One of the biggest inhibitors to widespread adoption of any monitoring tool (not only data quality and observability tools) is the risk of finding yourself drowning in alerts that aren’t relevant. While it’s important that any tooling you adopt includes the necessary features to facilitate actionable and effective alerts, there are a few best practices you and your team can follow to further mitigate alert fatigue.
We’ve already walked through a few best practices around setting up data quality validations. The first step to actionable alerts is to set up the right validations at the right place, if you haven’t already - our suggestion would be to start there before reading this guide.
Let’s get started!
The Overview
The four areas to keep in mind when optimizing for signal to noise ratio are:
- The right thresholds: be thoughtful of the sensitivity and what type of thresholds you apply to avoid false positives.
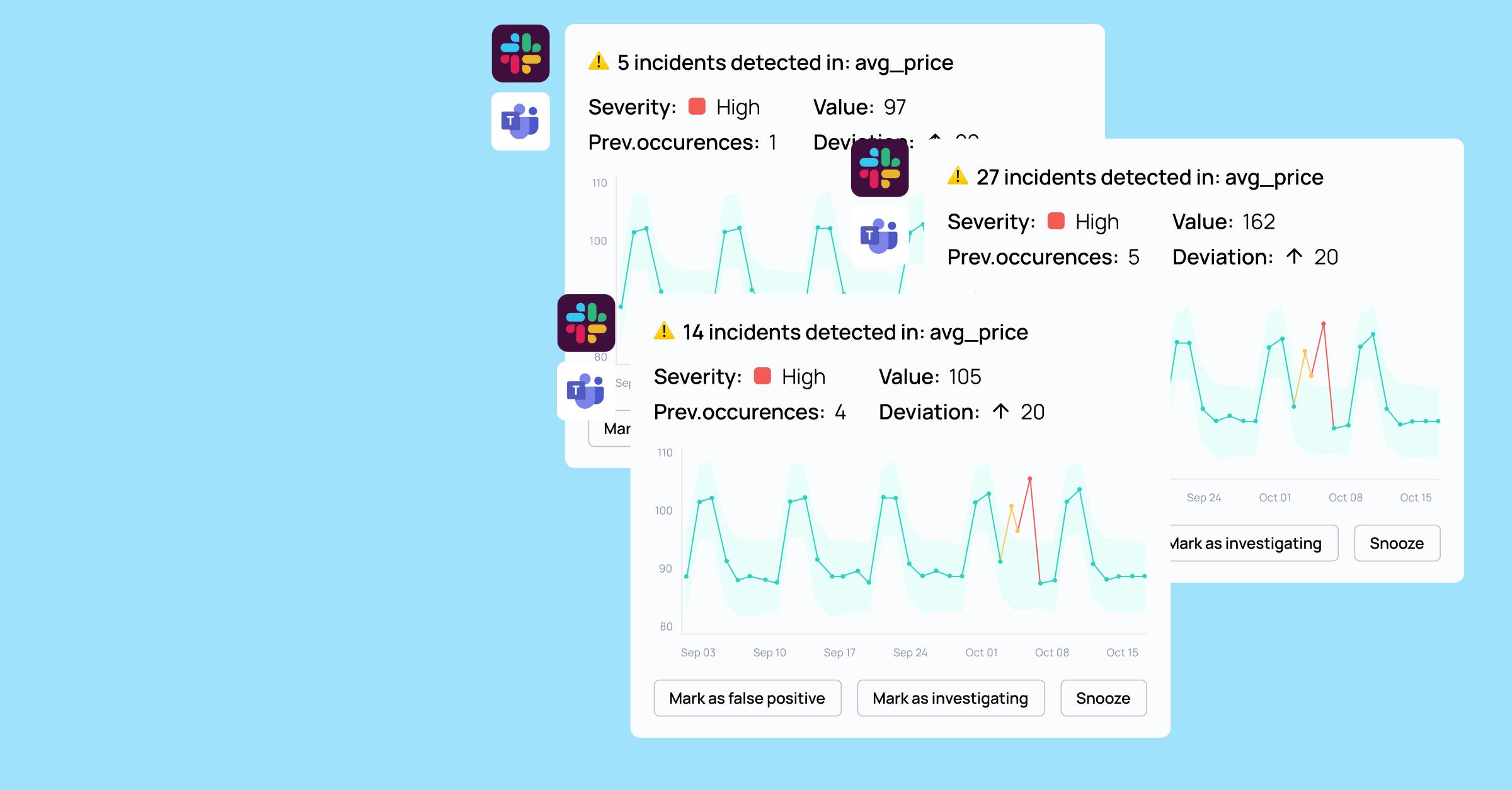
- The right channels and the right people: far from everyone needs to get alerted for everything, make sure the right people get the right alerts. No less, no more.
