

Observability & quality
AI-powered, segmented anomaly detection to find issues hidden in deep segments of your data.
Lineage
Map your entire data landscape and see data quality monitoring overlayed directly in the lineage map.
Catalog & glossary
Discover all your data, understand how it’s used, and manage ownership to drive data governance.
120x
Quicker detection of issues
Automated data monitoring helps detect issues in minutes instead of months.
100M+
Records per minute
Validio scales data quality monitoring across large scale datasets without compromising performance.
95%
Less manual time spent
Reduce the time spent on manually monitoring and investigating issues by up to 95%
Take an interactive tour of the platform
Data quality & observability
Don’t let any incident go unnoticed
Validio learns from your data trends and patterns to detect anomalies in your data and metrics.
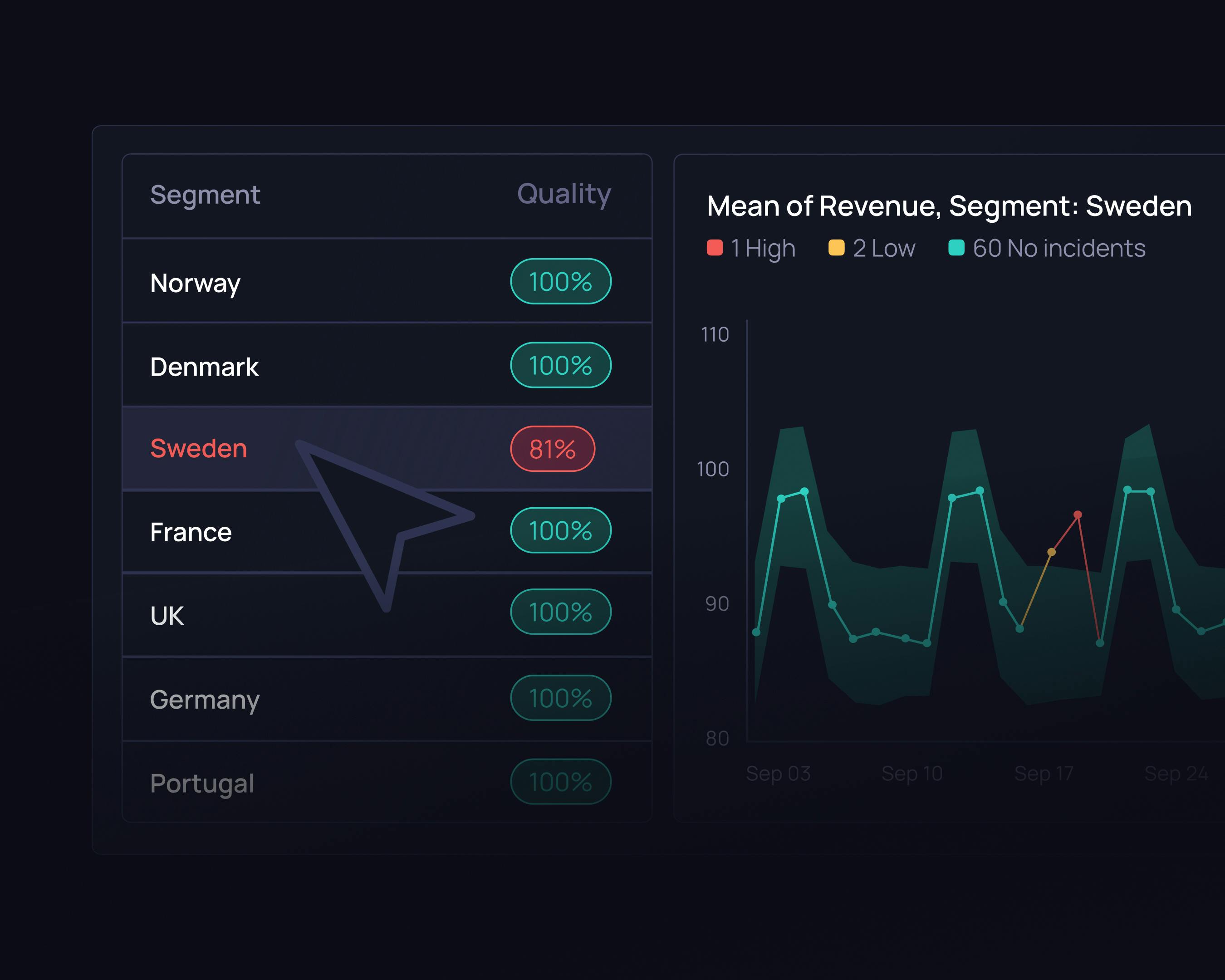
Monitoring across data segments
Anomaly detection that finds issues across dimensions like markets or products, to find issues that would otherwise be hidden in overall trends.
