What is PII and why is it challenging to handle?
PII is the acronym for the legal term Personally Identifiable Information as defined by GDPR. This regards any information regarding a person, that directly or indirectly could reveal their identity. This includes name and address but also other traits such as gender, age or interests that when combined could help in determining the identity of a person.
Since April 2016, the EU has upgraded the protections awarded to citizens of the EU when it comes to the management of their PII through its General Data Protection Regulation (GDPR). The regulation states that any customer has “the right to be forgotten” meaning that all their PII should be erased from a company’s records. This in turn creates the need for new tools and techniques to adhere to the tightened regulations.
In Mathem’s case, this translated into the following requirements for the pseudonymization of PII:
- No materialization of PII, meaning nobody should be able to query a production database for PII. Specifically, this means that PII should not be stored in the data warehouse because once it’s there, it would be very hard to remove it.
- The right to be forgotten has to be implemented and also in a granular manner such that a customer might erase only part of their history or certain fields in that history. For example, a customer might want only their home address to be forgotten, but not their email address.
- Data security becomes even more of a priority since, more than just protecting the privacy of users in the context of Mathem, this data also has to be protected if it were to end up in the wrong hands despite security precautions.
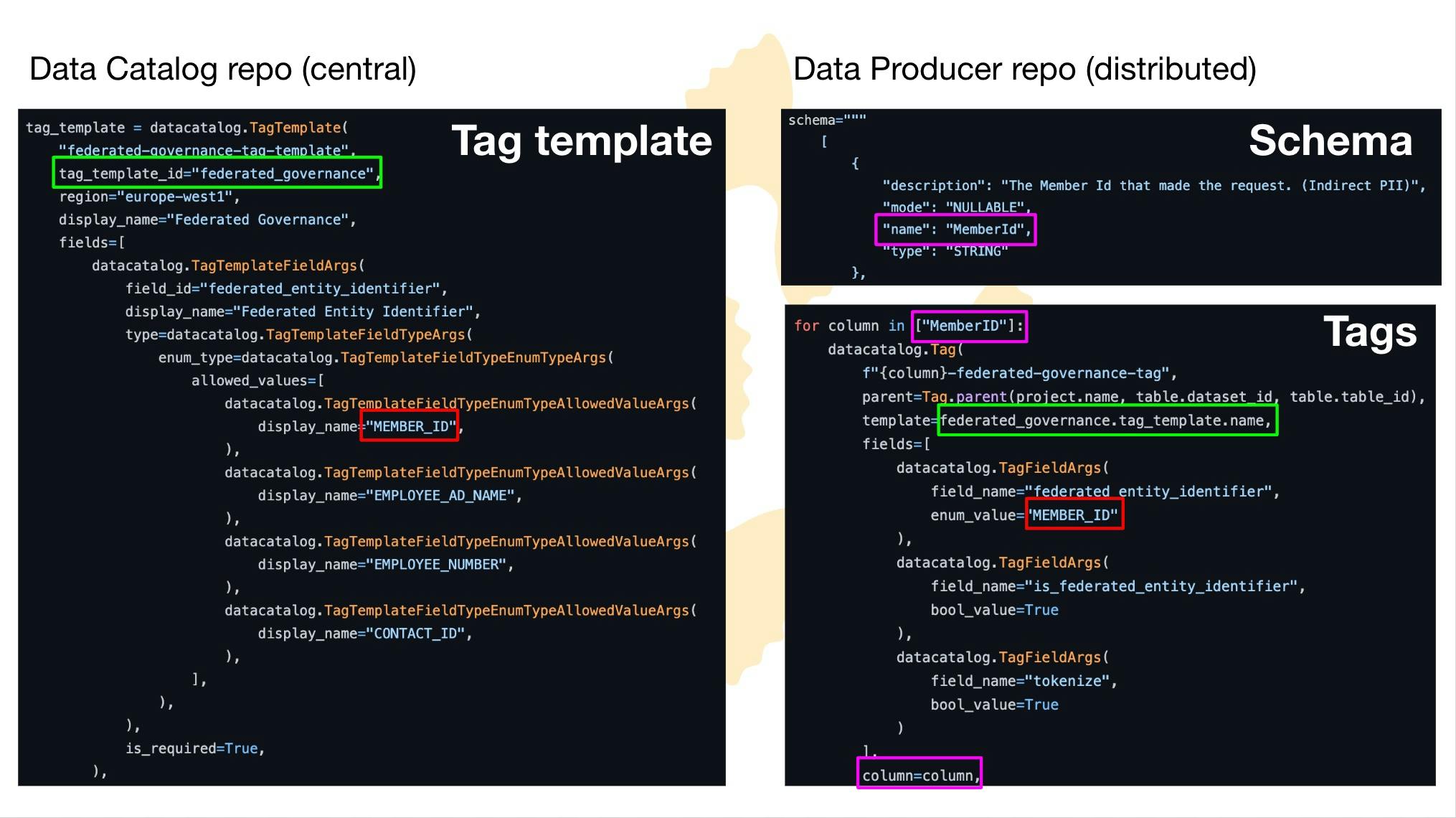
- Leaning into the overarching trend of the data mesh, and to promote the scalability of the central data engineering team this project must also enable Distributed data producers. To be able to collaborate between data sets created by different data producers, this system must also support federated governance and referential integrity.