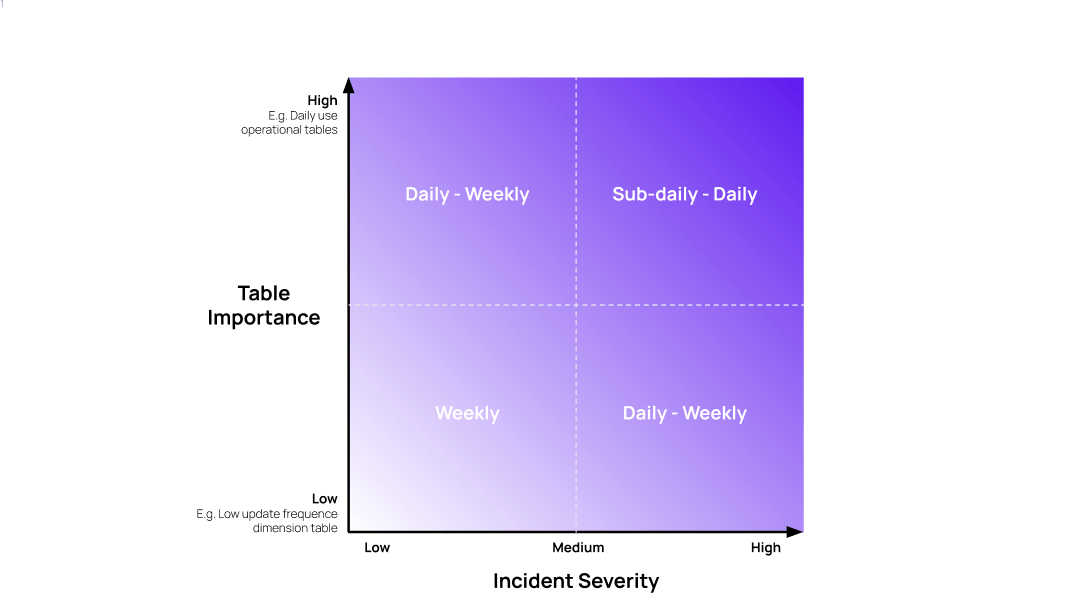
- The right timing: not all incidents require immediate action, ensure P0 notifications are sent out immediately, less urgent incidents can be addressed at a later time.
- The right workflow: to the extent possible, integrate data quality and observability incident management workflow to existing workflows and processes.
This is by no means rocket science at the end of the day, but it hopefully serves as a helpful checklist to make sure you’ve covered all the aspects. Let’s go through and expand on each bullet.
1. The Right Thresholds
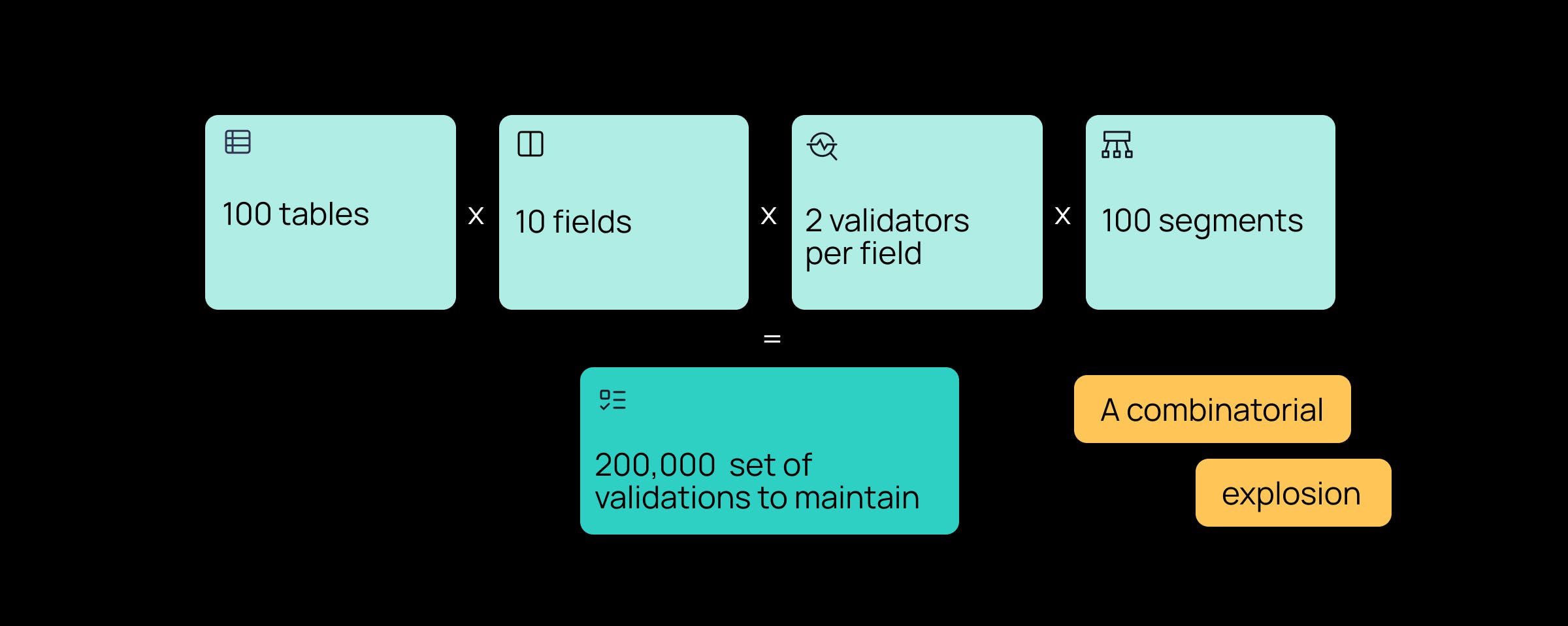
Ultimately, the thresholds you define on your validations will define what is considered an incident and what’s considered business as usual. Out of these incidents, you’ll typically choose which incidents should be sent out as a notification and customize those settings. The idea here is to address the first part; optimizing the number of incidents generated in the first place.