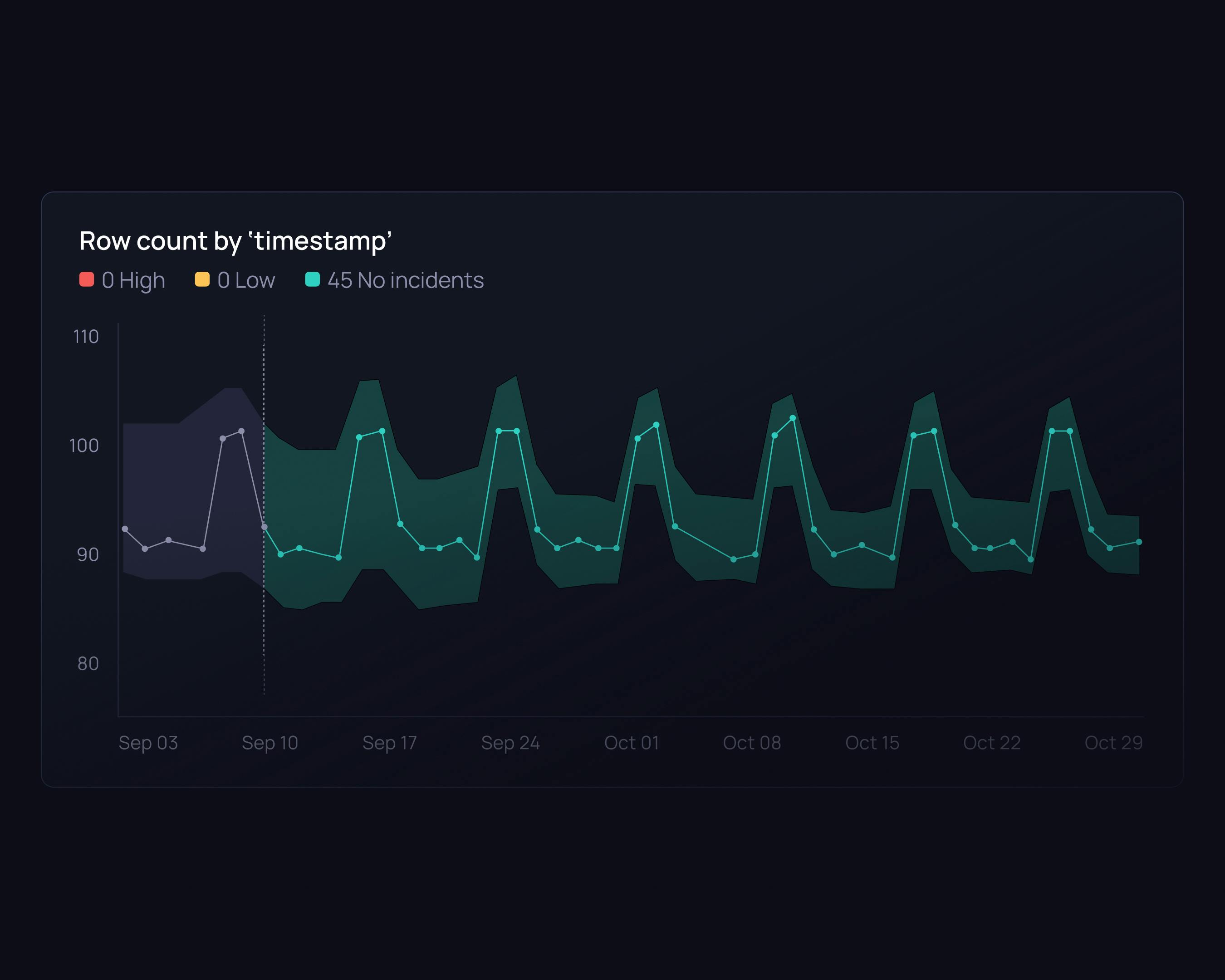
Self-learning models
Our algorithms adapt to your data patterns and seasonal trends, using historical data and user input to continuously improve validation.
