A simple business scenario
To illustrate Validio’s capabilities, we’ll use a simple business scenario.
OmniShop, a fictional e-commerce company, has a data team of three data engineers. They provide data for sales reporting and other use cases that rely heavily on accurate data, such as recommendation engines and other machine learning applications.
In this scenario, we’ll follow one of the data engineers, Ruby, who spends at least half of her time firefighting bad data and debugging pipelines. The frequency of data failures has started to erode the company’s trust in data, and by extension, the company’s trust in the data team.
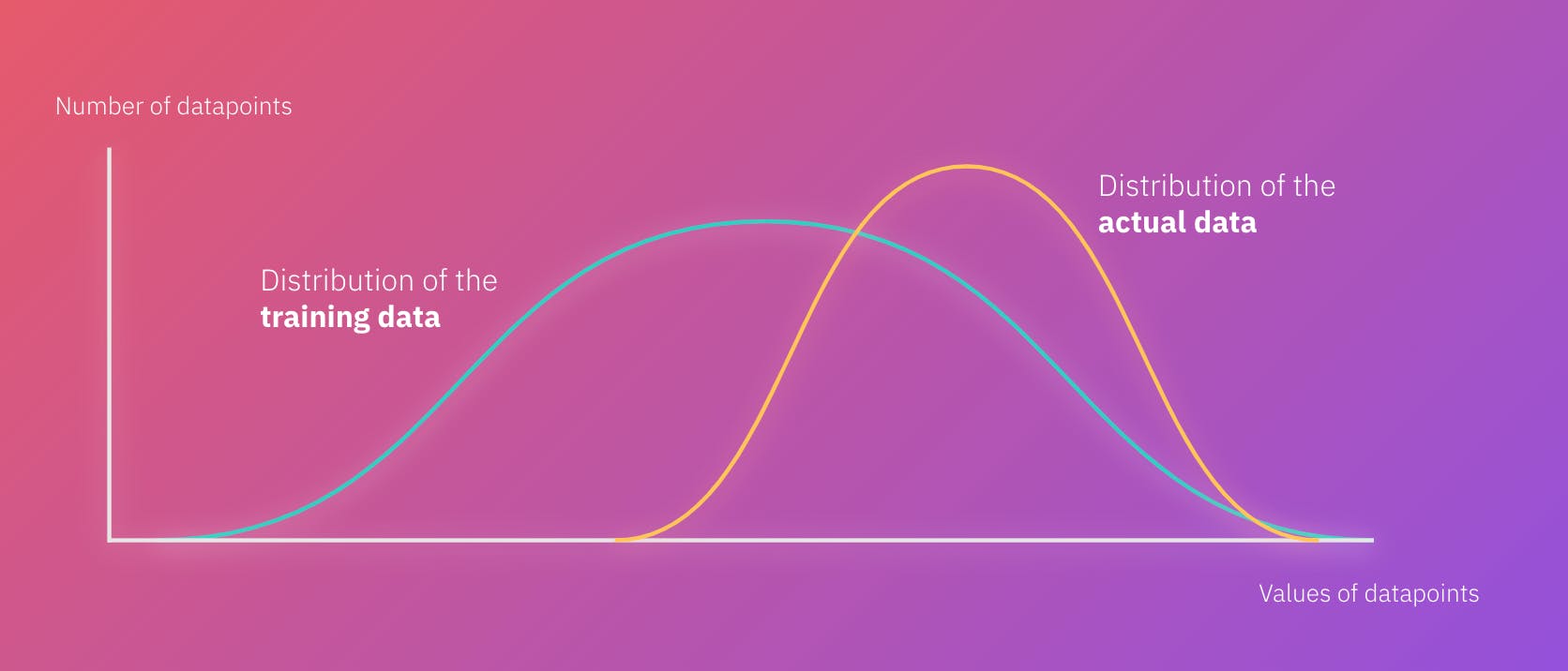
Up until now, Ruby has been manually writing data quality checks for their Snowflake tables using dbt and its extension packages, including dbt_expectations. Because the testing possibilities in dbt_expectations are limited, Ruby has also written custom data quality tests in SQL. However, since the company has grown significantly lately, so has its number of data sources and transformations in Snowflake. With more data sources comes more business logic—manual tests simply don’t scale.
