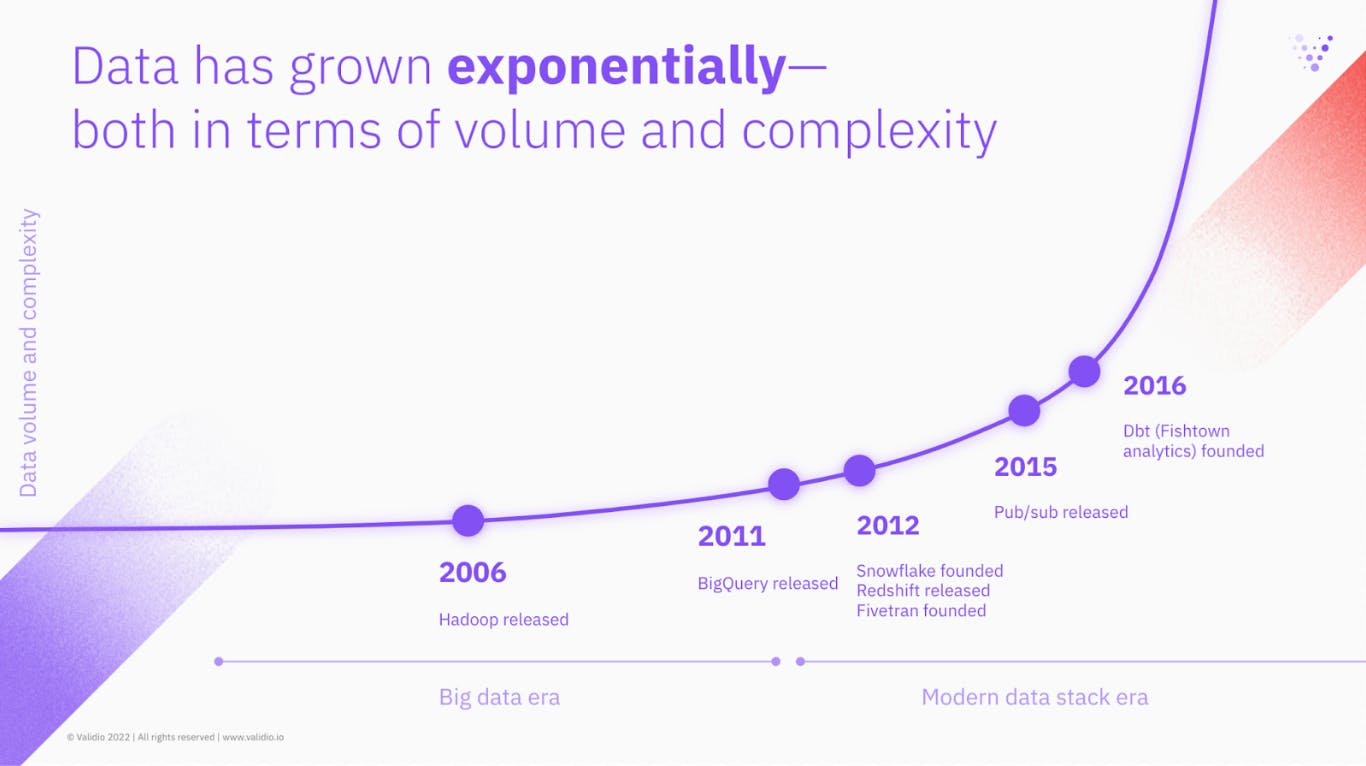
Semi-structured data formats, such as XML and JSON, are becoming more popular as they are better suited to handle streaming data. This has resulted in tools adding better support for these data formats. An example of this is Google’s recent announcement of deploying JSON support for BigQuery. In addition, these formats allow for greater flexibility in terms of schema design, making it easier to add or remove fields as needed.
The benefits and challenges of schema on read
Semi-structured data has schema on read, which is a data processing approach where you are not required to define a schema before data is stored (as opposed to schema on write). This makes it easy to both bring in new data sources and update your existing data, as any changes or updates can be applied when the data is being written. Any data that does not adhere to the schema will not be discarded when stored.
While the flexible nature of this format makes it common to store semi-structured data in data lakes, it’s also more challenging to analyze. The most basic data quality checks in the form of a schema check are not imposed by default on semi-structured data. This is why there is a growing need for automated solutions and tooling that are capable of validating semi-structured data at scale.
We have touched upon this many times—a next generation data quality platform should guarantee to catch and fix bad data wherever it appears, whether inside data warehouses, data streams or data lakes.
#2 Data contracts start to reach widespread adoption
Discussions of data contracts have been rampant this year due to the immense impact they can have in solving major data quality challenges that many teams face. A classic example of such a challenge is when unexpected schema changes take place, often caused by engineers who unknowingly trigger unexpected downstream effects, resulting in poor-quality data and frustration for all involved parties.
