Ever since the advent of cloud during the early 2010s, I’ve heard business executives complain about investments into AI and described them as black holes: a lot of investments go in, but very little business value ever comes out. I’ve seen this result in a more careful mindset among business executives when it comes to everything AI during the last half a decade. However, ever since ChatGPT was introduced to the world on November 30, 2022, the mindset has shifted drastically. Now, once again, everyone is bullish on AI investments.
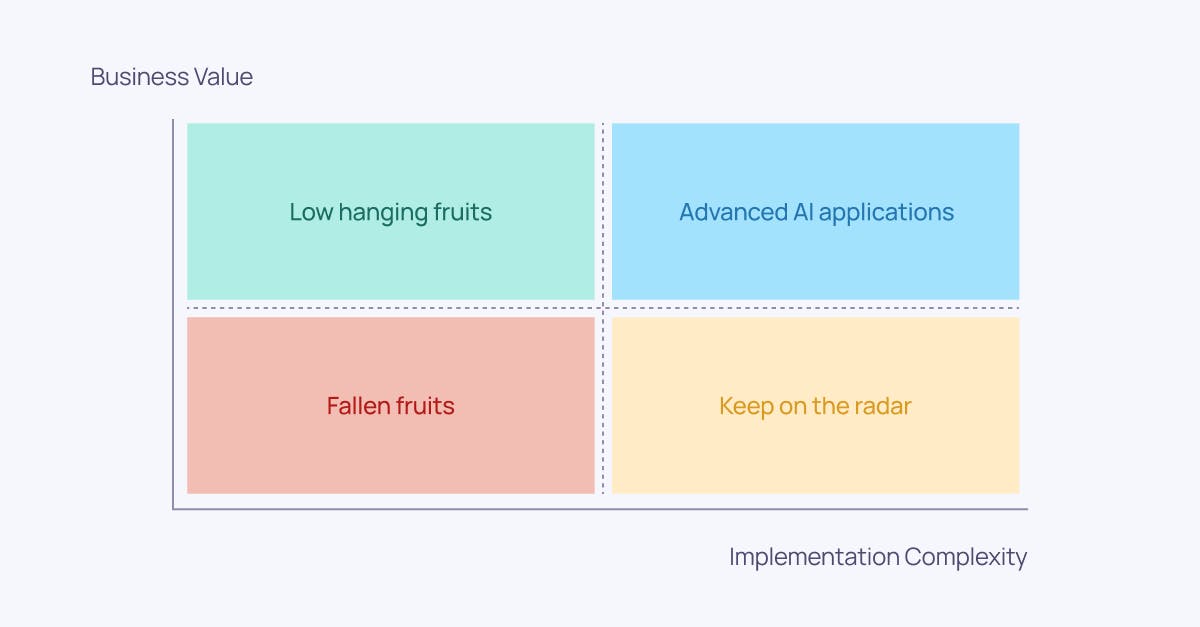
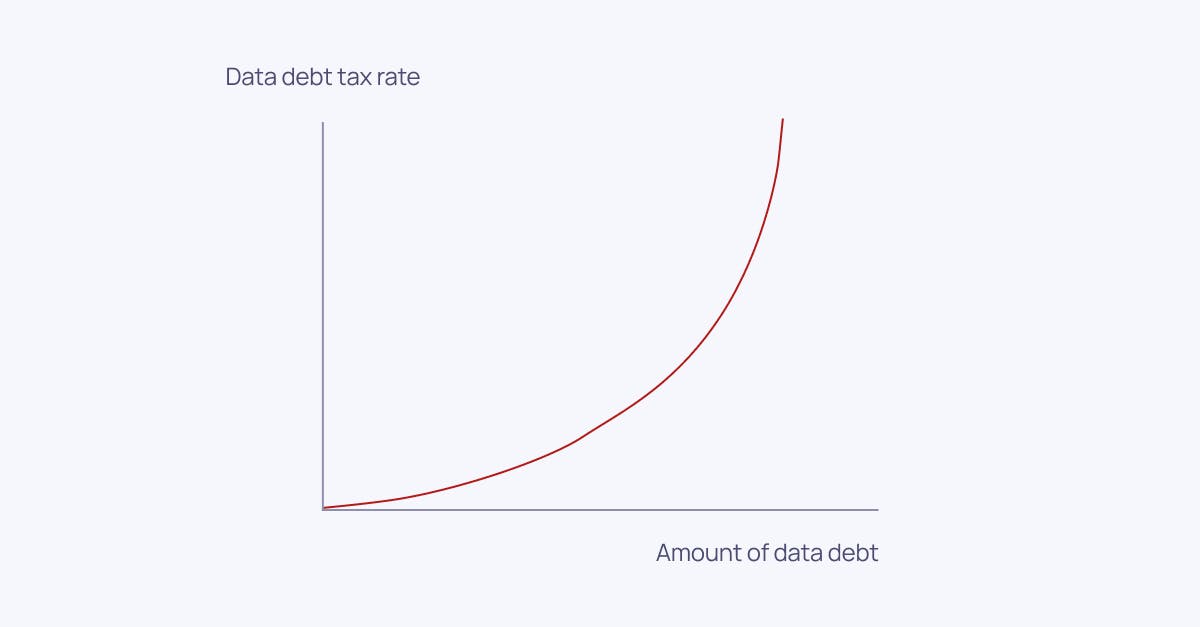
Based on conversations and collaborations with hundreds of business- and data leaders over the years, I’ve identified three success factors on how to succeed with AI investments: AI-problem fit, prioritization among AI use cases, and a clear strategy for how to manage data debt.
