can be captured.
Having a platform in place on the data lake can be seen as proactive, as this can allow engineers to potentially catch any data quality failures before it gets to the warehouse layer. Being able to rectify any issues before they get to the end state helps ensure that the warehouse can be trusted as a true source of data.
The concept of validation in the data lake itself will be a part of our team’s second iteration of data reconciliation. Here, we’ll transition from daily to hourly reports (which is how often we currently receive our data) that run from within our data lake. Currently, we definitely face some headache in not being able to do so. This will give us increased insight into the source of any potential mismatches, so that we can more quickly rectify them on our end and keep the overall end-to-end process running as smoothly as possible.
Validating Data In The Data Stream
Streaming data is an already popular form of data ingestion and will continue to grow within the next few years, as a part of my predictions on the future of data engineering. To be able to track data quality within the stream itself would be even more proactive than the data lake, as you’d be getting right to the root of any issues in the data’s raw state.
However, building a platform that can handle the complexities of tracking streamed data is not so easy. It’d require a complex infrastructure and a different backend than what many providers these days have. Is it possible, though? Yes.
Validating Data In Real-Time
We live in an age of data where instant feedback is critical, and data quality therefore can’t lag far behind. Being able to handle whatever granularity makes sense for a particular use case is a necessity of a data quality platform, even if that means real-time analysis. This is a part of the data-driven vision, which was one of my main takeaways from this year’s DDAC.
An example of where real-time analysis would be helpful within a company like the one I currently work at is in the event data of the business operations and machinery. If a particular operation was starting to show deviations outside the normal bound of what’s considered to be safe, it’d be important for the industrial engineers to quickly analyze what could be the underlying issue. After all, any delay on proper rectification could lead to a dangerous outcome for customers.
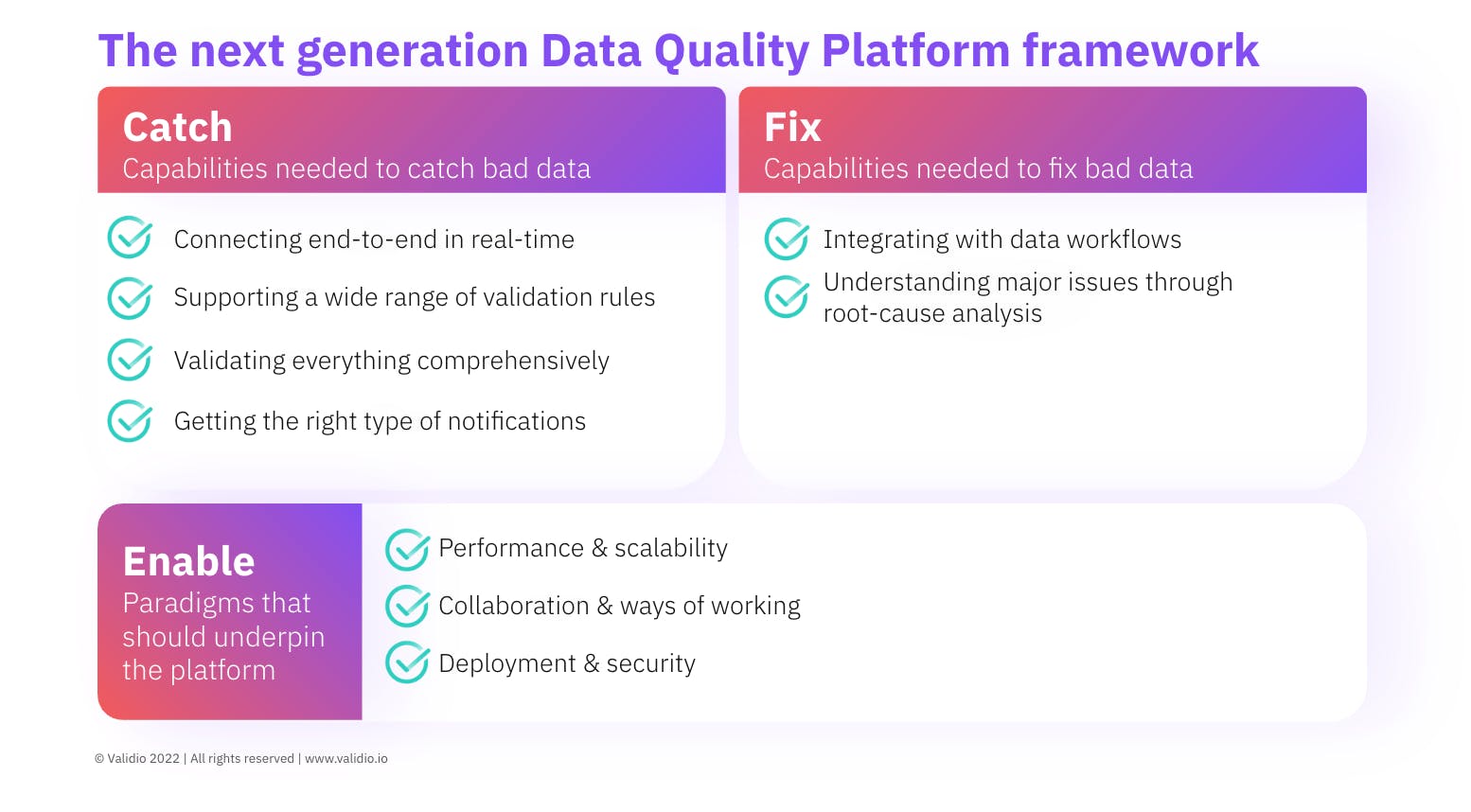
Conclusion
Most of us are familiar with some type of data quality platform, whether it’s internal or an enterprise solution. What type of granularities does your platform support? Can it only operate in the data warehouse or can it go more upstream, all the way to the raw data itself? To truly capture your data in motion, it’s important to be able to support that upwards movement.
A special thanks to Validio for all of these thoughts on what’s needed in a proper DQP. Stay tuned for more posts as I continue to break down their whitepaper on the next generation DQP.