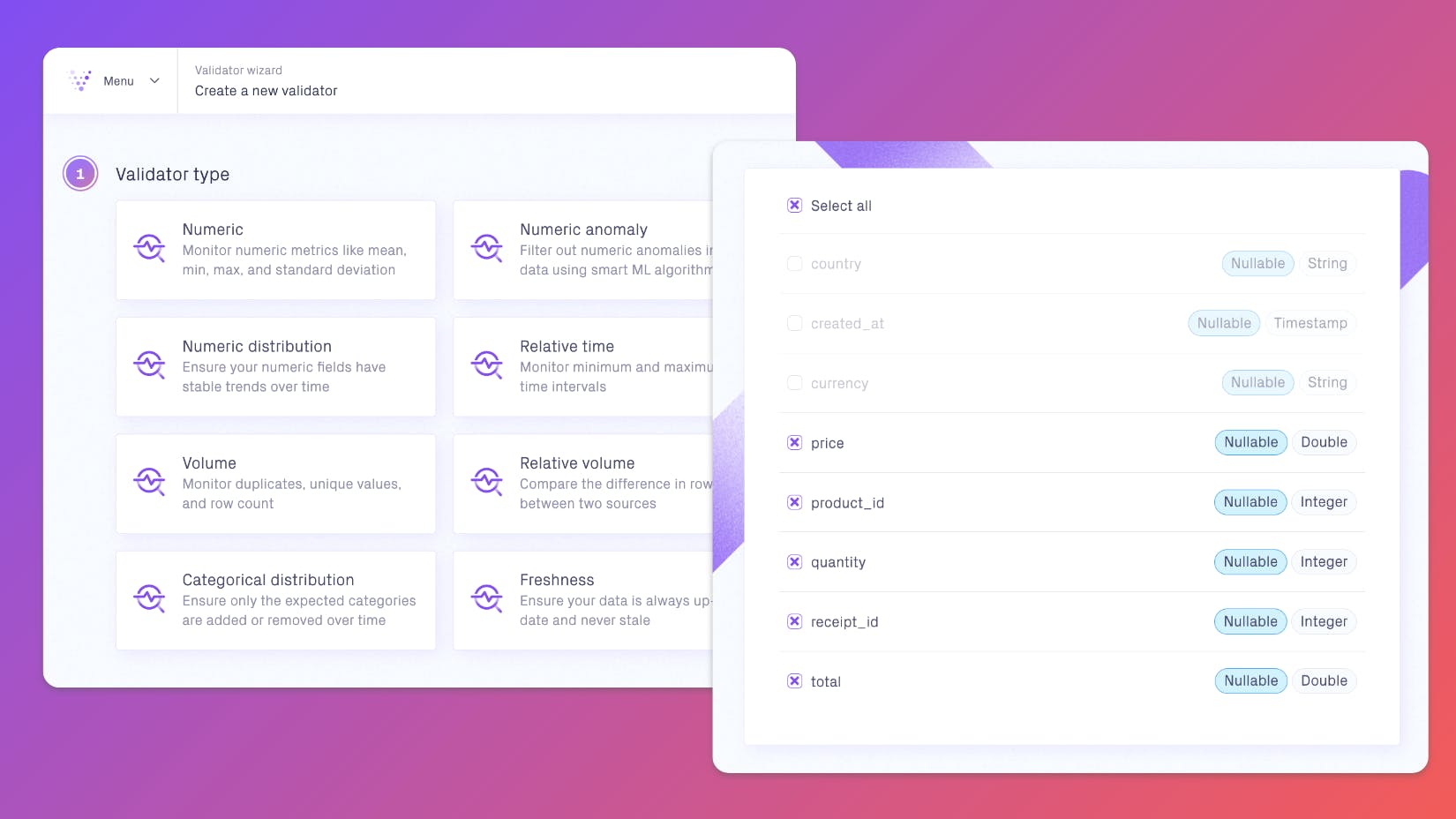
To combat this, Ruby and her team have decided to implement the Deep Data Observability platform Validio. By achieving full visibility into their data pipelines, they hope to regain control of their data quality even as the organization grows.