In general, you’ll have two types of thresholds:
- Manual thresholds - from fixed thresholds, ‘alert me if the number of records falls below 1,000,000 per day’, to difference thresholds, ‘alert me if daily active users decrease with 10% three days in a row’.
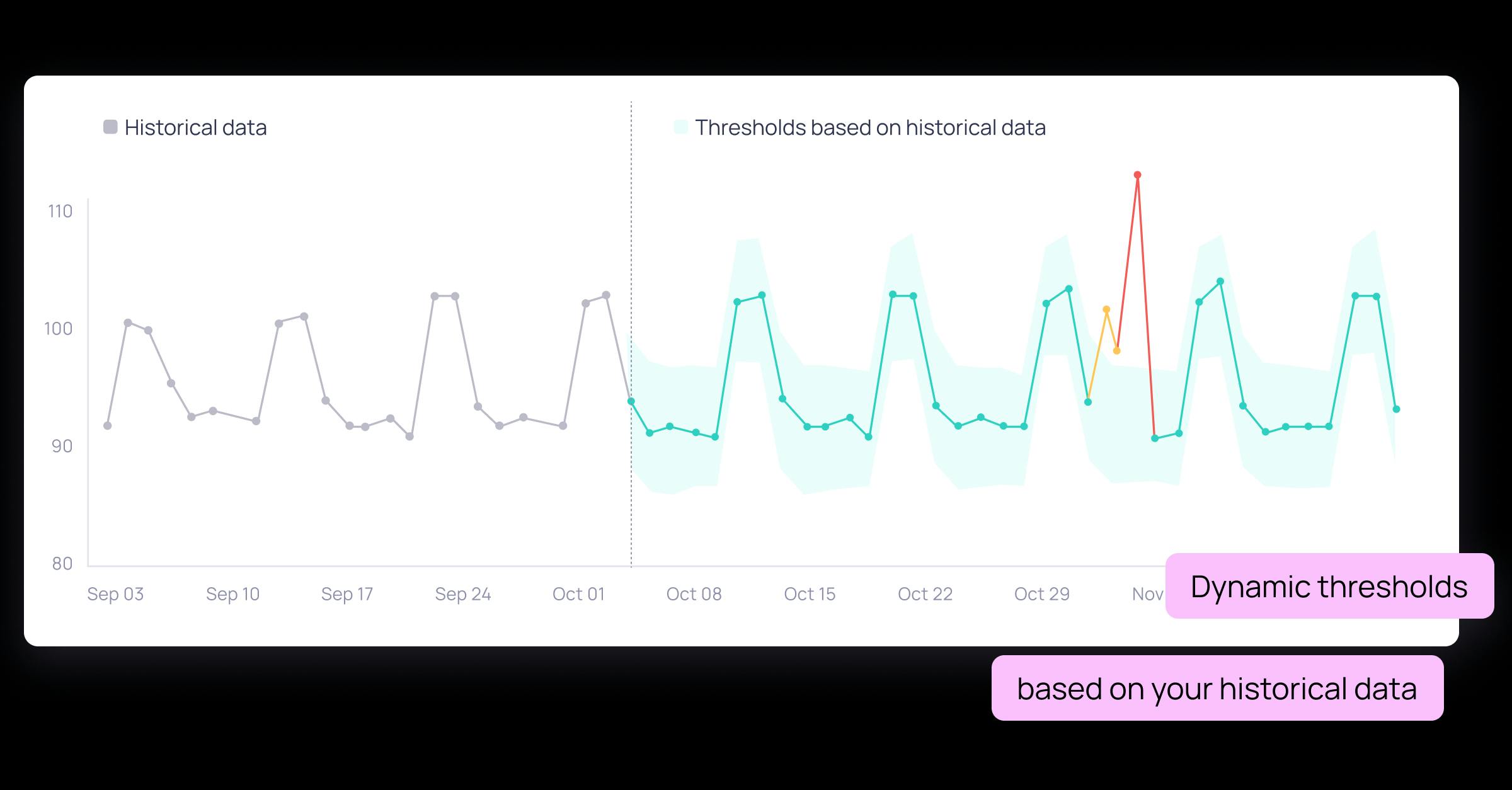
- Dynamic thresholds - ML driven thresholds that are automatically defined based on historical data, adapting over time