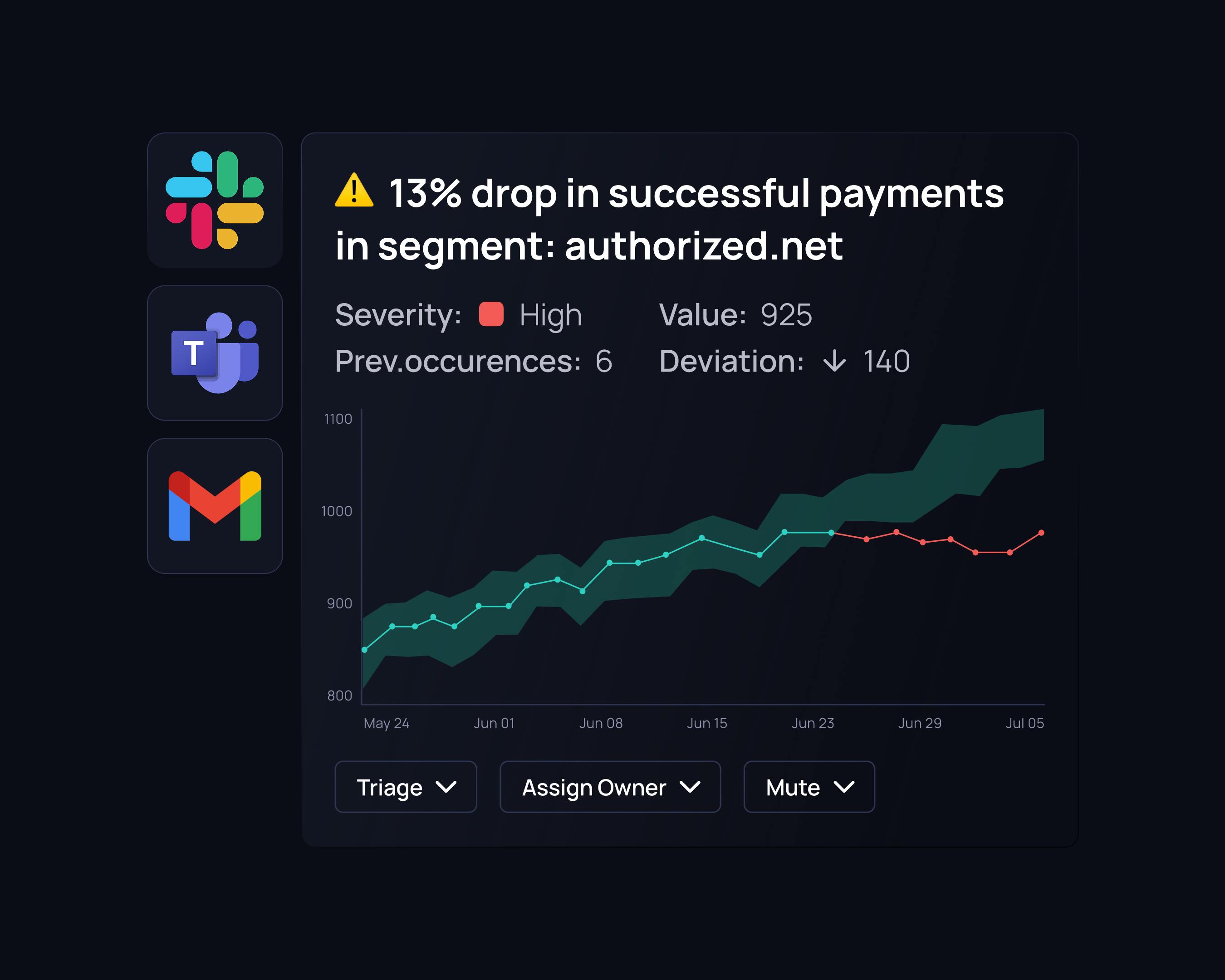
Instant, smart alerts
Validio groups related incidents and filters out false alarms, letting you focus on important alerts. Stay informed without the overwhelm.
Lineage
Understand the origin and impact of your incidents
Validio combines lineage and data quality monitoring for a complete view of your incidents.