- Resolving the issue of PII will also enable more parts of the company to interact with otherwise potentially sensitive data which achieves its goal of data democratization: where everybody in a data-driven organization has access to it.
- The data also has to retain its operability. Unlike anonymization, pseudonymization is a process which still allows re-identification should Mathem need to do so.
- When removing PII, datasets must still be kept immutable so that analytical datasets are not affected by dataset level pseudonymization. For example, the row count for number of active users should stay intact even if an active user’s PII is removed.
- Finally, the system should be future proof such that expected advances in for example encryption don’t break the system.
With this description of the PII challenges that Mathem faced, we’re now ready to dive into Robert’s solution.
The solution: tokenization
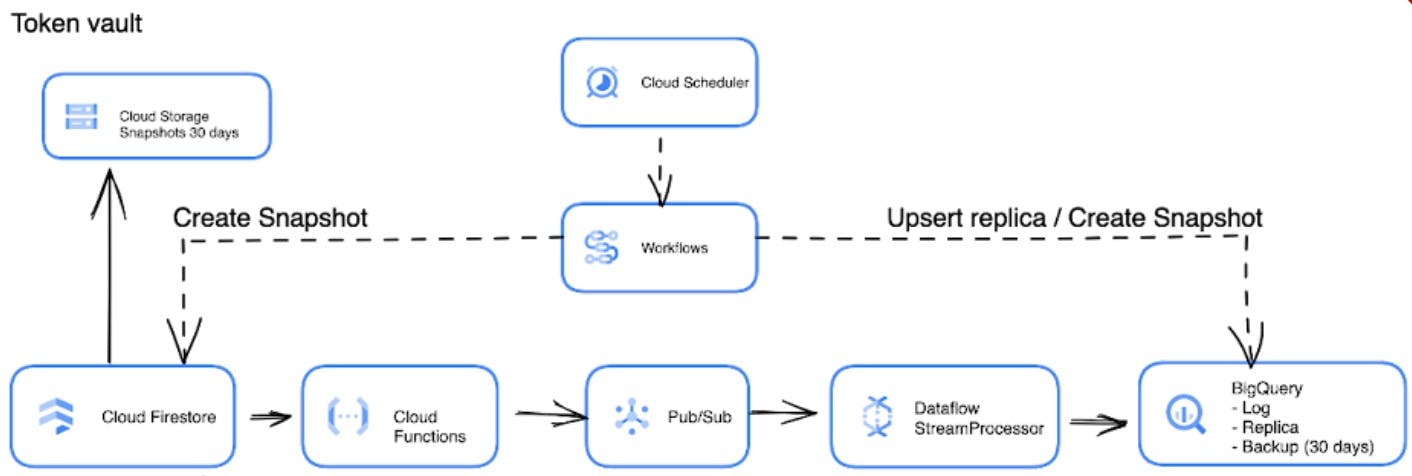
In order to satisfy all of the above requirements for PII, Mathem adopted what they refer to as a tokenization approach. This process entails encrypting the data by substituting PII with a randomly generated token of the same length and data type as the original value. These are then stored in a secured lookup table (vault) that maps the original value to the corresponding token. Without access to the lookup table, this encryption is effectively unbreakable. This approach satisfies the above requirements thanks to its robust encryption and straightforward reversibility making it an excellent method for protecting individual fields of data in analytical systems.
