



Why talk about data mesh and data quality together?
In my years as a data engineer and a data product manager, I used to think a lot about the challenge of making better use of data in an organization. Consequently, I’ve been following the data mesh topic closely during the last year or so, since it’s pretty much an approach to solve that challenge. I wrote this post as a sort of pre-read if you’re thinking about implementing data mesh. Hopefully, it will serve to highlight the importance of first securing a data quality solution that can support such an implementation. So before we jump into the details of data mesh, let’s start by describing data quality.
What is “good” data quality?
The quality of data is rarely inherently good or bad. Data quality will usually depend on its context, and any irregularities in the data will also vary in significance. That’s why you will benefit from having tools in place that will automatically detect any such irregularities as soon as they happen, and validate if they are significant or not for their context. And since it’s not always possible to go “back in time” to rectify wrongful data, you want data monitoring and validation in place before bad data flows downstream to your domains and data consumers. That way the potential impact of bad data is drastically reduced.
Data mesh–what is it really?
Similar to why organizations need a comprehensive data quality solution, I view data mesh as a framework designed to enable more reliable, efficient, and scalable use of an organization’s data. The data mesh framework rests on four principle ideas, which we’ll revisit shortly, and all of these ideas demand trustworthy data–something you cannot have unless you have measures in place to validate that trust. Thus, a comprehensive solution for monitoring and validating data quality should be at the center of your data architecture, regardless if you’re pursuing data mesh or not.
The mesh is not for everyone
Before we go all-in data mesh, it should be noted that implementing a data mesh is certainly not suitable for every data-driven organization. There are many factors to consider, such as scale, work culture and technical maturity. However, if you are considering making the move it would be healthy to start by reading 10 reasons why you are not ready to adopt data mesh, authored by Thinh Ha, Strategic Cloud Engineer at Google.
Principles of data mesh
Now that the disclaimer is out of the way, let’s take a look at the four core principles of the data mesh. I will dive into each one and discuss them from a data quality perspective, based on my experiences as a data engineer.
Below is an image that illustrates the four principles and how they interconnect on vertical and horizontal levels:
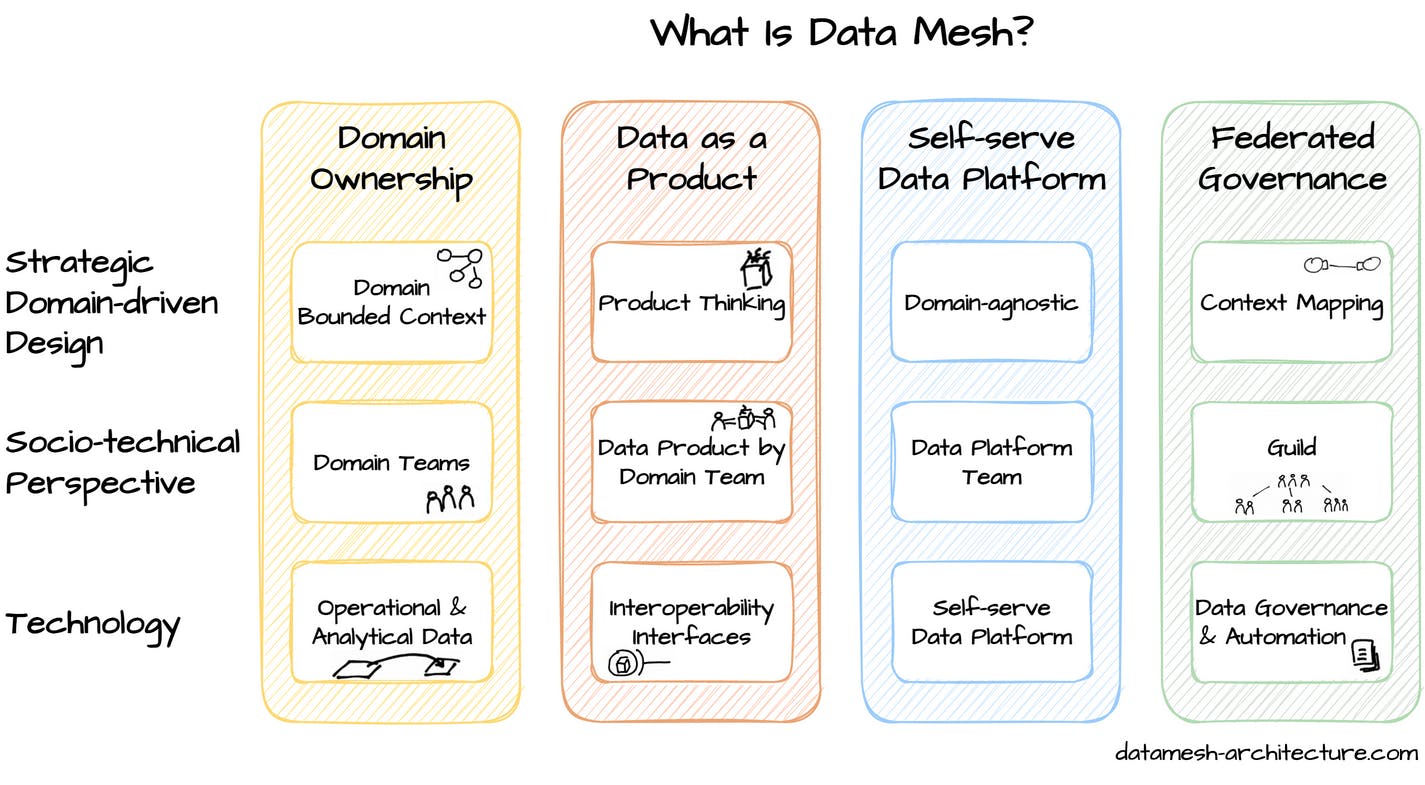
1. Decentralize domain ownership
The first principle is to move data ownership closer to the domain teams, who know the business context for their data better than a centralized data team would. Let’s say we have a customer success team, a domain team, who knows that customers with null values in a customer_address column refer to test accounts with made up financial numbers. The domain team can then configure late-stage data pipelines to exclude any values from such accounts, avoiding impact on downstream applications that consume this data. A centralized data team, on the other hand, might have been unaware of the test account indicator, letting the inaccurate numbers flow uninterrupted into sales dashboards, eventually impacting revenue forecasts and budget calculations.
So distributing ownership of data quality to domain teams enables them to take responsibility and control of the data they know best, while reducing the need for engineering time (i.e. money) to troubleshoot data issues. In turn, the no-longer-centralized data engineers and analysts will have more space to pursue higher-value activities.
Decentralized control over data can greatly improve data quality over time, enabling companies to be more resilient to constant changes as the business grows. However, without central ownership over data, there are some emergent risks involved. The rest of the three data mesh principles aim to mitigate such risks and fortify the scalability of the data organization.
2. Treat data as a product
According to Zhamak, it is key that:
“Domain data teams must apply product thinking [...] to the datasets that they provide; considering their data assets as their products and the rest of the organization’s data scientists, ML and data engineers as their customers.”
In product development, there is a design process called Product Thinking, which basically centers around the question “What makes your product useful to your users?”. Treating data as a product helps you identify what the user problems are and how your data product solves them. In this context, everyone consuming your data are considered your users.

“Data as a product” is about making sure your data has certain capabilities, including discoverability, security, understandability and reliability. All of these will ultimately make your data products more useful to your customers. That’s why it’s important to catch any issues in the data as early as possible, without risking bad data to flow downstream to the user domains. The further away from the data source an issue in data quality is discovered, the potential impact grows exponentially.