In this blog post, I’ll give an introduction to the three areas, but I recommend anyone who wants the deep dive to check out The Data Leader’s AI Guide.
Finding the best AI use cases—the importance of AI-problem fit
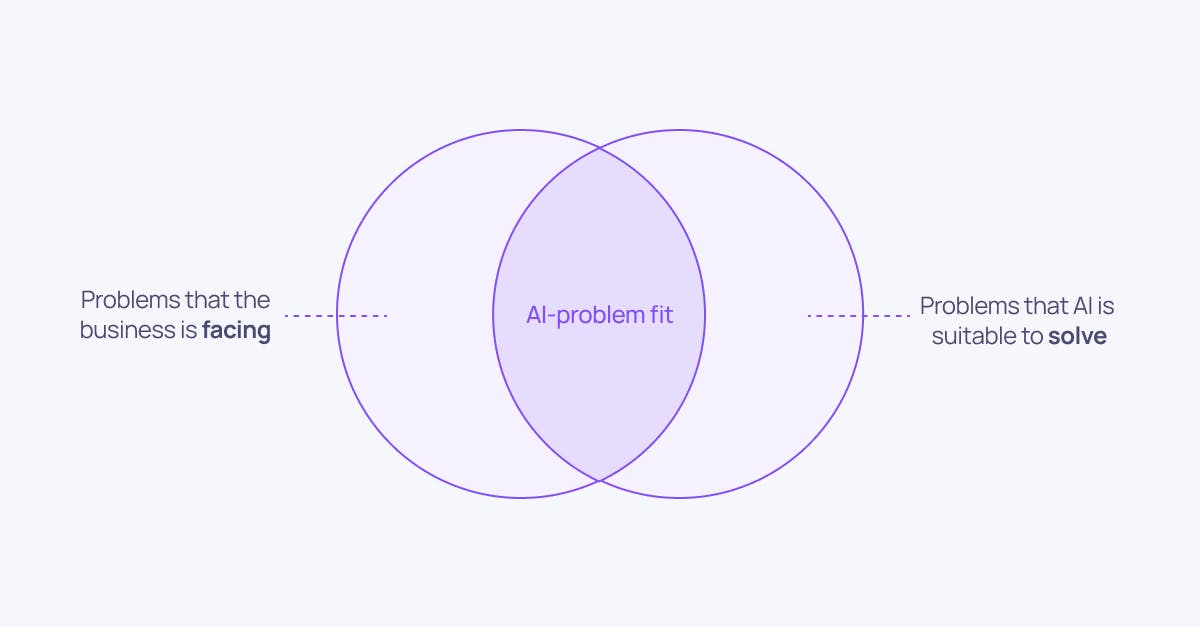
First out of the success factors is finding AI-problem fit.
Each time a new technology is hyped, people have a tendency to apply it to every imaginable problem. AI is no exception. It is not uncommon to hear top management teams mandate their teams to “implement AI”. In other words, they are requesting their teams to apply a specific solution without first specifying the problem. Ideally, the problem definition should happen first. After this, potential solutions can be decided upon. AI is a potential solution to some, but far from all, problems. As a result, AI should not be used to solve all problems.
The first step in identifying AI use cases with AI-problem fit is to specify a prioritized list of problems that the business is facing. This list of problems stems from the actual needs of the underlying business and should not be affected too much by the introduction of new technologies such as AI. The number of potential solutions to each problem on the list might be many and varied, e.g. the redesign and improvement of processes, or the integration and automation of different IT systems. Sometimes, AI turns out to be the best potential solution to a prioritized business problem. Then, and only then, is there an AI-problem fit —and the AI use case is worth looking into further.