Matt Weingarten is a Senior Data Engineer who writes about his work and perspectives on the data space on his Medium blog—we highly encourage you to go check it out!
Introduction
I’m happy to be collaborating with the folks at Validio again, after a very successful series we did on data quality last year. Validio just recently put out their latest whitepaper on Deep Data Observability, and one of the key points they touched upon in that paper was the rise of different data formats and how that relates to the ongoing pursuit of full end-to-end observability.
Structured data is always nice, but it’s no longer realistic to expect that in standard data processing. As a result, we need to adapt to support different formats, from both an ingestion and an observability standpoint.
What Is Semi-Structured Data?
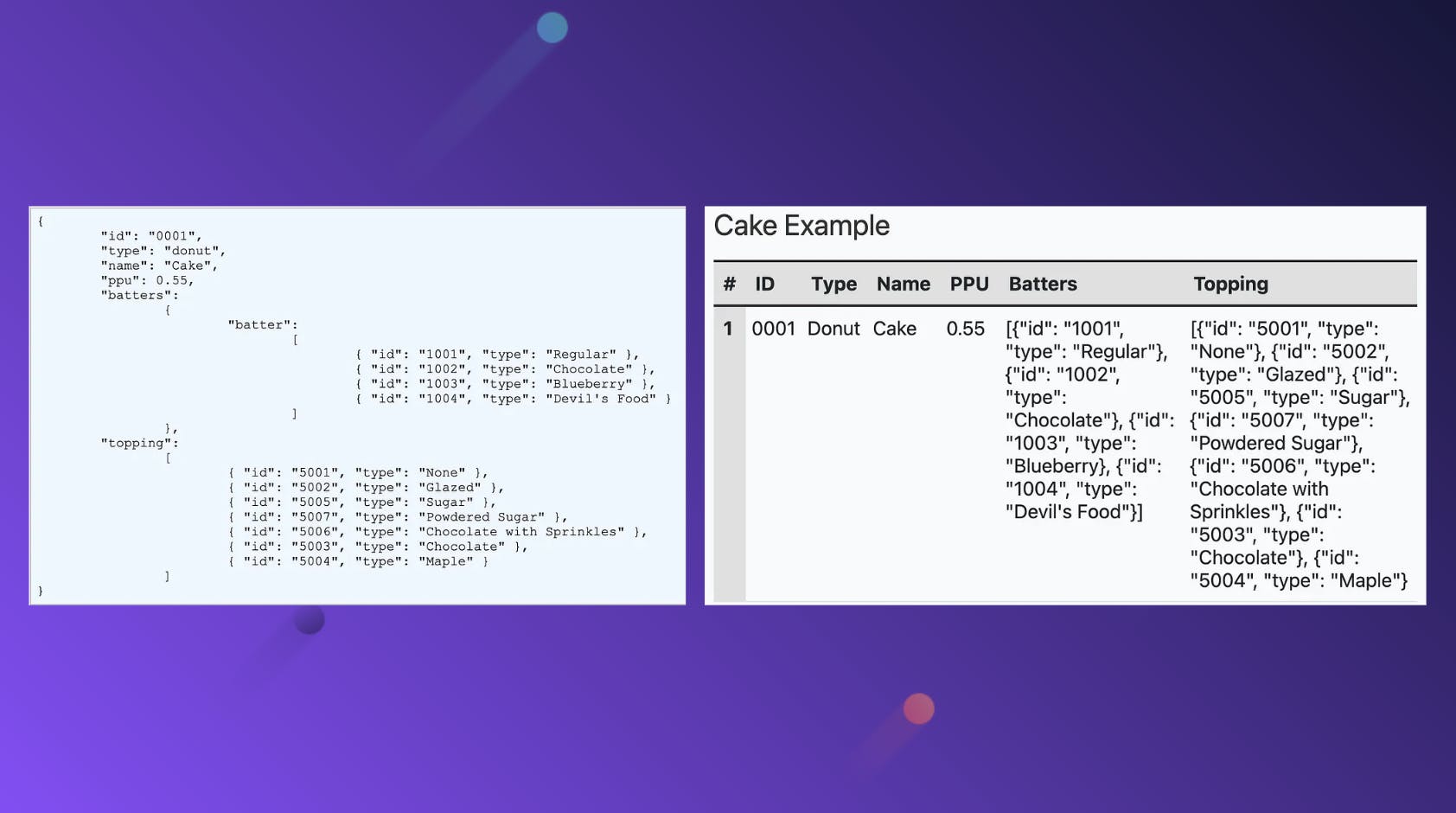
The first question you might be asking yourself is, “What is semi-structured data?” Essentially, this is data that does not strictly conform to the tabular structure we’re all familiar with in traditional databases, but it still has separators in place to identify which field is which. With the rise of APIs and other mechanisms by which more and more teams are consuming data, semi-structured is starting to become more of the norm.
One of the first projects I worked on when I joined Disney was for user preferences in ESPN (essentially, your favorite teams, sports, athletes, and more so that your feed is catered towards your favorites). The data we receive from upstream for this product is in JSON form, so I learned how to deal with semi-structured data rather quickly. Our processing in turn parses the JSON and explodes it into a more structured form, which makes it easier for our consumers to query our data.
That last point might be the biggest hindrance preventing further adoption of semi-structured data. Most data analysts or consumers don’t want to waste time with complicated SQL to retrieve data, which is why structured data is preferred. That’s also why self-serve BI that can do all of this SQL in the backend is starting to become more mainstream as well, so additional efforts aren’t needed.
The nested data structure is the de facto standard for backend applications, whereas structured data, which usually involves flattening, has been the standard in the generation of warehouse analytics, as the example below shows. That’s all changing.