


Following the great reception of our community initiative Heroes of Data on Substack and social media, we chose to gather the group in-person for the first time this month of June for our very first Data Engineering Meetup! Together with the tech consultancy Netlight, we hosted over 70 data practitioners from all around the Stockholm tech scene to share in an evening of learning and socializing around some pizza, beers and snacks of all kinds!

A huge thank you again to those of you who attended and made this an evening to remember. If you missed this event, make sure to sign up to our meetup group to be notified of future events!
In this article, we will summarize our interactive fireside chat, where we engaged the audience through a Mentimeter quiz! For our fireside chat, we invited two accomplished data practitioners and thought leaders from the Stockholm data community:
Rebecka Storm is the Head of Data & Analytics at Tink, a fintech company that provides APIs for banking and financial data. She previously spent 5 years at Zettle/Paypal where she started her career as a credit risk analyst and progressed to machine learning lead. She’s also the founder of Women in Data Science (AI & ML) Sweden and an active speaker and influencer in the data community.
Jacob Hagstedt Persson Suorra is an Associate Manager at Netlight, a tech consultancy headquartered in Stockholm. He has experience working as a founder and CTO as well as a lead data engineer building data infrastructure for several of Stockholms most cutting-edge startups!
In the fireside chat, we covered four main topics: measuring the impact of data engineering work, how to organize data teams within a company, favorite tools including the “build vs buy” mentality of the community as well as a meta-discussion of how we talk about data tools.
The chat was moderated by Validio’s Sara Landfors and attended by a large crowd of data practitioners from around the Stockholm data community with the most common job titles being Data Engineer, Data Scientist and Analytics Engineer.

The data community can benefit from better ways of measuring their impact
Right off the bat, the panelists and audience were asked whether they thought they had clear and relevant ways of measuring the impact of data engineering work in their current role. Overwhelmingly, the response was no. While most agree that a robust and scalable data infrastructure is a must-have for any data-driven company in 2022, its impact on the bottom line is often unclear and hard to evaluate.
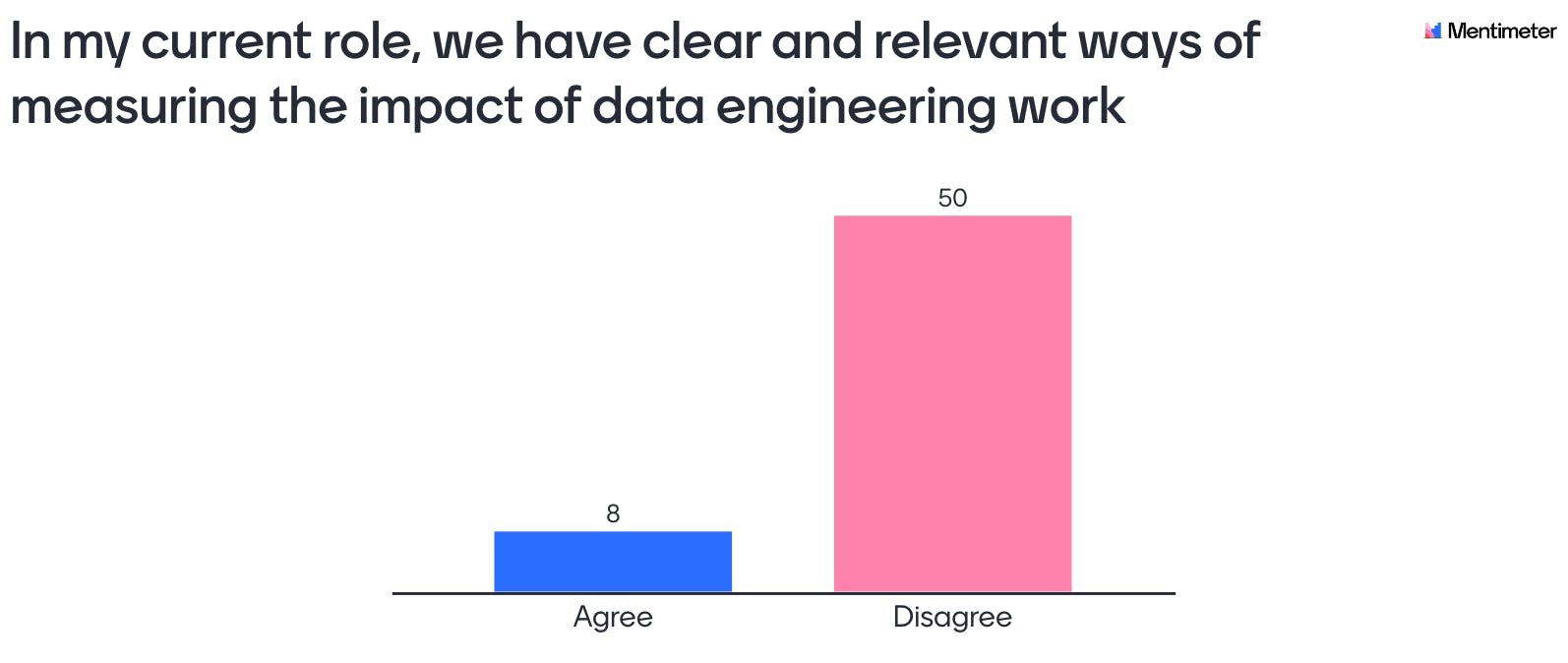