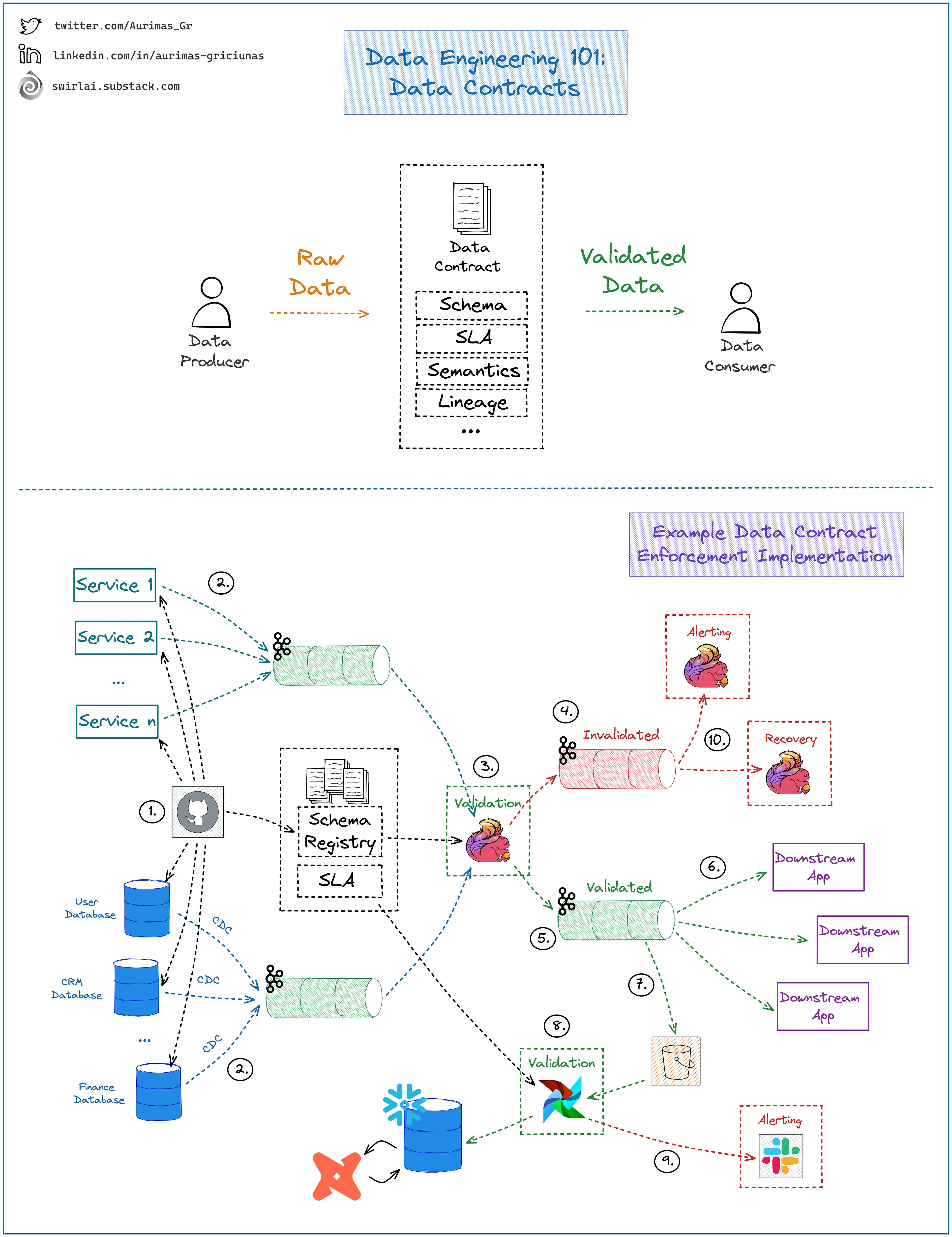
Data contracts are a way of ensuring that data is transferred between producers and consumers consistently and reliably. By specifying the format and structure as well as other SLAs and agreements about the data in advance, data contracts can help to prevent errors and data loss during transmission.
While progress is being made through data contract advocates like Chad Sanderson and Aurimas Griciūnas, the framework is still very much in its infancy. However, we think we’ll see more widespread adoption of data contracts during 2023. We had a chance to chat with Aurimas, who had this to say on the topic:
"Data quality is one of the fundamental pillars for successful data product delivery. Thanks to the community, data contracts are now positioned to launch as a key topic for 2023. Adoption of the concept will be the determining factor for those who can deliver data products at scale versus those who struggle to keep up."
Aurimas is the author of SwirlAI—a newsletter about Data Engineering, Machine Learning, and MLOps. He recently shared this explanatory illustration of how a data contract can work in practice, which we think deserves a second look here: