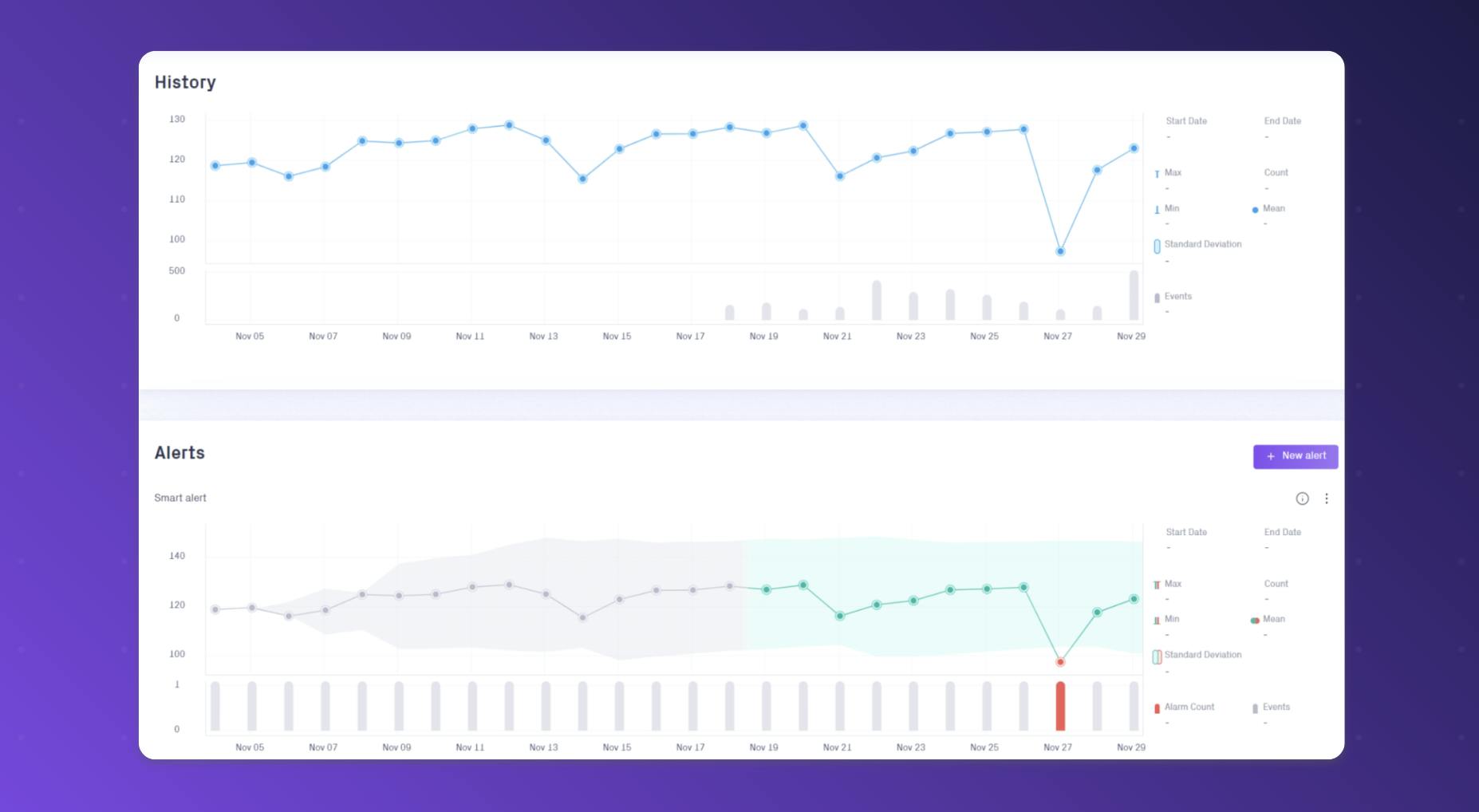
3. Reveal hidden anomalies with Dynamic Segmentation
To make sure you discover all anomalies throughout your data, Validio also offers Segmentation. This automatically splits large datasets into segments to reveal anomalies that would otherwise be hidden when only looking at the larger dataset. This helps to pinpoint the exact segment a problem surfaces in, enabling you to perform root-cause analysis much quicker.
Dynamic Segmentation is powerful not only for its ability to detect hard-to-find anomalies—it also offers immediate root-cause analysis by pinpointing what segment a problem surfaces in.
Let’s say you’re a global logistics company that tracks delivery performance in different countries. Driver data is sent in real-time as JSON events, and processed in Kafka streams. You’re monitoring the semi-structured data in Kafka to detect data quality issues as soon as they happen. By also using Dynamic Segmentation, you’re able to find much more detailed anomalies—for example per city, per tracking device, per merchant, per car type, per warehouse terminal, per parcel type, etc. Such anomalies can appear to be acceptable values if you only look at the data per country, but by monitoring each of the mentioned segments, Validio reveals that they are in fact significant anomalies.