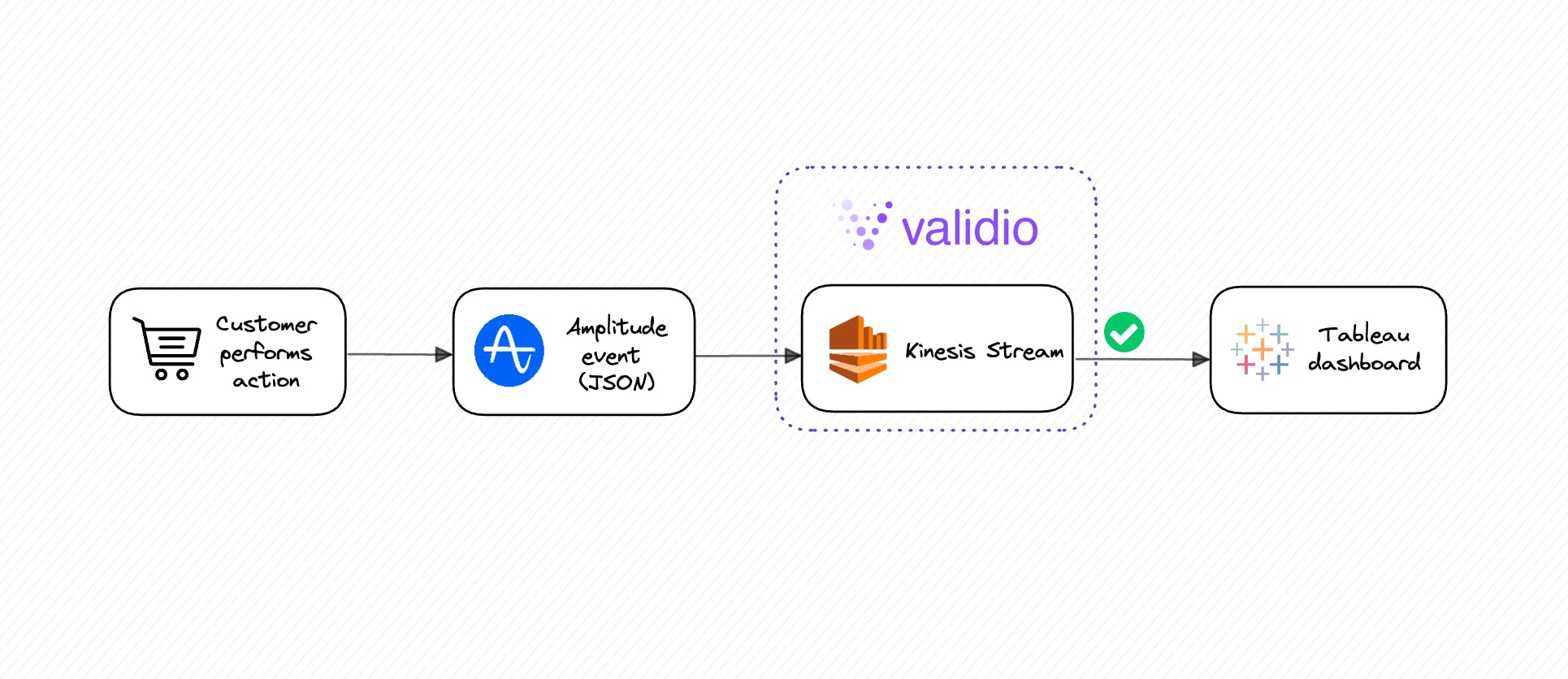
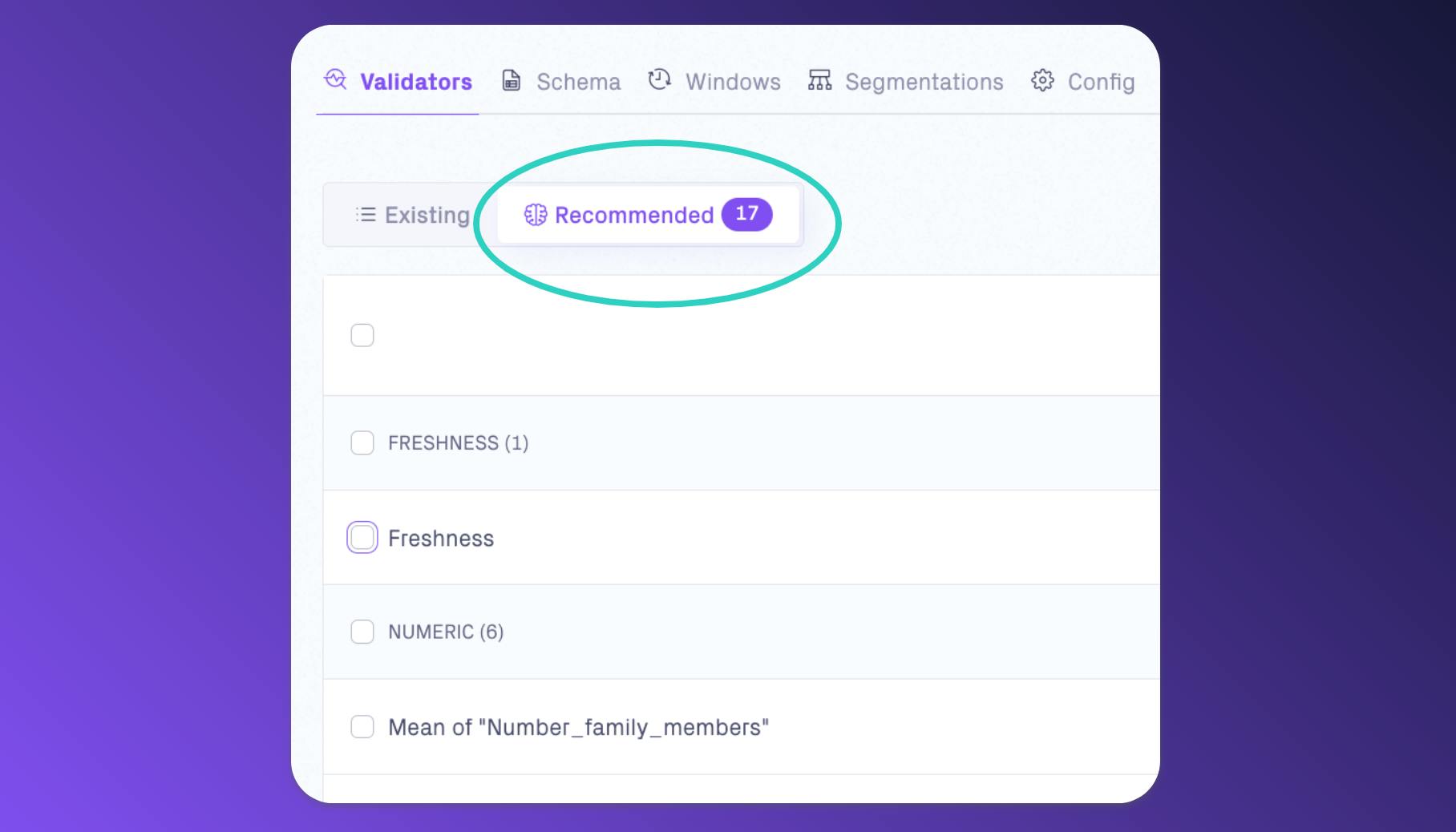
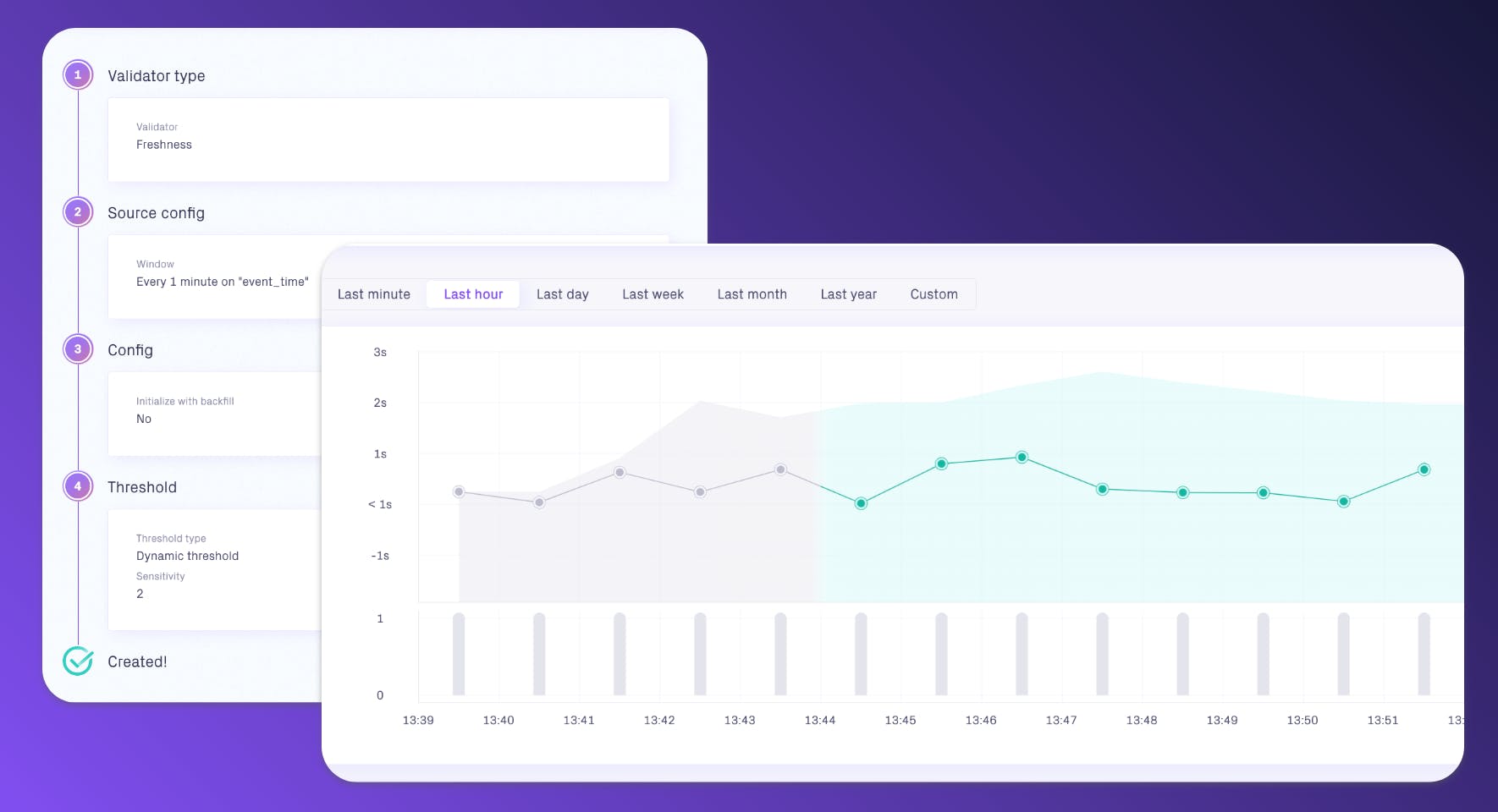
