For years, data quality focused primarily on structured data – neatly typed rows and columns in your data warehouse. But the world of data is rapidly expanding, and a significant portion of information lives in unstructured formats: images, text documents, audio files, website content, and more. The value of unstructured data has been preached for decades, but the recent success of GenAI has brought us at least one step closer to realising that value.
🚩 TABLE OF CONTENTS
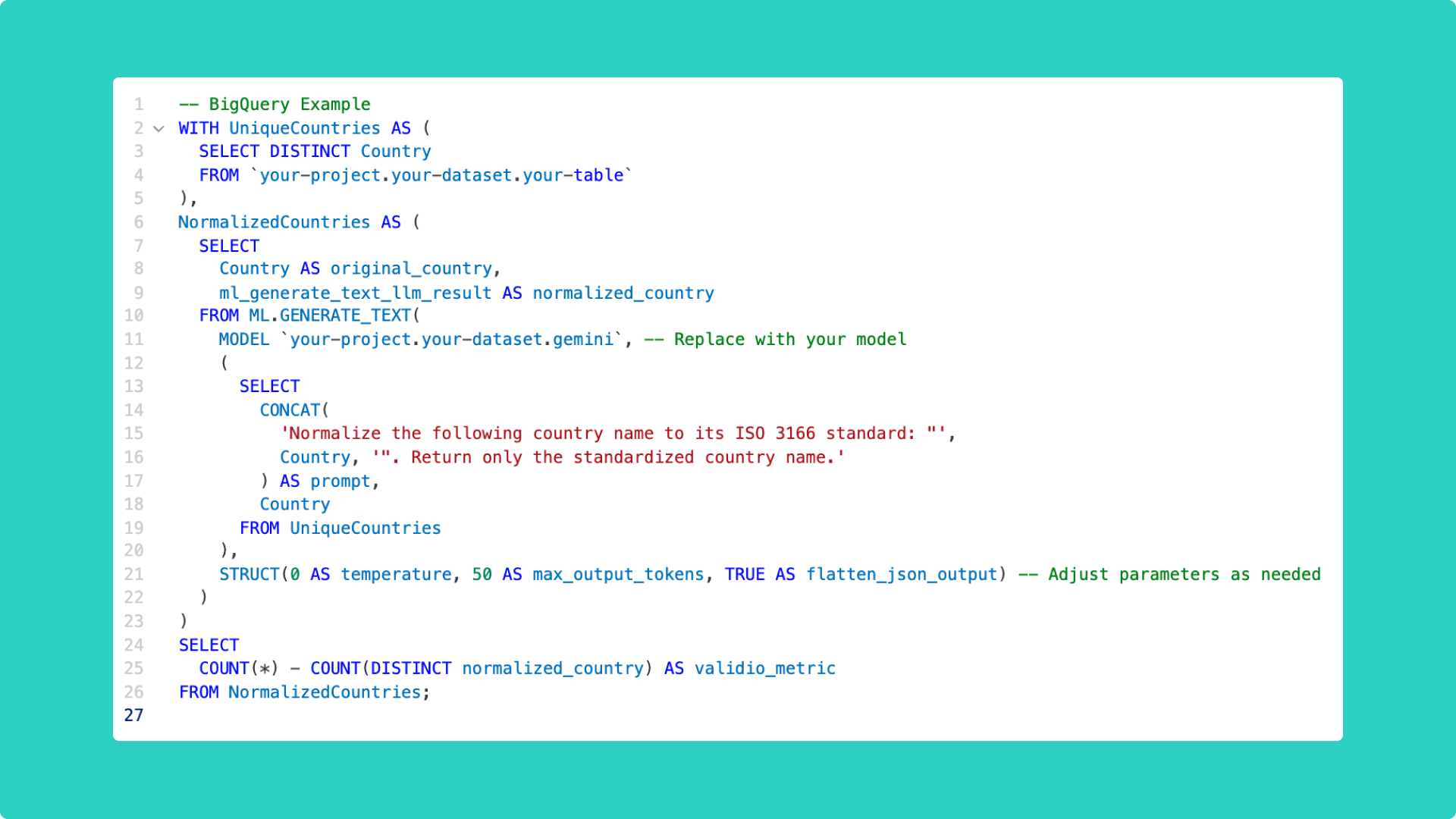
→ Example 1: Misspelled or inconsistent country names
→ More unstructured data use cases
→ Better Master Data Management
→ The future of unstructured data quality
Assessing the quality of unstructured data is difficult due to its sheer volume, variety, and lack of predefined formats. This challenge has been amplified by the recent proliferation of "AI slop" – low-quality, often inaccurate AI-generated content that degrades information systems online and within organizational data stores. Ensuring the integrity of unstructured text data is, therefore, essential not just for reliable data ops and analytics but also for maintaining trust. Hopefully, this will lead to dependable AI applications and slow the propagation of errors generated by both humans and machines.
Validio is stepping up to meet this challenge, empowering data teams and business users to validate their unstructured data by leveraging the power of Large Language Models (LLMs) securely within their existing data warehouse infrastructure. In this blog post, we share some examples of how unstructured data validation works in Validio and how you can use it for your master data or other use cases.