A simple machine learning case
To illustrate Validio’s capabilities for validating data in Google Cloud Storage, we use a simple ML case. Since it’s common to store training and prediction data in CSV files in object storage, that’s what we’ll look at for this scenario. We’ll walk through data quality challenges that commonly occur, and how to use Validio to overcome them.
OmniShop, a fictional e-commerce company, has a ML team of four engineers. The team has recently implemented a recommender system that suggests relevant products to the customer based on their purchase- and browsing history.
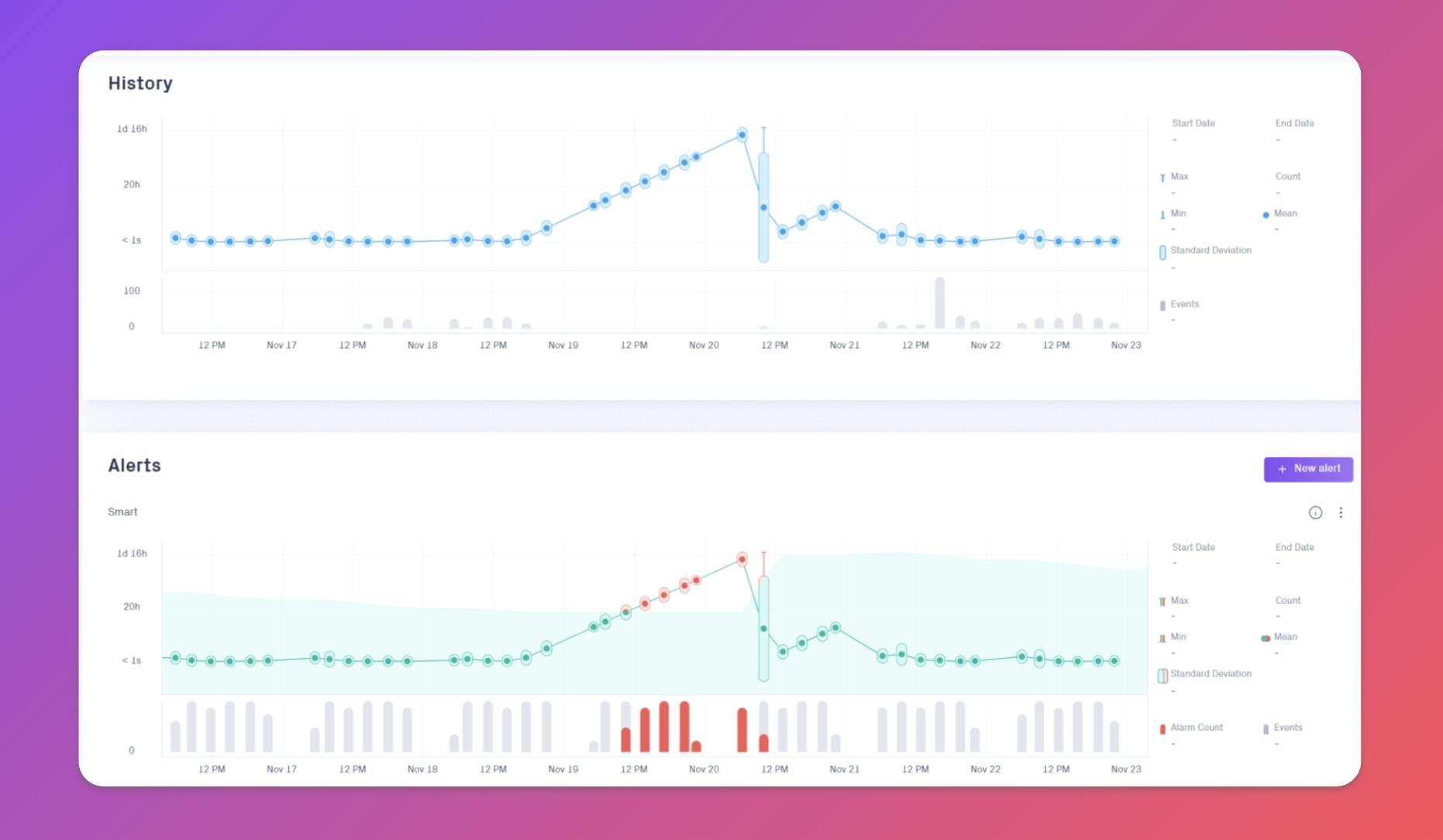
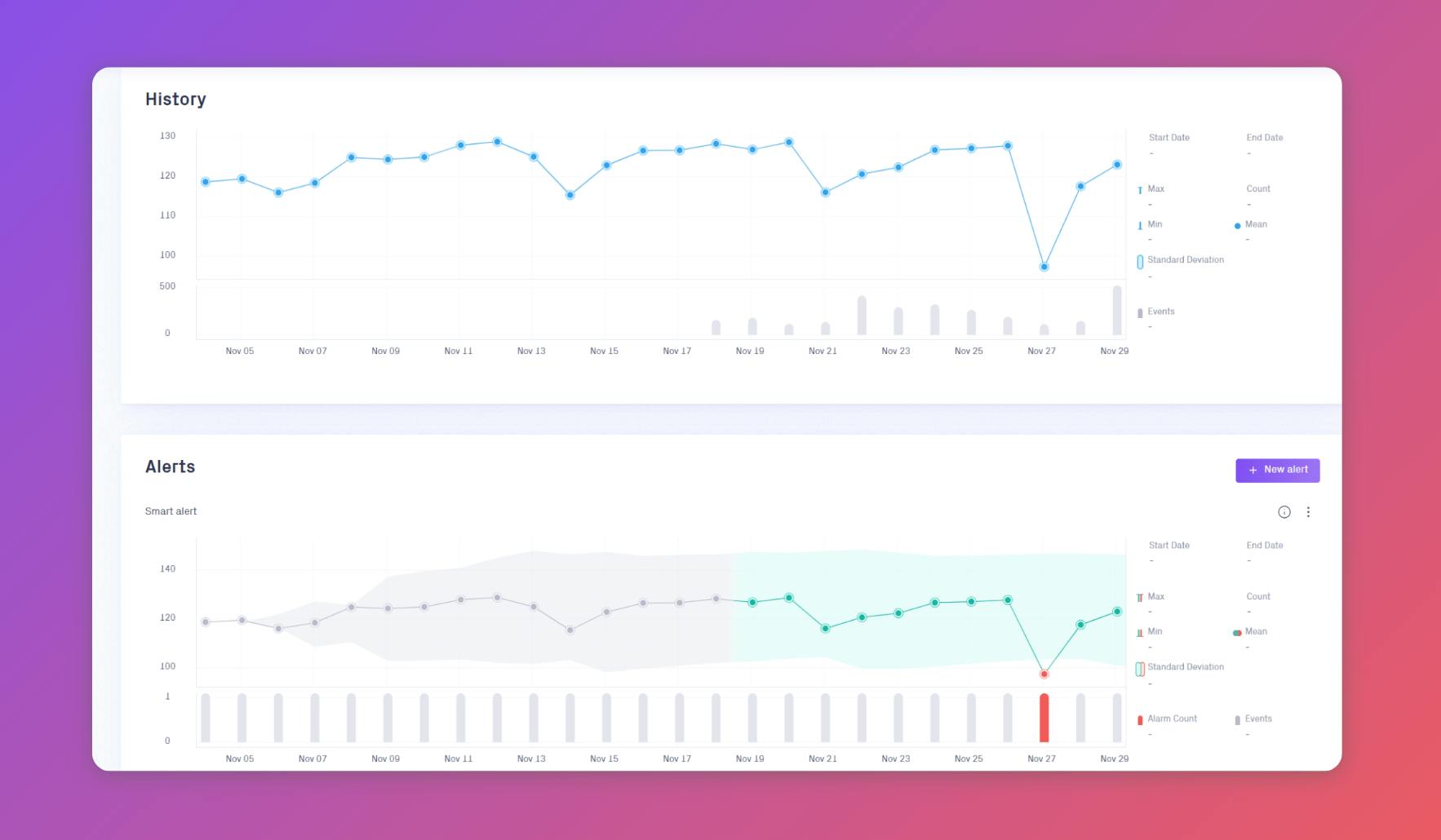
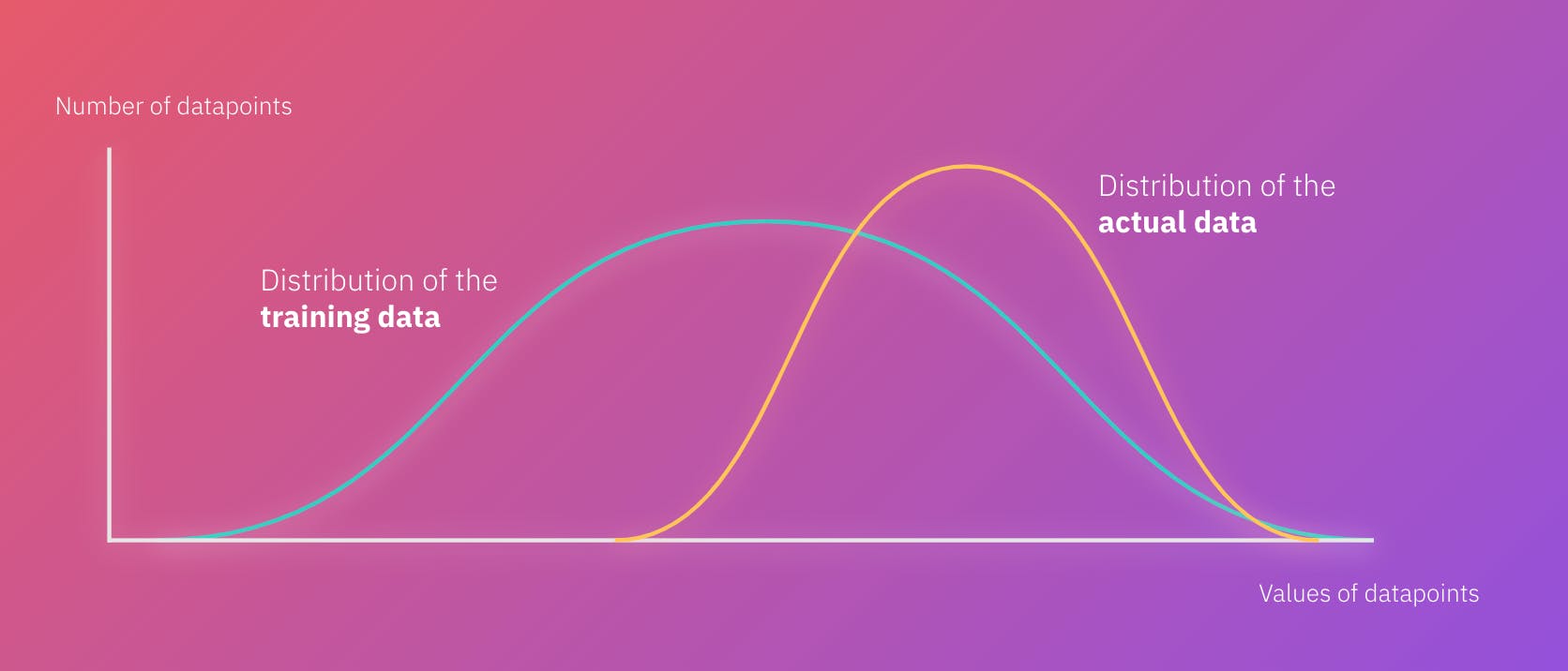
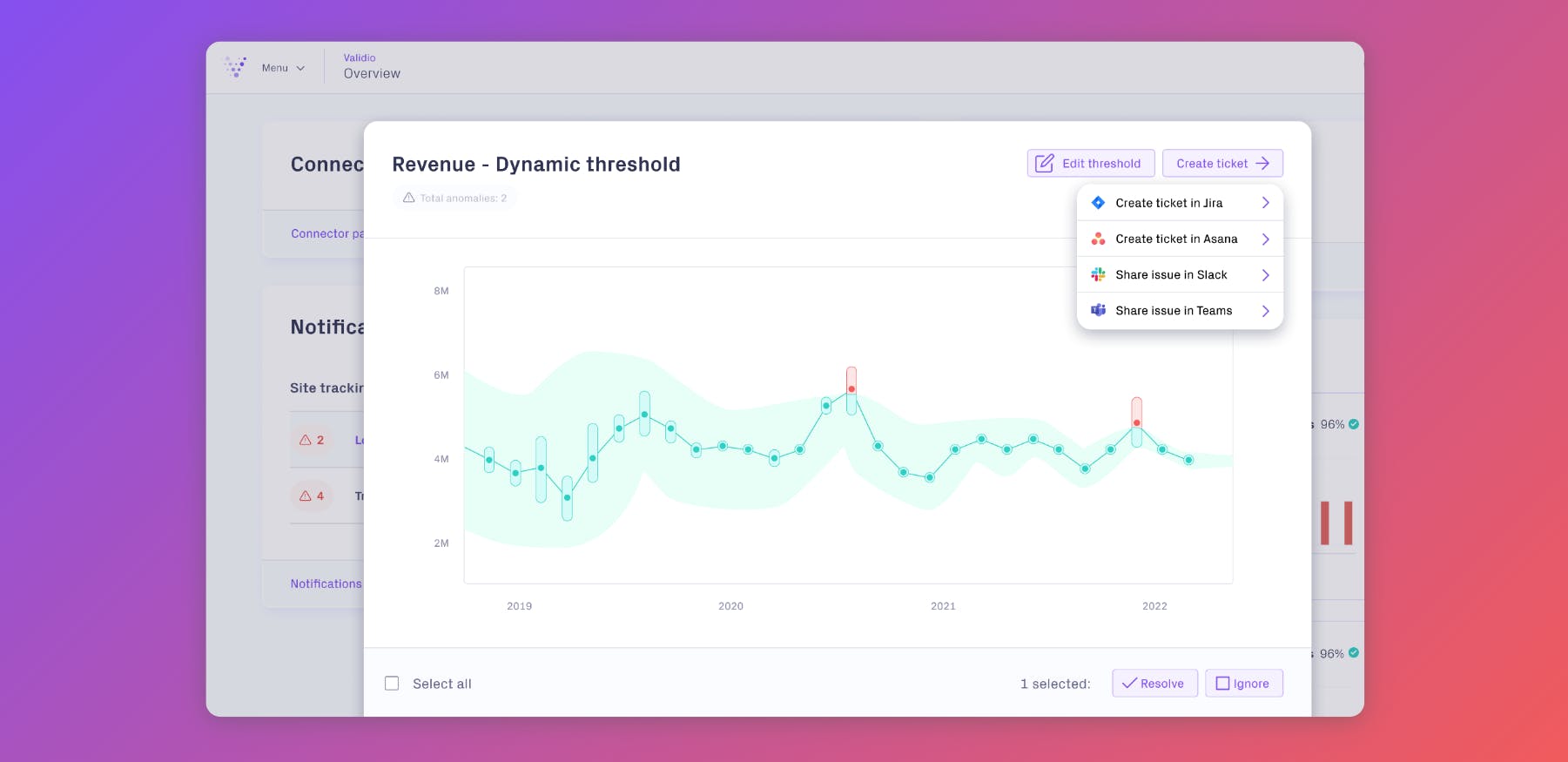
In this scenario, we follow one of the ML engineers, Jade, who is concerned about the accuracy of the model predictions. So far, the recommendations have had a low success rate. Customers are not buying the recommended products, and Jade worries that the input data has had critical data quality problems. It’s crucial for her team to be able to quickly identify and address issues in the data, so their predictions lead to better sales performances for OmniShop.
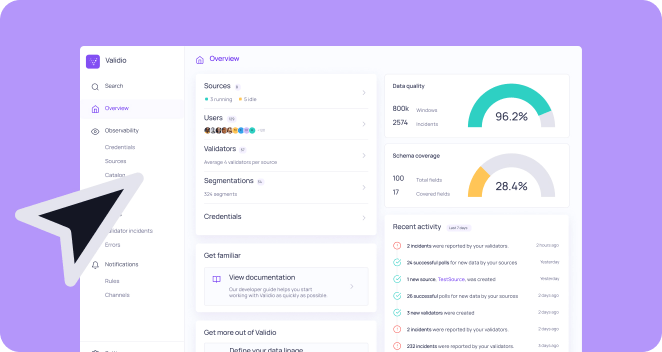
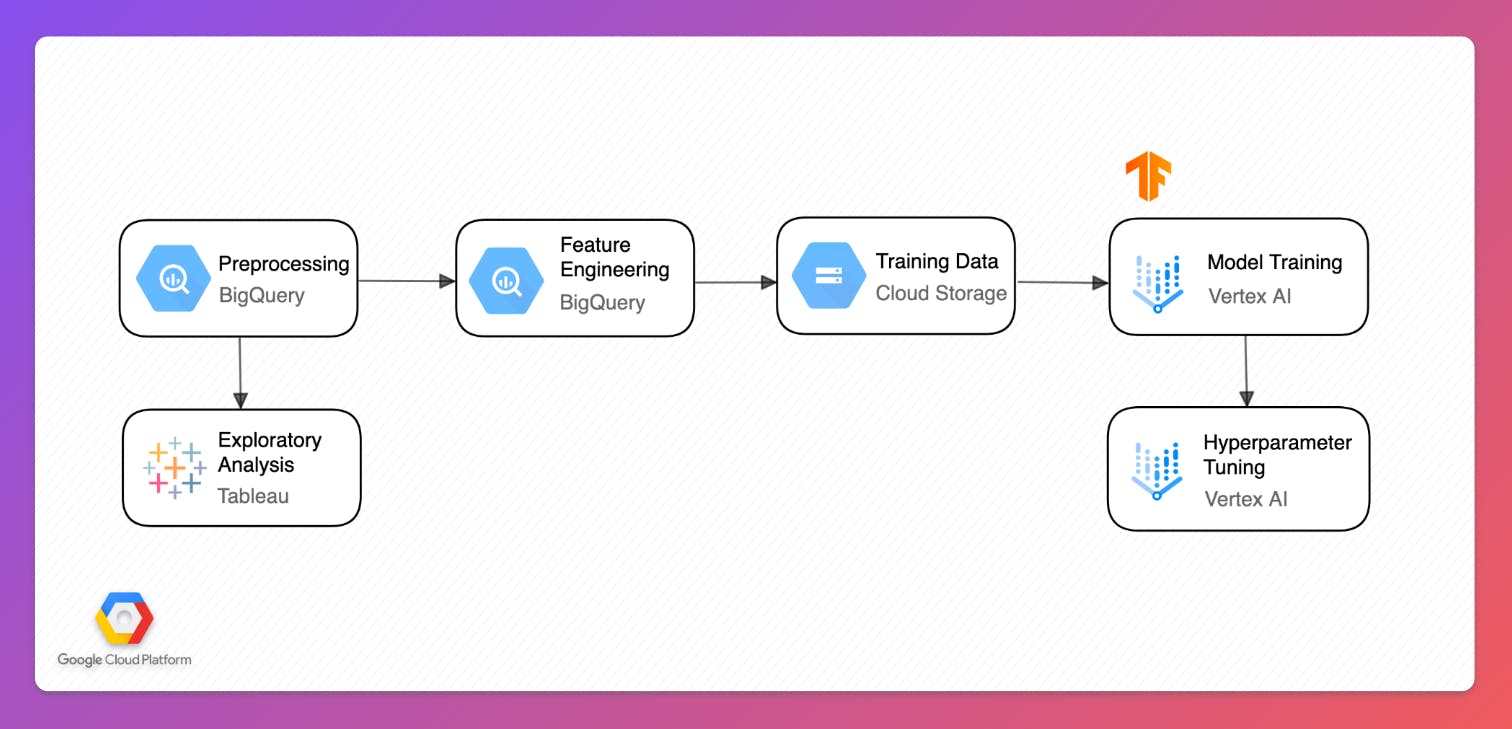
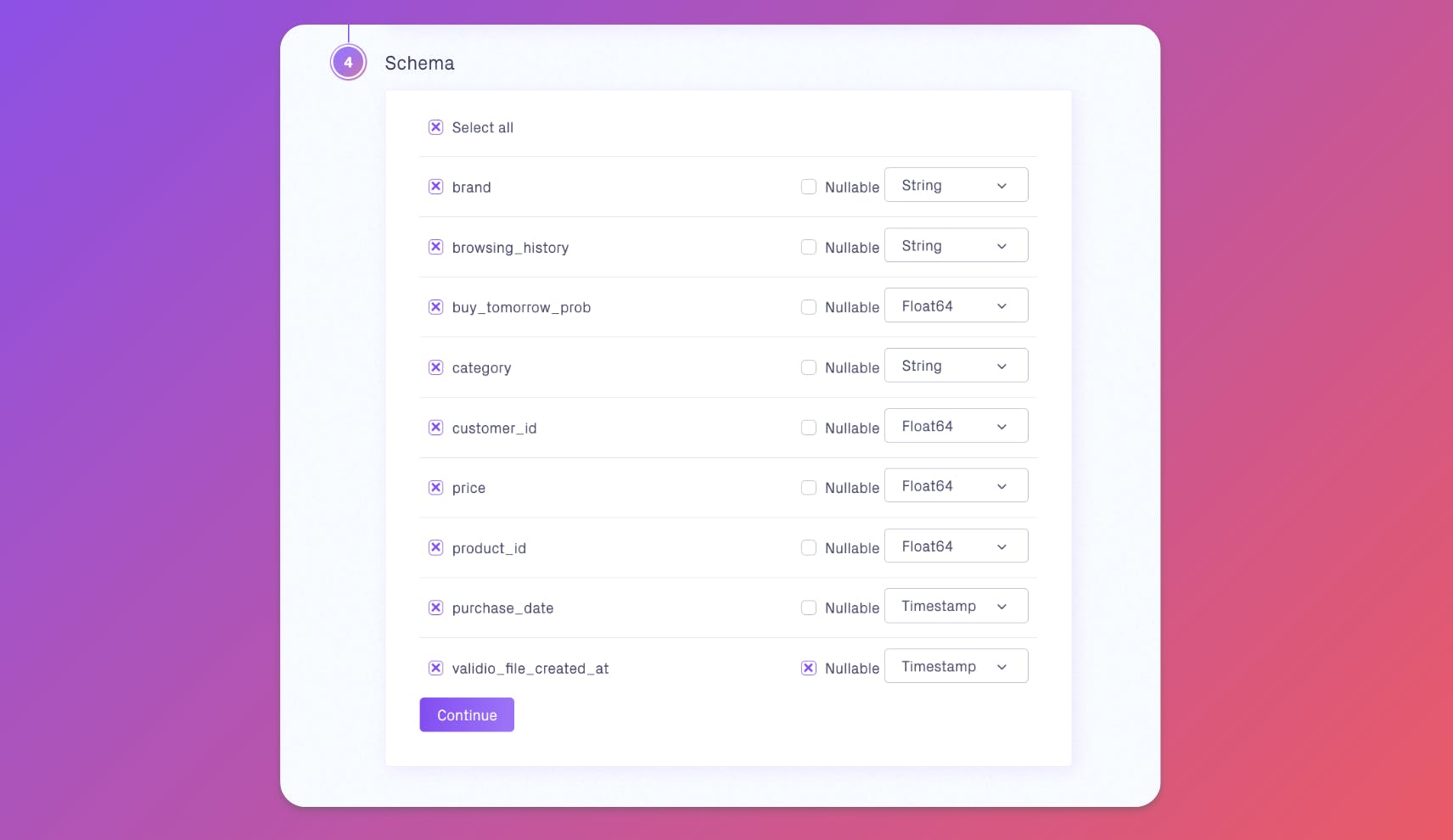
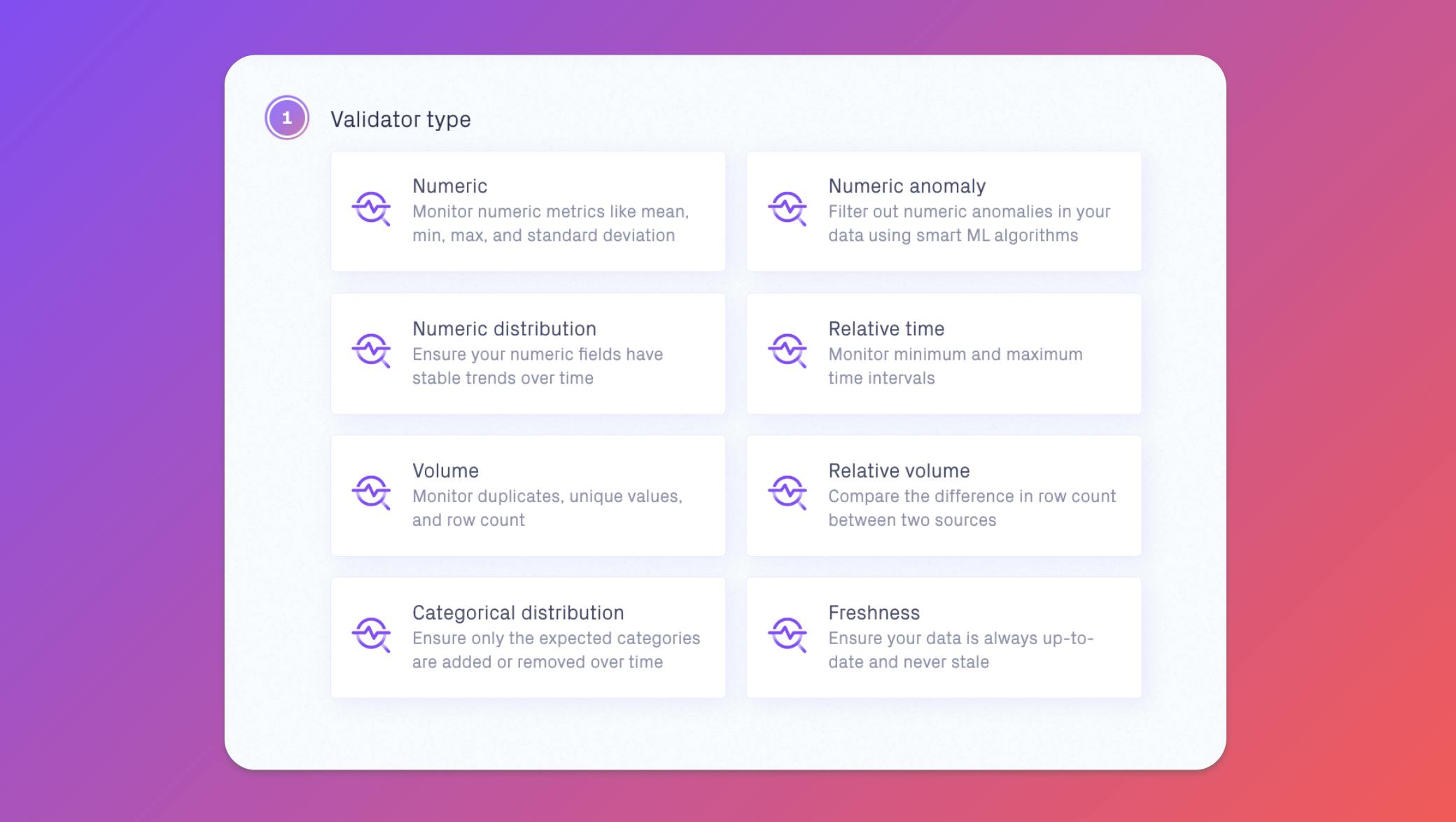
To do this, Jade and her team have decided to implement Validio’s Deep Data Observability platform. Jade starts by setting up validations for her team’s most critical dataset customer_purchases, which comes from a view in BigQuery. The view is exported as CSV files and stored in Cloud Storage, before further processing for model training.