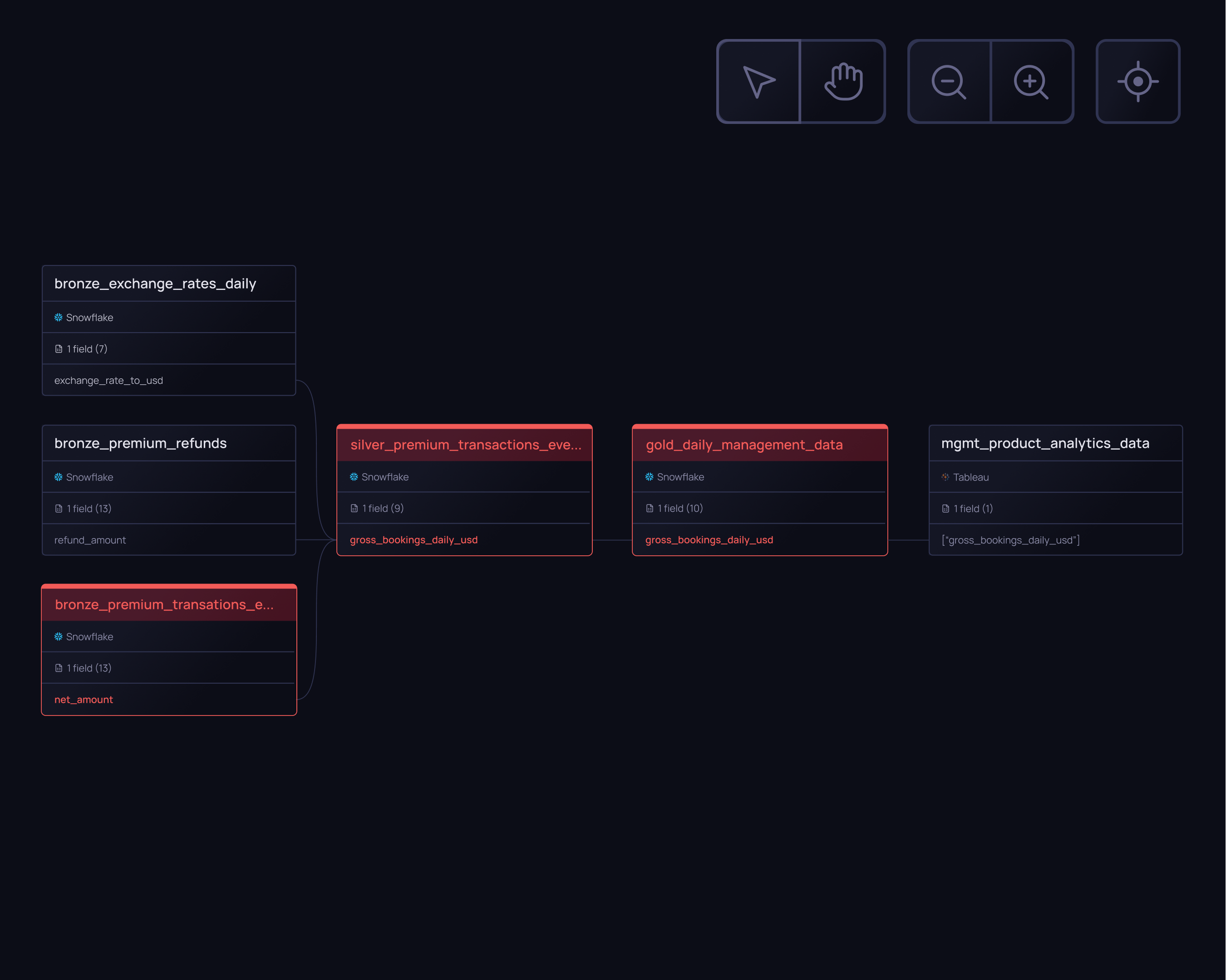
Field-level lineage
Get a map of your entire data journey, from streams to BI dashboards, to understand upstreams and downstream impact of issues.

Automated root cause analysis
We showcase data quality metrics directly in your lineage map and highlight the origin, severity, and impact of issues. Root cause analysis has never been easier.

dbt integrated
Sync your data tools easily by importing lineage from dbt. Validio alerts you about slow dbt jobs and provides details on tests and model runs.