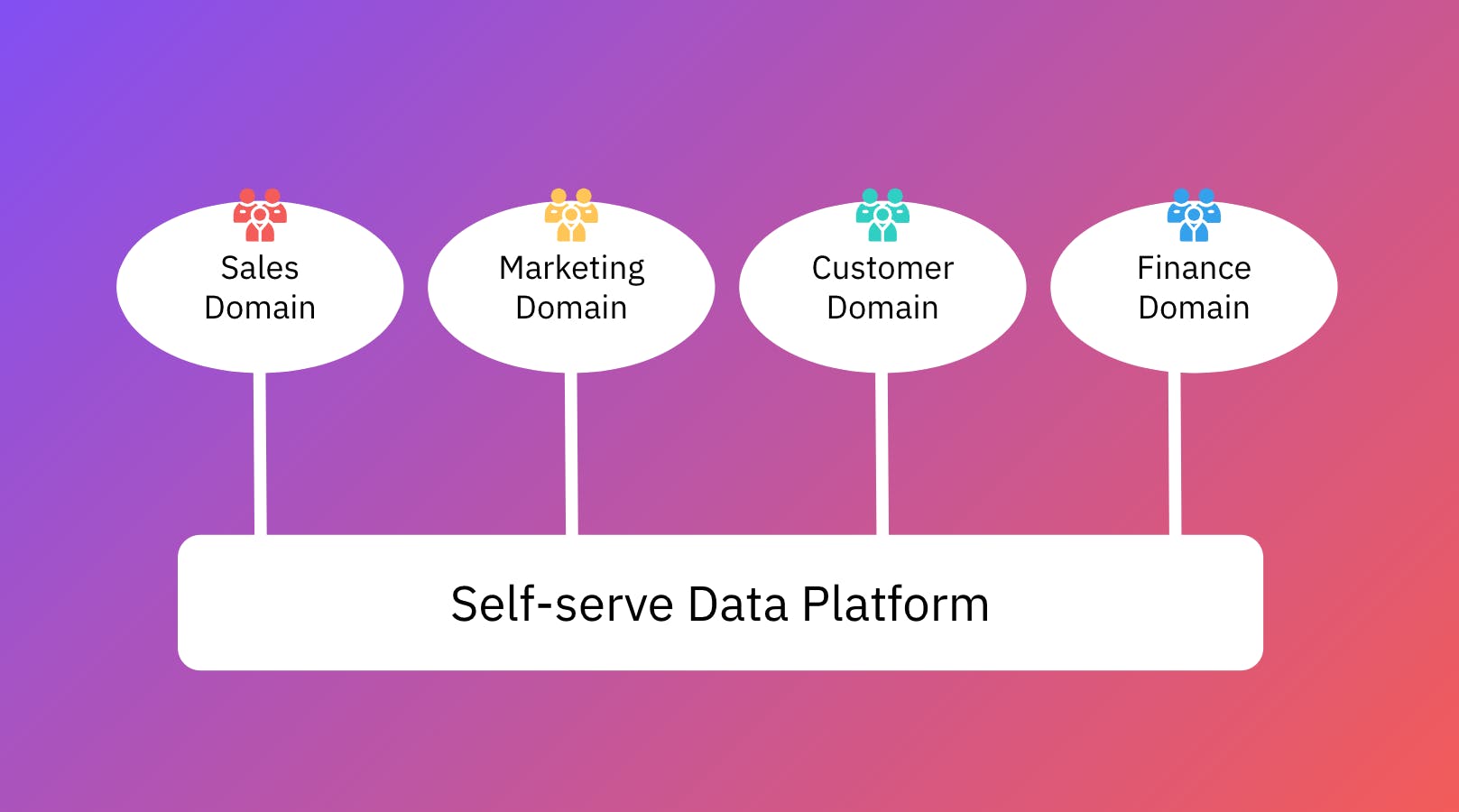
3. Self-serve data infrastructure platform
This third principle revolves around having a domain-agnostic place for your different teams to serve themselves with the data they need. A dedicated data platform team will provide these domain teams with solutions to access the data in a readily available format, but the ingestion, cleansing, and aggregation of the data for domain-specific consumption will be managed inside the domains.