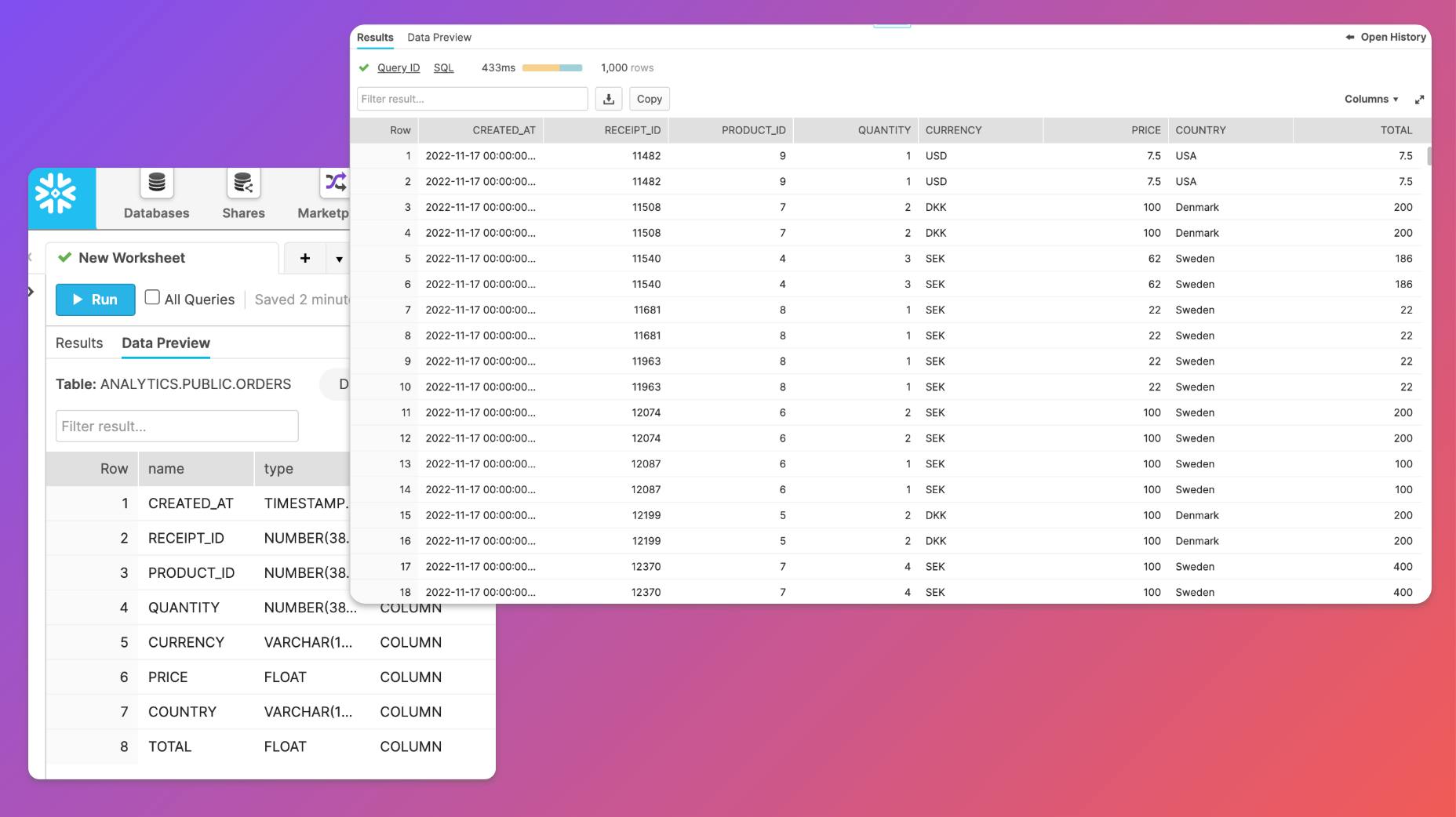
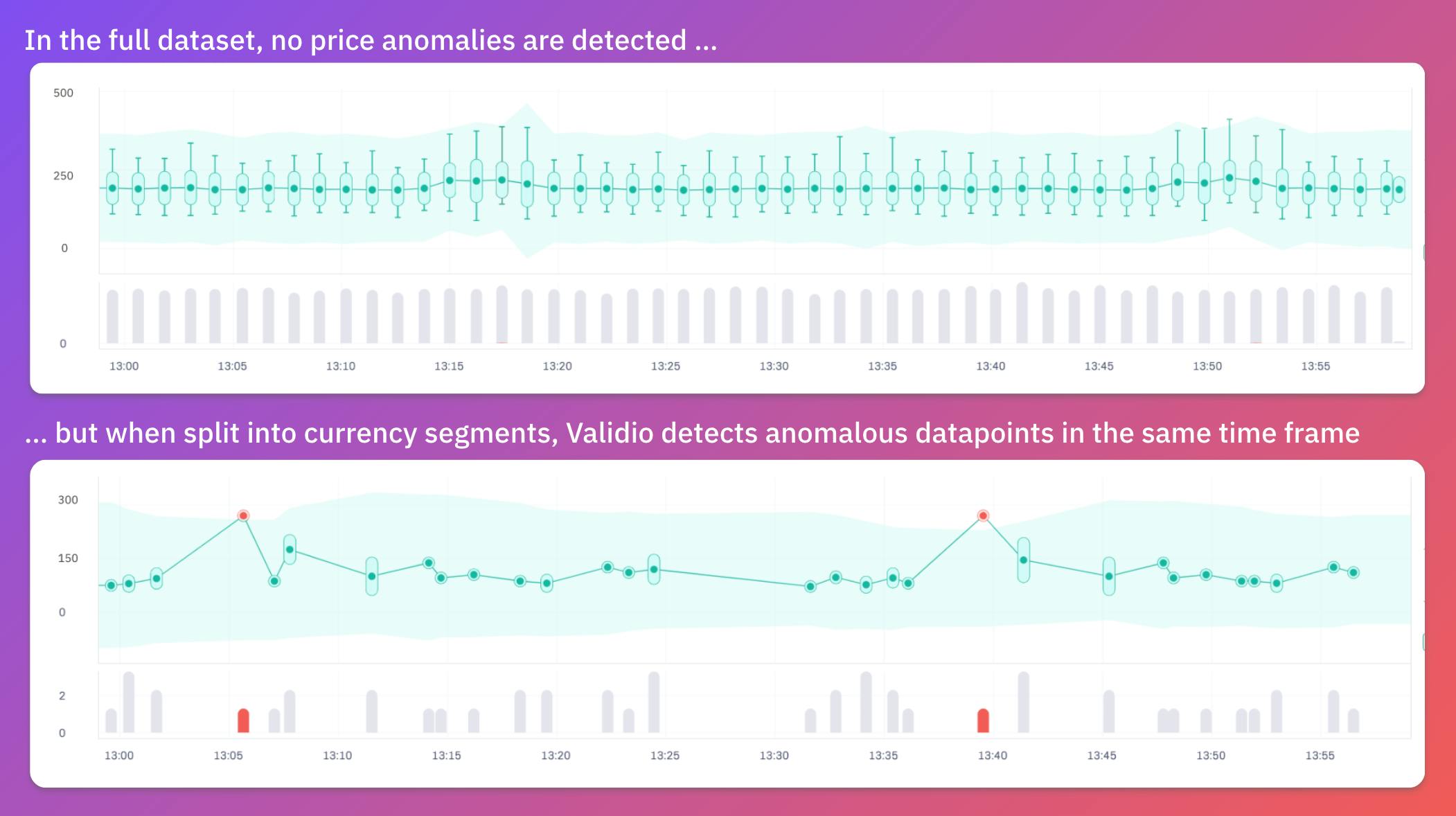
Ruby will start with their most critical dataset, which contains sales data for all orders made in each country’s webshop.