Data catalog
Discover and understand your data
Get an overview of your data, understand how it’s used, and manage ownership.

Data asset overview
Obtain key insights on your data assets including popularity, utilization rate, quality, and schema coverage.
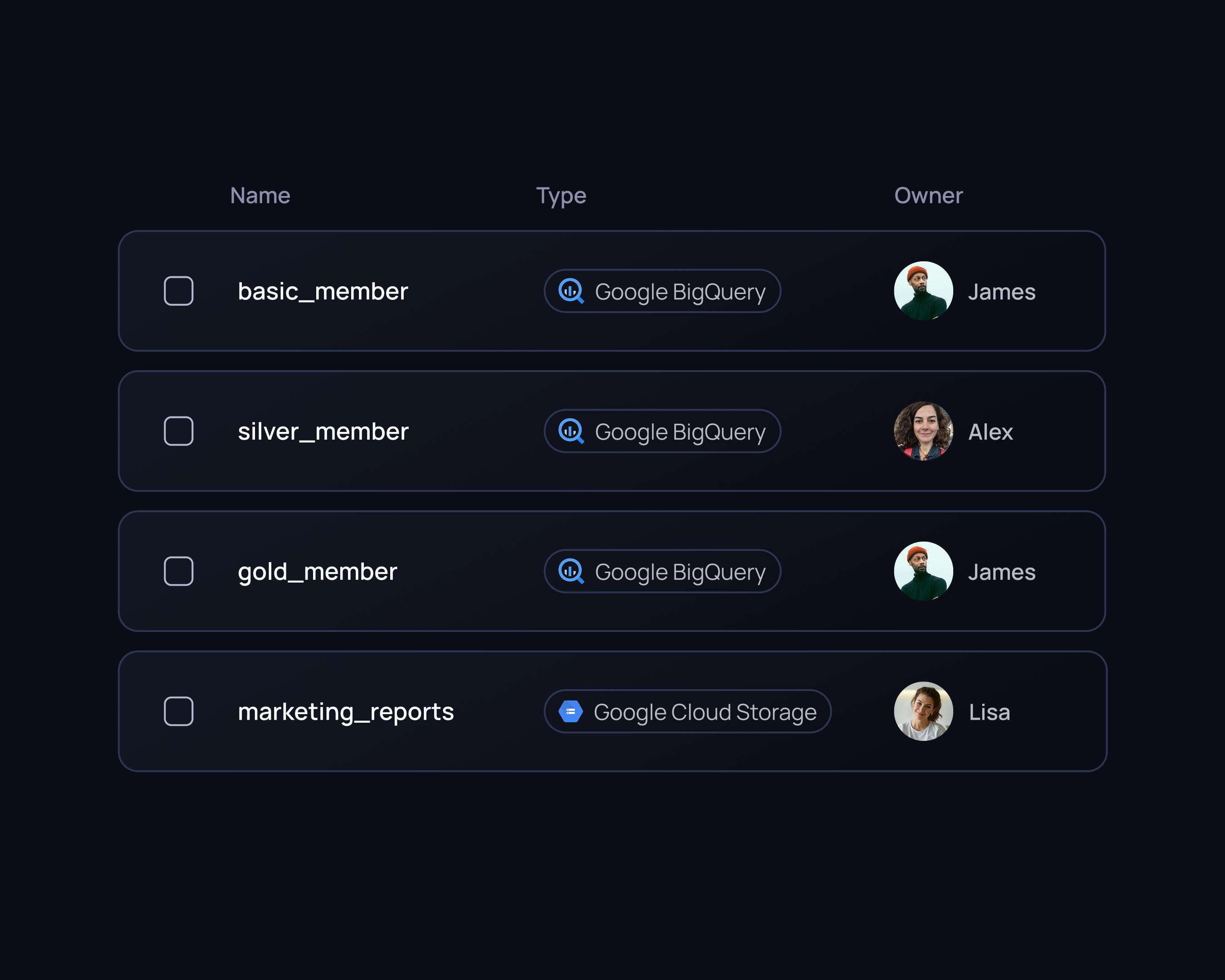
Data ownership & collaboration
Boost teamwork and data trust by promoting data governance and providing a central platform for effective collaboration across the organization.