This means you will have domain-oriented ETL/ELT pipelines. As such, the data quality is no longer just a centralized responsibility, but instead shared with the domain teams.
After all, data quality is always context-dependent and the domain teams will best know the business context of the data. From a data quality perspective, data mesh makes good sense as it allows data quality to be defined in a context-specific way–for example, the same data point can be considered “good” for one team but “bad” for another, depending on the context. As an example, let’s take a subscription price column with a fair amount of anomalies in it. Team A is working on cost optimization while Team B is working on churn prediction. As such, price anomalies will be more of an important data quality issue for Team B than for Team A.
To make it easier to facilitate ownership between data products (which can be database tables, views, streams, CSV files, visualization dashboards, etc.), the data mesh framework suggests each product should have a Service Level Objective. This will act as a data contract, to establish and enforce the quality of the data it provides: timeliness, error rates, data types, etc.
Automated data validation and alerts is a great way of enforcing data contracts, and should be key elements of a comprehensive data quality solution.
4. Federated governance
Possibly the least exciting term in the data universe, but data governance is essential to have interoperability between data products through standardization. The goal here is to create an efficient data ecosystem adhering to organizational rules and industry regulations.
Keep in mind that data governance is not about having a command-and-control approach to enforce compliance. Instead, the goal is to enable security and privacy for your users, while also granting you a competitive advantage in the market. By making compliant data easier to access, you also enable your teams to make faster decisions and drive operational efficiency at scale. We wrote a post on this topic a while back, looking into how Sweden’s #1 online grocery store pseudonymizes PII in streaming data to comply with regulations while maintaining data integrity.
In order to confidently make data-driven decisions that will drive business value you must be able to rely on your data, which you are unable to do unless you have solutions in place to validate that your data is correct.
Ok, data quality before data mesh–now what?
In my opening paragraph, I mentioned the importance of having a comprehensive solution in place for monitoring and validating data quality before you start pursuing a data mesh strategy. Let’s wrap this up by discussing the two options to achieve such a solution:
Option 1: Build and maintain these data quality solutions in-house.
This can be a viable option if you’re running a small-scale business with few varying business contexts for data. Then you only need to make sure your engineers have the technical maturity to confidently build it, and that your business and data use cases don't scale. Of course, it can also be a viable option for large data-intensive enterprises as long as you possess the engineering resources of Airbnb or Netflix.
Option 2: Leverage external data quality solutions.
At the end of the day, you probably wouldn’t build your own data lake or data warehouse, even if it's the bare minimum to leverage data. Given that, why would you build your own data quality solution? The benefits of using a commercially available data quality solution are less engineering overhead, faster time-to-implementation, and lower upfront costs. Ultimately, less worrying about system maintenance, and more focus on business and innovation. Just make sure the solution you choose will be comprehensive enough to cover the full complexity of your data. As a guide, you can think of questions such as:
- Does the solution offer comprehensive monitoring across all of your data storage locations, regardless if it's in databases, data warehouses, data lakes, or data streams?
- Can it monitor and validate different levels of your data, such as metadata, datasets, and individual datapoints?
- Does it allow for both rule-based and auto-threshold monitoring that adapts to trends and seasonality?
- Can it monitor your data in real-time for potential issues and patterns as soon as they happen?
- Does it allow for detecting data quality issues that are more complex in nature, such as multivariate features?
Closing thoughts
There you have it. Mesh or no mesh, being able to monitor and validate your data quality needs to be at the center of your data architecture. But I for one will eagerly follow the ongoing hype of data mesh in the industry to see how organizations do in their implementation efforts. I am confident there will be many success stories–as long as they give data quality the white glove treatment.
That’s it! Don't hesitate to let us know your thoughts on data mesh or what key elements to consider for a successful implementation of it.