Validator configuration: Automatically suggested as well as manually configured
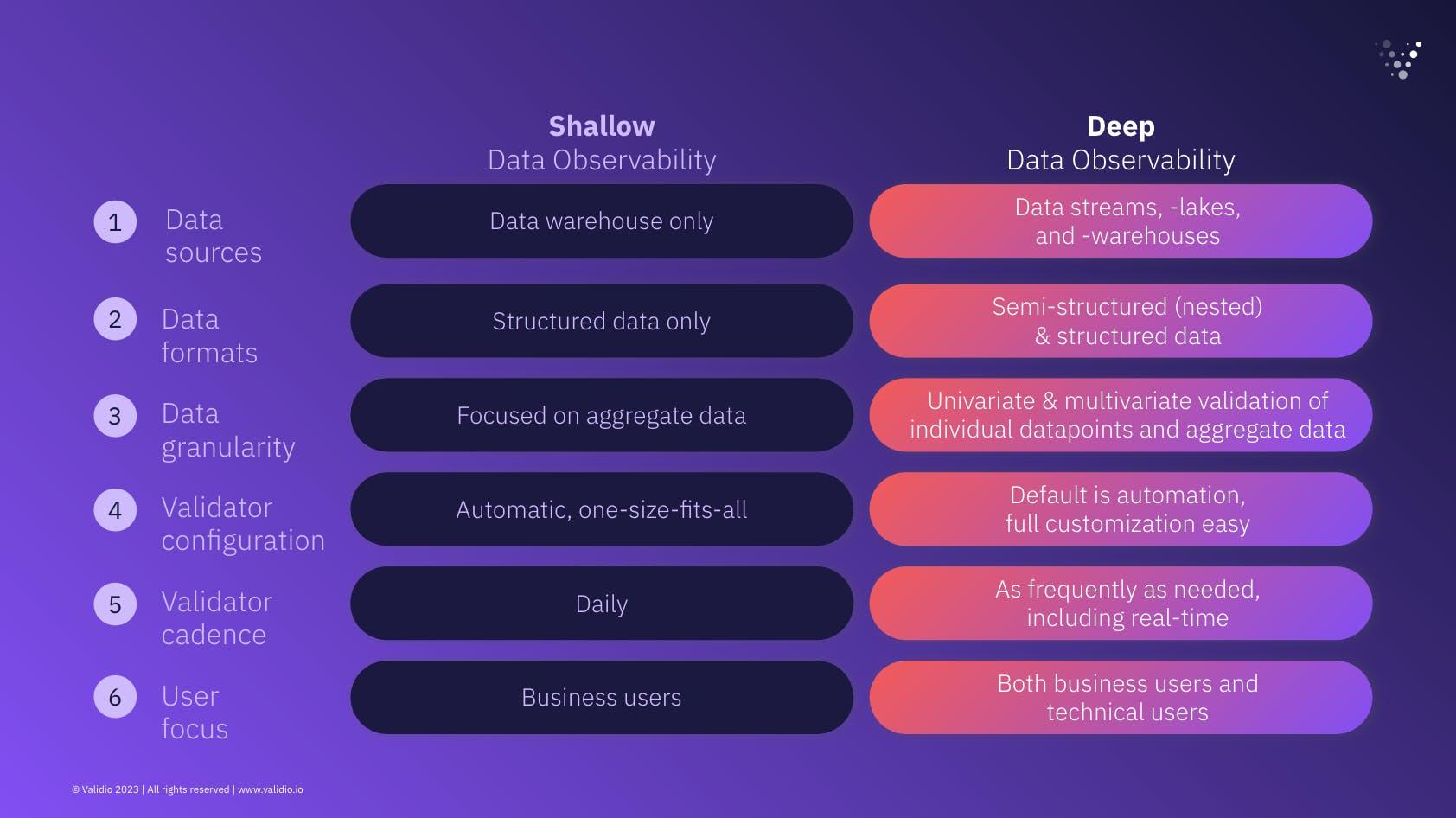
Depending on your organization, you might be looking for various degrees of scalability in your data systems. If you’re looking for a “set it and forget it” type of solution that alerts you whenever something out of the ordinary happens, then Shallow Data Observability is what you’re after; you will get a bird’s eye view of e.g. all tables in your data warehouse and whether they behave as expected.
Conversely, your business might have unique business logic, or custom validation rules you’ll want to set up. The degree to which you’re able to do this custom setup in a scalable way determines the degree to which you have Deep Data Observability. If each custom rule requires a data engineer to write SQL, you’re looking at a not-so-scalable setup, and it will be very challenging to reach the state of Deep Data Observability. Instead, if you have a quick-to-implement menu of validators that can be combined in a tailored way to suit your business, then Deep Data Observability is within reach. Setting up customized validators should not be reserved for code-savvy data team members only.
Multi-cadence validation: As frequently as needed, including real-time
Again, depending on your business needs, you might have different requirements for Data Observability on various time horizons. If you use a standard type of setup where data is loaded into your warehouse every day, then Shallow Data Observability, which only supports a standard daily cadence, fulfills your needs.
Instead, if your data infrastructure is more complex with some sources being updated in real-time, some daily, and others less frequently, you will need support to validate data with all of these cadences. This multi-cadence need is especially true for companies relying on any kind of data for rapid decision making or real-time product features, e.g. dynamic pricing, any IoT-applications, retail businesses who rely heavily on digital marketing, etc. A Deep Data Observability platform has full support for validating data for all these use cases. It ensures that you get insights into your data at the right time according to your business context. It also means that you can act on bad data right when it occurs, and before it hits your downstream use cases.
User focus: both technical and non-technical
Data quality is an inherently cross-functional problem, which is part of the reason why it can be so challenging to solve. The person who knows what “good” data looks like in a CRM dataset might be a sales person with their boots on the ground in sales calls. Thus, the person that moves (or ingests) data from the CRM system into the data warehouse might have no insight into this at all, and might naturally be more concerned with whether the data pipelines ran as scheduled.
Shallow Data Observability solutions primarily cater to one single user group. They either focus on the data engineer, who cares mostly about the nuts and bolts of the pipelines and whether the system scales. Or, they focus on the business users, who might care mostly about dashboards and summary statistics.
Deep Data Observability is obtained when both types of users are kept in mind. In practice, this means providing multiple modes of controlling a Data Observability platform: through a command line interface and through a graphical user interface. It might also entail multiple access levels and privileges. In this way, all users can collaborate on configuring data validation, and obtain a high degree of visibility into data pipelines. This in turn effectively democratizes data quality within the whole business.
What’s next
We’ve now covered the six dimensions differentiating Shallow and Deep Data Observability. Our hope is that this report gives you two frameworks to rely on when evaluating your business needs for data quality and Data Observability tooling.
If you have comments or questions about this article, don't hesitate to contact us at hello@validio.io—data quality is our favorite topic.
You can also request a demo below to discover how Validio can help your organization reach Deep Data Observability.