One point brought up by Rebecka is that this stems from the data engineering role being primarily a support function. Whereas a salesperson can easily be measured by the number of deals closed or a data scientist by the performance of their predictions, data engineering teams contribute to the bottom line indirectly by making other teams more productive. In supporting a software engineering team for instance, this could be measured by employing proxy metrics such as: the average time spent on a pull request or time spent developing a new ML model from proof-of-concept to production—acting as an indicator for the efficiency of the team's processes and infrastructure. Ultimately, it is up to the data engineering team in conjunction with each of their downstream consumer teams to advocate for and assess the value the data brings to them. This can mean for example, collaboratively setting up KPIs and expectations about the availability and quality of data for their specific use case.
Jacob also crucially pointed out that this type of mutual reporting, where data teams set up goals together with other teams, is actually vital for keeping data engineering teams focused. Otherwise, they risk focusing too much on output such as counting the number of tasks completed without taking into account the impact of their work on downstream data consumers and the business at large.
The data community is exploring the best ways of organizing data teams
Next, the audience was asked to choose which one they preferred between two options: centralized or decentralized (also known as embedded or distributed) data-teams? To clarify, a centralized structure is one where all data resources—both people and technology—are owned and managed by one central data team. This team then receives requests from other divisions of the company and prioritizes tasks on a company-level in the fashion of a consulting-client relationship. Decentralized teams on the other hand are embedded into each part of the organization, assigned to a specific vertical and report not to another data professional but directly to the head of that department, say Sales or HR.
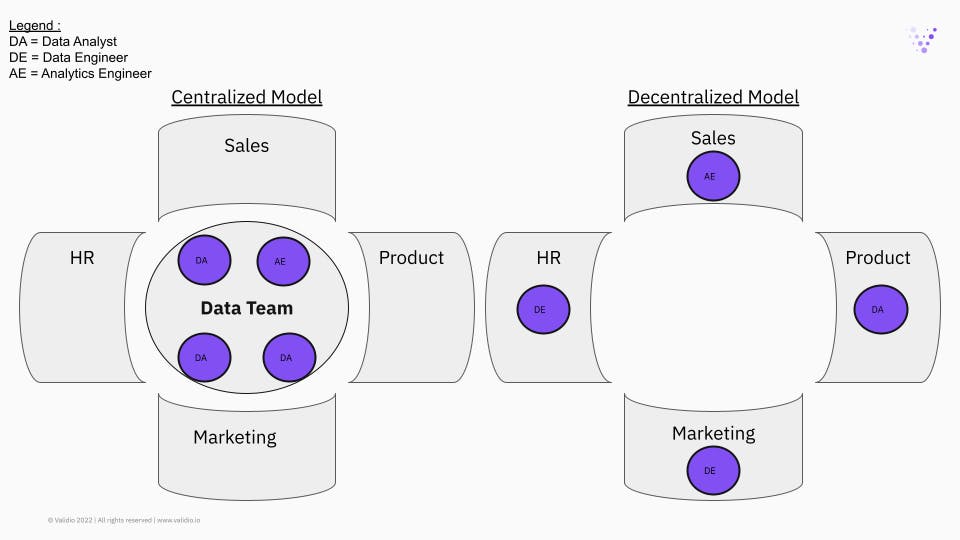
Going deeper into the reasons for choosing one over the other, Jacob summarized it as “a journey”. Simply put, there is no one model that fits all companies at different stages of growth. In the case of a small startup, a decentralized model might be preferable in order to go fast by staying close to the project owner with a rich business context. However, as a company grows to employ 100+ people, this approach can create redundancies in the tech stack as well as hamper learning across the organization. Opportunities for mentoring, best practice sharing and resource efficiency are also limited. Hence, companies often follow a pattern of going towards more and more centralization as headcount grows.
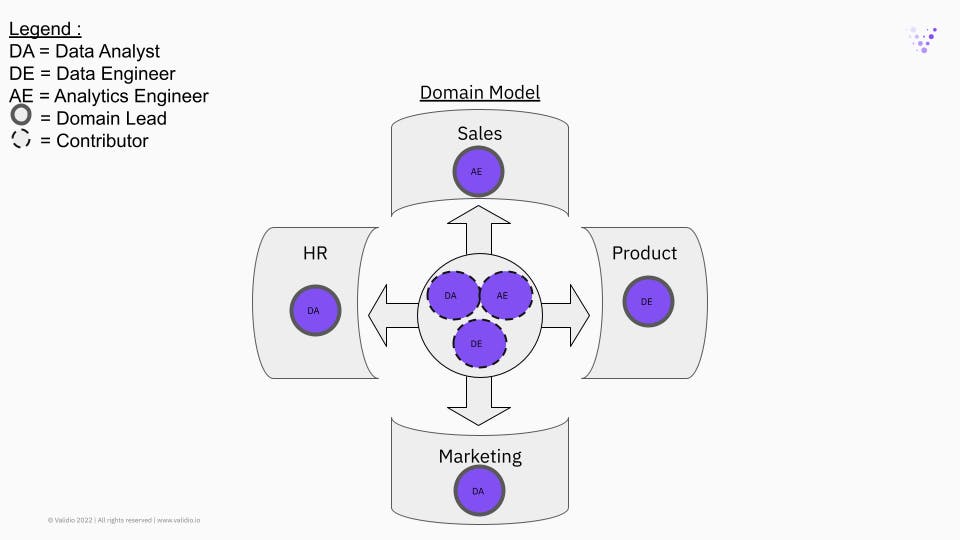
A hybrid approach has also been tested with the “domain model”: In this structure, a senior member of the team is labeled “domain lead” for a specific business area in a domain-based structure. They are then responsible for assigning work to other data engineers and analysts on an individual basis to support business priorities. This model achieves a balance between speed and robustness by letting the data-team retain some autonomy while placing them as close as possible to their respective project owners thereby maximizing domain expertise.
However, Rebecka also brought up the case of data-centric companies such as her employer, Tink, where data is the main product. Since data is critical to their business, embedding data practitioners in all product teams is a must, whereas companies not relying on data for their main product offering might get away with a centralized data team apart from other product teams.
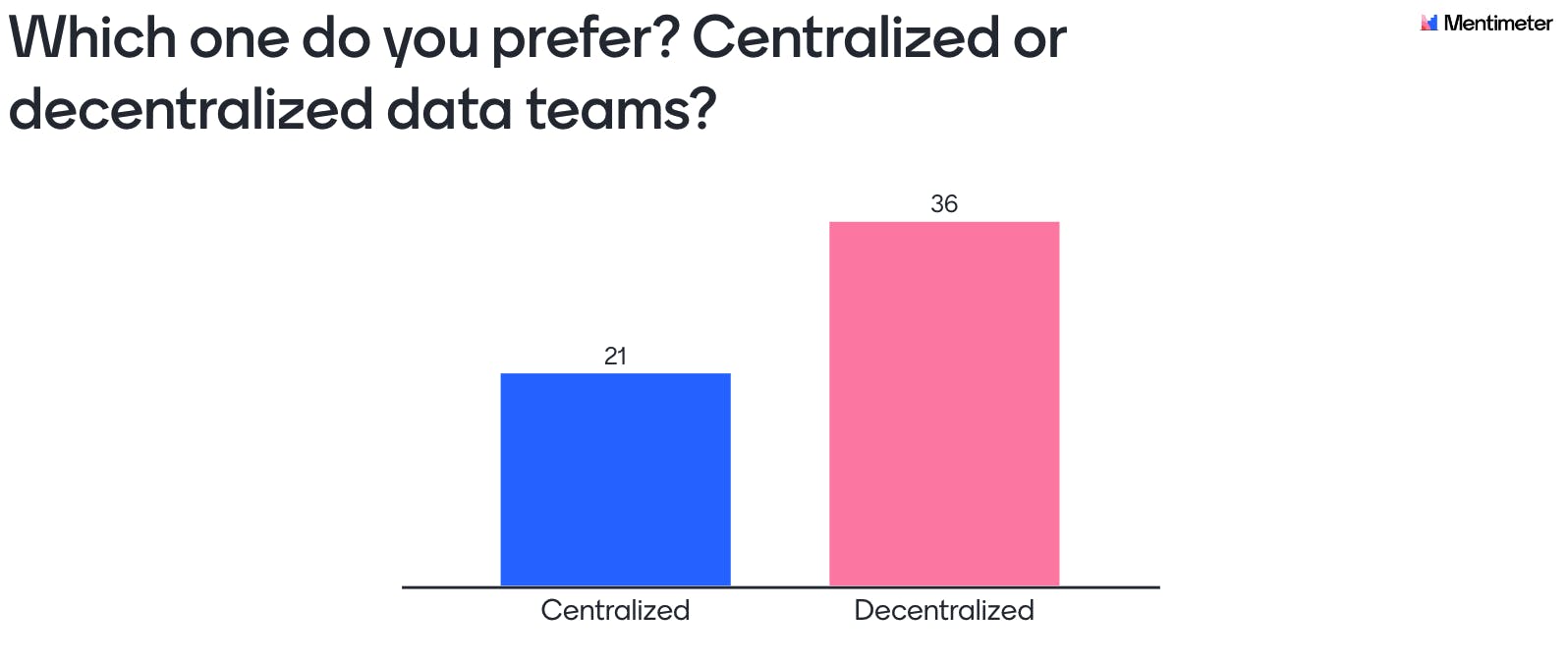
All in all, the question of how to organize data teams remains a point of contention that has to be informed by companies’ specific needs and capabilities at the specific point of their journey. Still, as the industry matures, more and more organizational models are proposed and available for data practitioners and managers to pick and choose from as they learn of their organization’s specific needs.
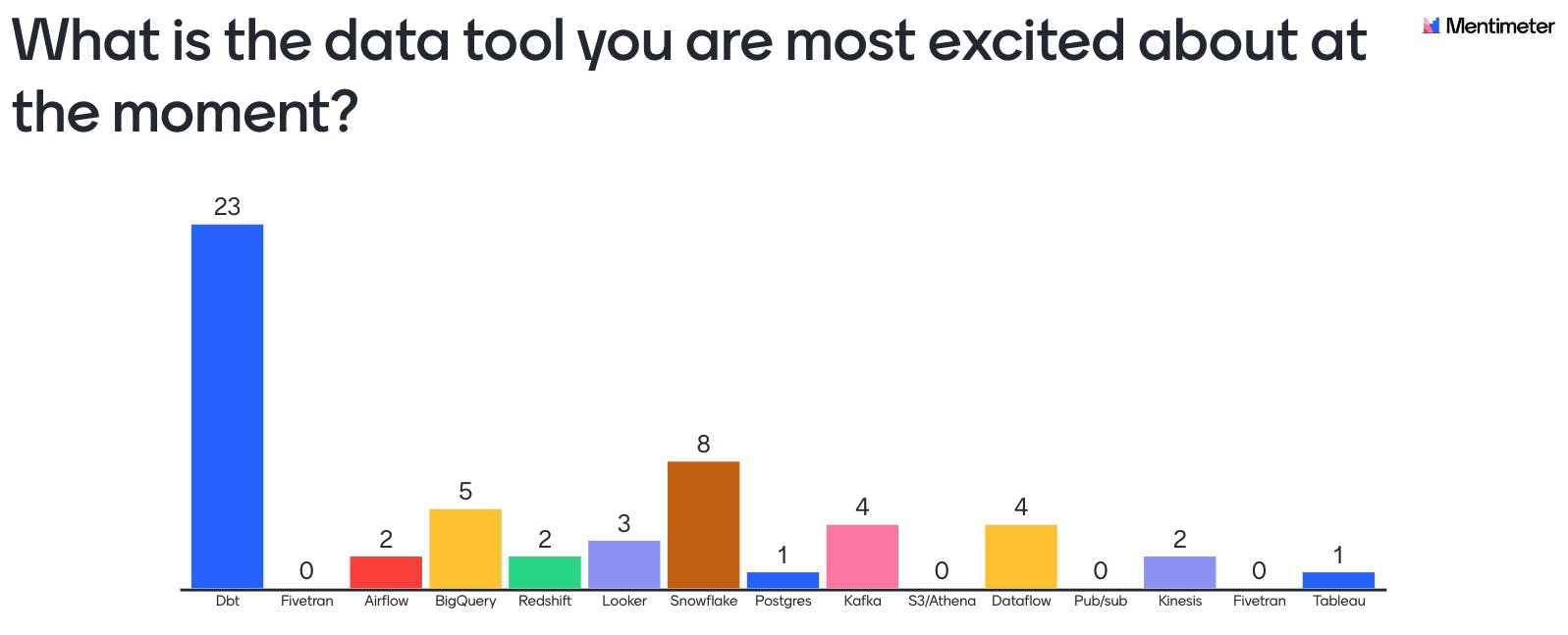
dbt is a favorite tool in the data community
Finally, we asked the audience and our speakers to name the data tool they were the most excited about at the moment. By a large margin, dbt came in first. Not surprising given one of the most common job titles at the meetup was “analytics engineer” , a title literally invented by Fishtown Analytics, the creators of dbt. Yet, the tool that created the most discussion was BigQuery, with Rebecka as their champion. In her opinion, BigQuery is the most impressive tool out there with potential to claim even more space in the data stack. For instance, the scheduling of jobs in BigQuery could already replace a large chunk of the work done by data processing pipelines, removing the need for separate data processing tools like spark, beam or glue. Combining data storage and data processing has the potential to reduce the complexity of the data stack tremendously. These findings align with our observations regarding the most popular data tools in the Nordics with BigQuery and dbt being community favorites and being used by nearly half of the teams we’ve spoken to.
When asked about their philosophy regarding build vs buy decisions, Jacob was quite adamant in his defense of building as little as possible. While it might be a surprising stance and seem counterintuitive coming from an avid coder and serial CTO, building a software company involves building but also buying a lot of software: knowing when to choose which path is the tricky part. Jacob pointed out that it often makes sense to not dive head-first into coding and to relax one's requirements when shopping for solutions. Data teams should conserve developer resources for projects pertaining to the core competencies of the company and glue together “good enough” out-of-the-box solutions for anything outside of that core domain. For example, it might not make sense for a company with its core competencies in logistics to expend precious developer resources on building an in-house HR-platform whereas a proprietary navigation tool might truly propel them ahead of the competition. Add to that the cost of maintaining the in-house solution, onboarding new users and integrating with existing tools and many build decisions seem rushed and ultimately bad business decisions.
Inversely, building one’s own solutions is sometimes the only viable option. Rebecka also pointed out that the data space has additional challenges in this regard because of the flurry of recent and extensive data regulations. Especially in the financial sector, the information handled can be so sensitive that no out of the box solution can satisfy all of the legal and customer privacy requirements.
The data community should talk less about specific tools and more about what we want to do with data
Finally, a sentiment brought up by Rebecka and echoed by several audience members in connection to the event, was the feeling of being overwhelmed by the sheer number and complexity of different data tools. This constant need to feel up-to-date with the latest business buzzword, analytics acronym or startup seed round might make even the most experienced data practitioner feel out of the loop or ignorant about their own subject matter. This “impostor syndrome” has a corrosive effect on the community and its practitioners, hindering communication and excluding large parts of it from participating in the discussion. Rebecka suggested that engineers and the community at large instead be mindful of how we speak, focusing on the functionality and use cases of a certain technology before blurting out the name of yet another obscure tool or package to a silently nodding audience. How do you make sure to be clear and inclusive when speaking about technical subjects?
Closing thoughts
To sum up, this first Data Engineering Meetup by Heroes of Data was a resounding success, gathering the community and some of its brightest shining stars. We got to mingle and discuss a few important topics with the following learnings:
- The data community can benefit from better ways of measuring their impact
- We are still exploring the best ways of organizing data teams, and it depends heavily on the specific business context and objectives
- dbt is a favorite tool of the community but other tools will have to compete with in-house tools as we discover what to build and what to buy
- As a community, we should talk less about specific tools and more about what we want to do with data in order to be more inclusive and intelligible in our conversations.
We are once again very thankful to be drivers of this data community and for the opportunity to be a part of these discussions. If you haven’t already, don’t forget to subscribe to this newsletter, become a member of our Meetup group for upcoming events and visit our community slack to join the conversation!