1. Degree of depth
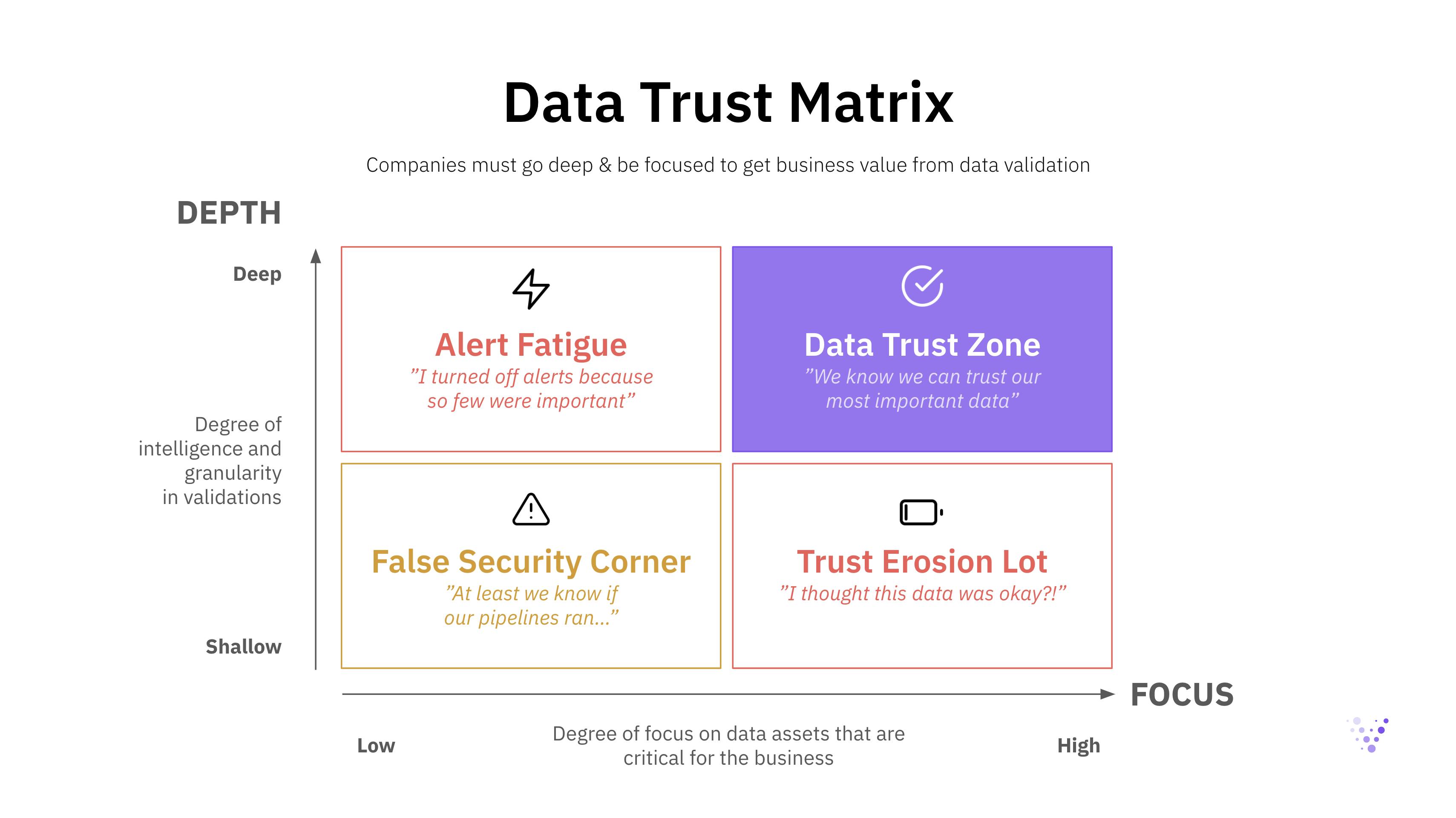
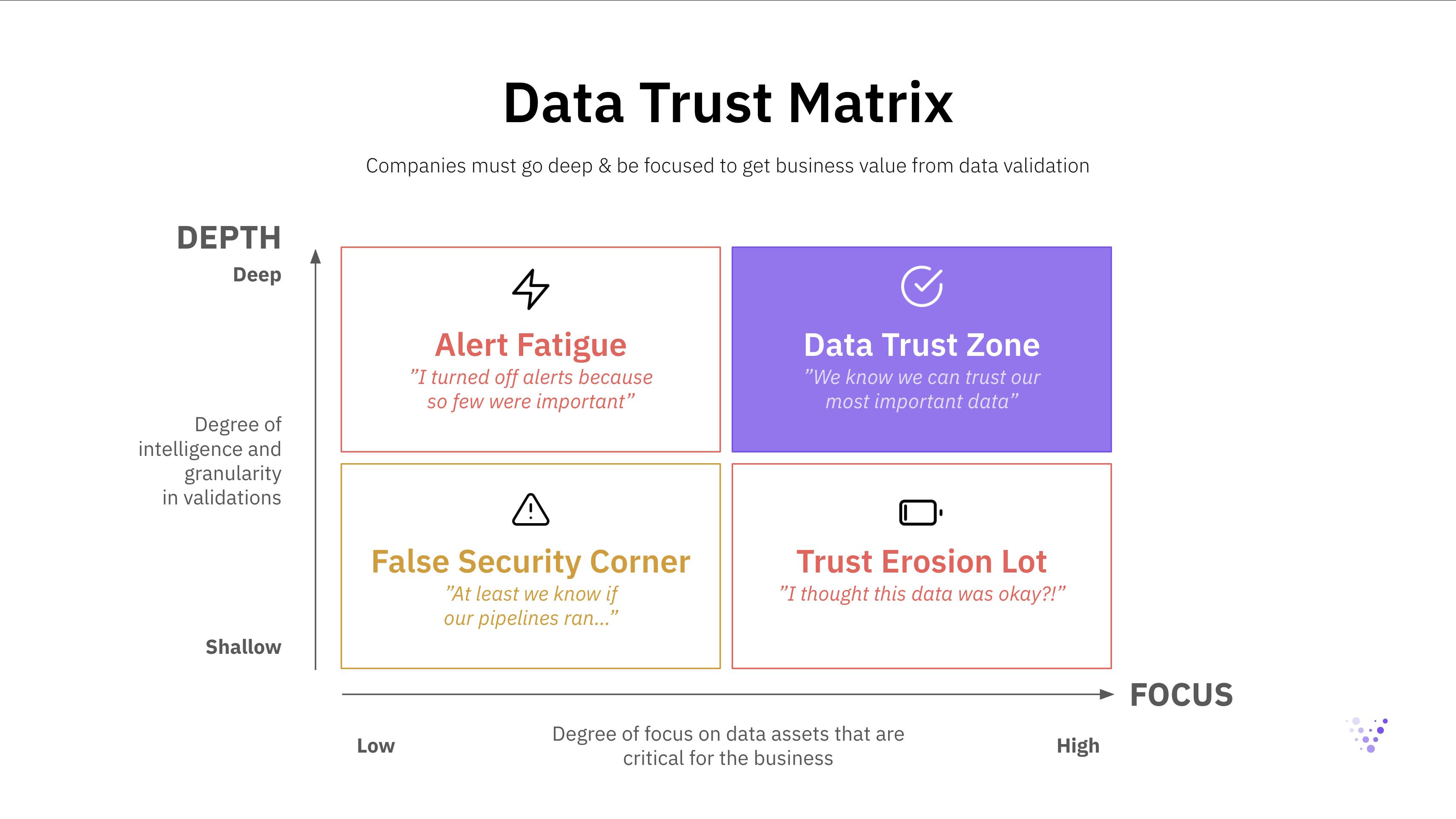
Data teams can either go deep or shallow on data observability. Shallow data observability means the “easy” and basic validations of data quality, meaning metadata monitoring of volume, freshness, schema, and null value distributions. Deep data observability, on the other hand, offers automated and in-depth validation of the actual data in each field, in addition to basic metadata checks, and includes:
- Machine Learning-based anomaly detection, advanced data distributions, and row-level granularity
- Dynamic thresholds that adapt to data over time and detect outliers from trends and seasonality patterns
- Dynamic segmentation that slices a dataset into relevant subsegments and validates each subsegment independently using dynamic thresholds. This lets you find anomalies in detailed segments of your data you didn’t know to look for
- Doing all of the above at scale, in real-time, and preferably at a low cost
2. Degree of focus
The second choice data teams have to make regarding data observability is how focused to go. Should they apply the same set of checks to every dataset, or should they have a more focused approach to differentiate between high-value and low-value data assets?
It is important to acknowledge that data is never perfect. You always need to be prepared for potential data quality issues. Given that the amount of data that companies collect is rapidly increasing in the era of big data, it is important to prioritize and focus on the data assets that really matter. It is common to see that 5-15% of companies’ data provide 85%+ of the business value–not all data is equally valuable. To achieve an outsized impact as a data team, while saving costs on infrastructure and tooling, you should therefore focus on the 5-15% of your data assets that matter most for the business.
The focus is also important to help organizations design reasonable processes around data quality issues. The ability to identify the data quality issues is one thing, to promptly respond to and mitigate them, with the right stakeholders involved, is another. The focus is crucial in enabling the right stakeholders to address the identified data quality issues in a timely manner.
Let’s dive into the implications of each choice the data teams have to make.