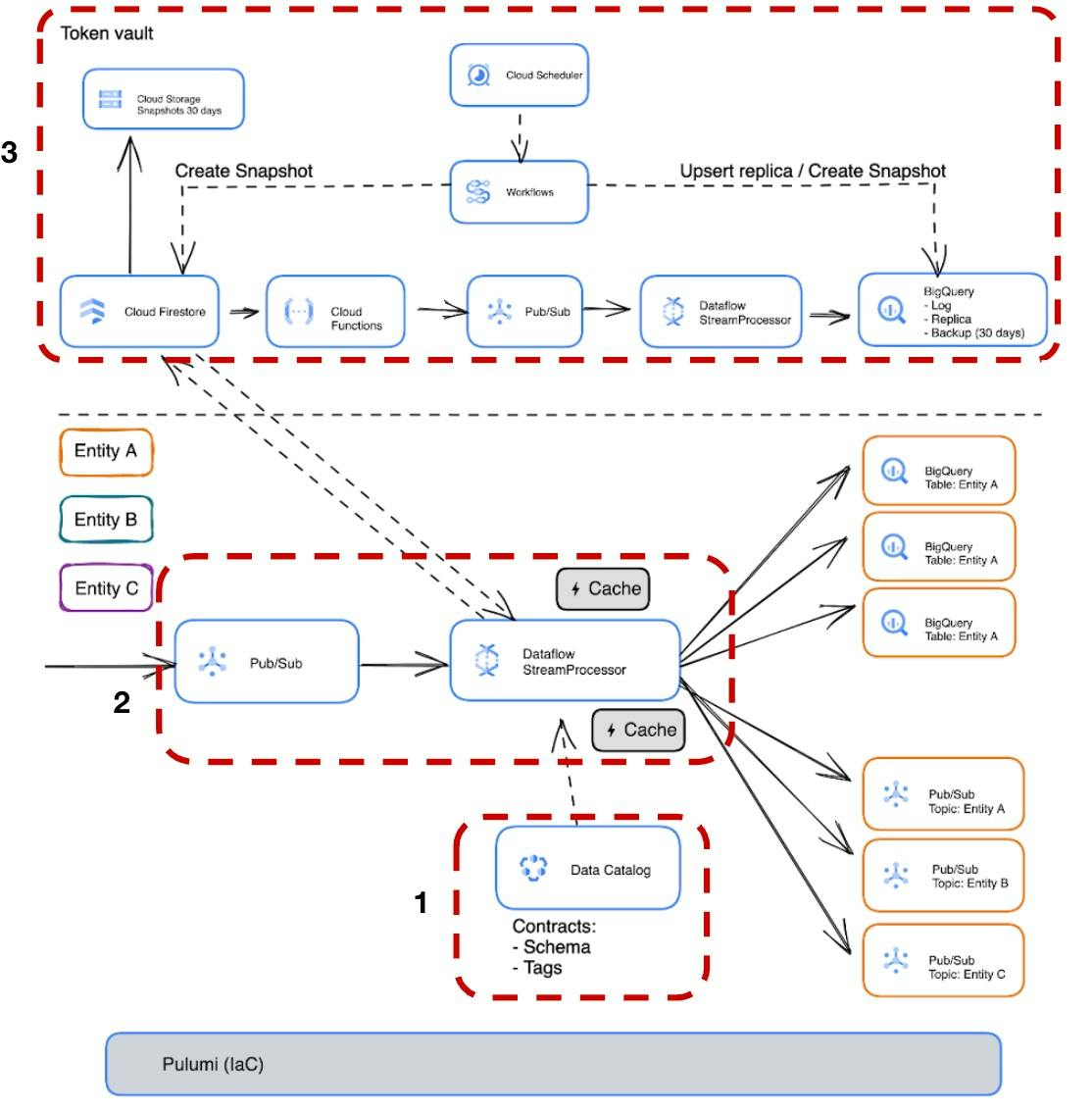
Let us now take a look at the architecture of Mathem’s system consisting of three main parts:
- Data Contracts
- StreamProcessor
- Token vault