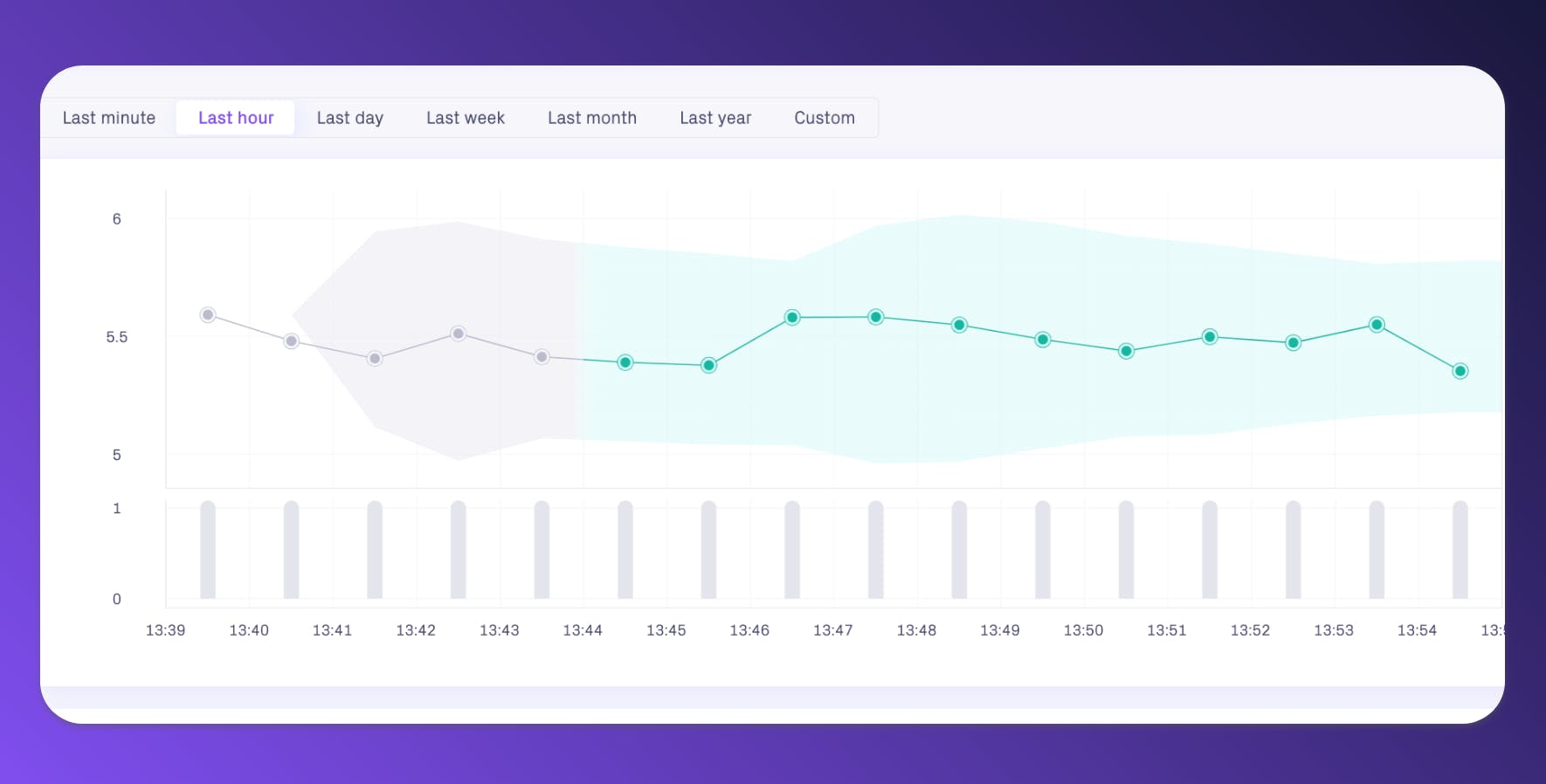
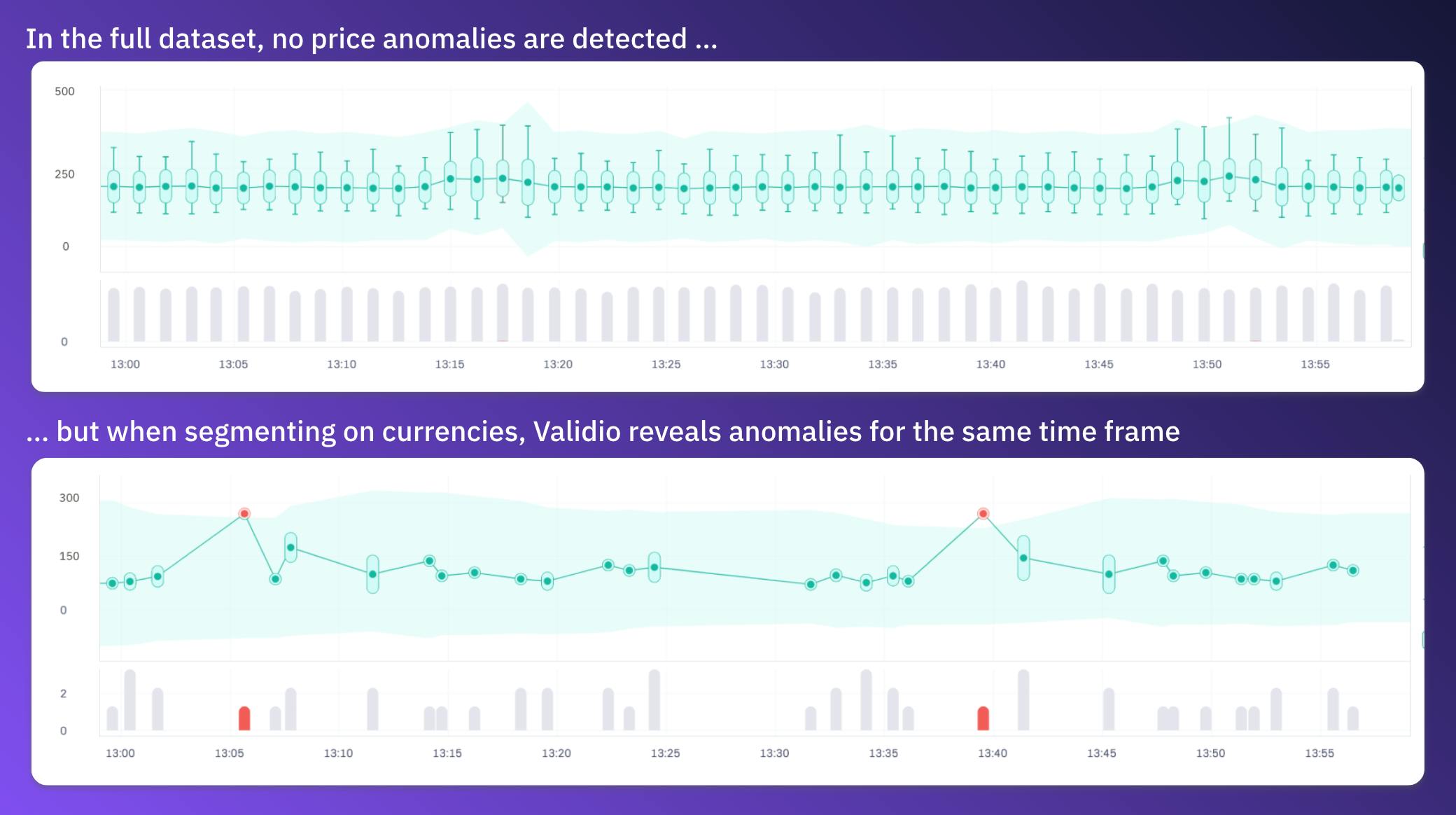
OmniShop sells a limited number of product categories, but once in a while they launch new categories or rename existing ones. In those cases, it’s important that the Tableau dashboards are modified to include new categories. Other than catching incorrect manual data entries, this setup also lets Emma know as soon as the dashboards need updating.
5. Notify users & manage issues
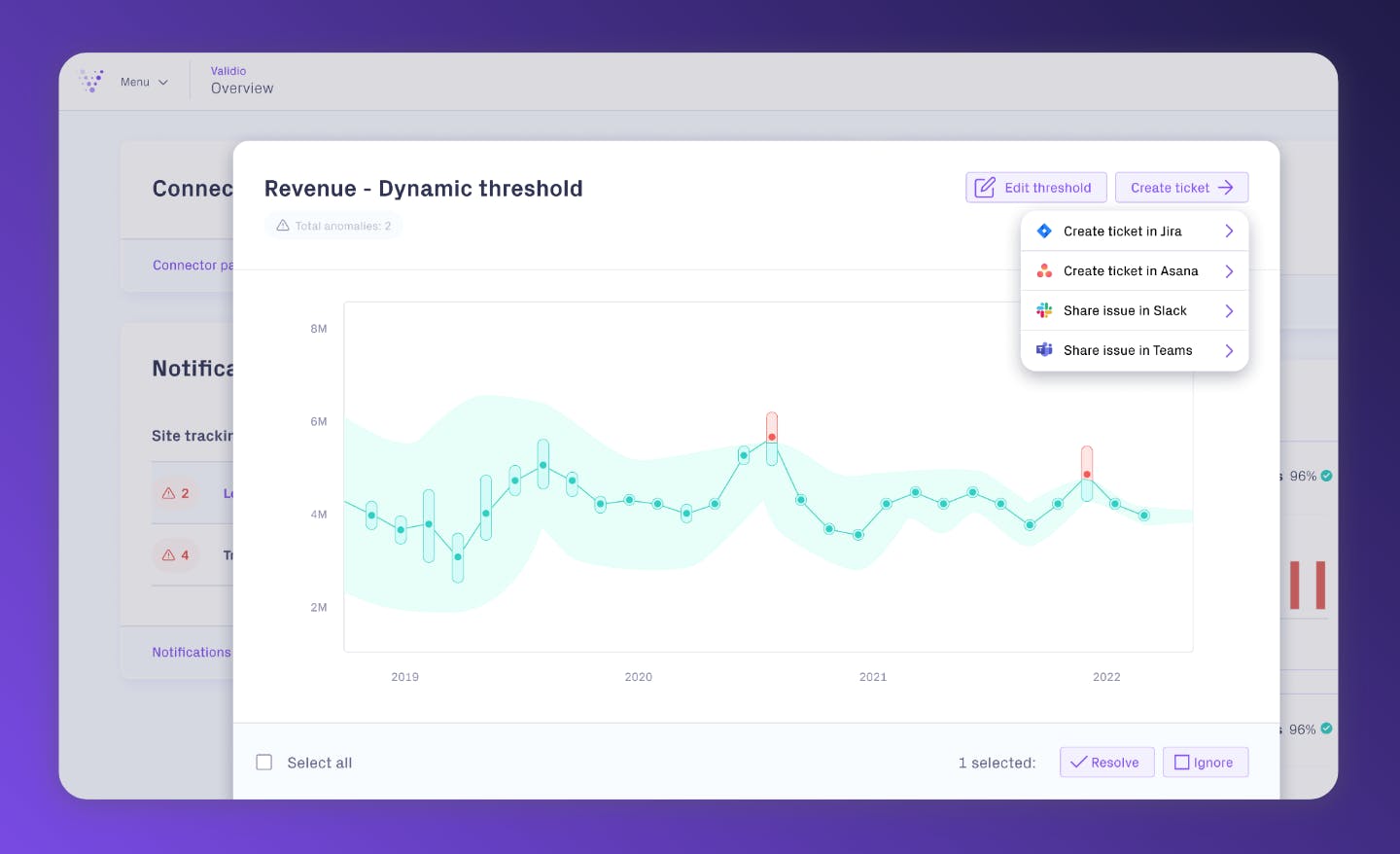
Data observability is not just about catching bad data, but also about making sure the right teams get informed at the right time.
OmniShop uses Slack for communications and Jira for issue management. Validio integrates with both these tools directly from the GUI, making it easy for Emma’s team to collaborate with others at OmniShop and track the progress of ongoing data issues.
The platform also offers a Criticality Triage functionality that lets teams collaborate and prioritize issues based on their impact. Users can edit thresholds, as well as resolve or ignore issues, depending on their level of criticality. This enables OmniShop to allocate resources effectively and address the most important issues first.