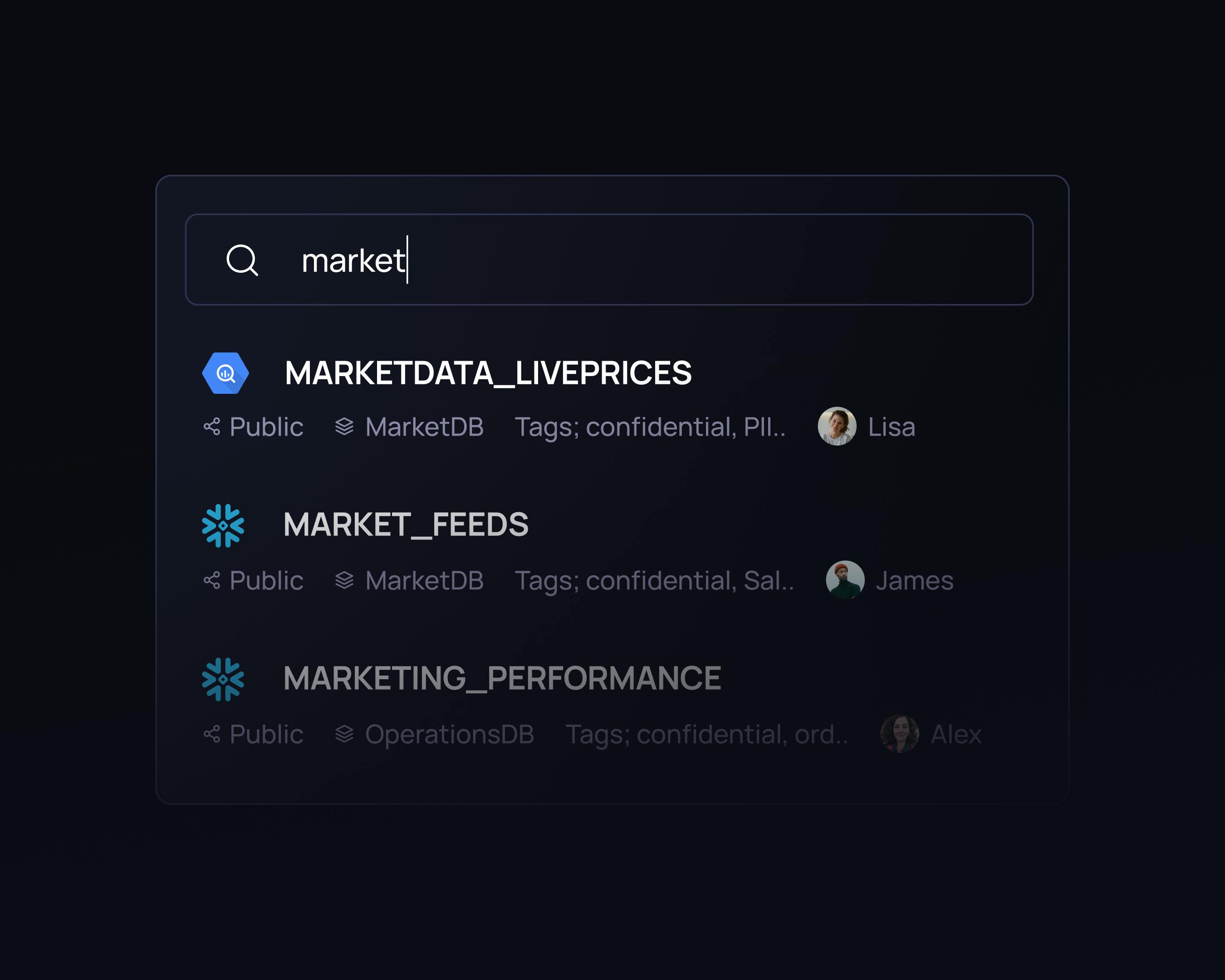
Search bar & metadata control
Find and filter the data you need based on metadata tags and descriptions.
Try it for yourself
Book a demo today
Fully integrated with every tool in your modern data stack
Validio integrates with your modern data stack. And if in some incredible instance you have a tool we don’t work with - just ask and we’ll build it for you.
Data sources
Automated monitoring of data in streams, lakes, warehouses, transformations, and catalogs









BI tools
Safeguarding business reports and dashboards


Notifications
Issue alerts directly where you work



Built for your needs
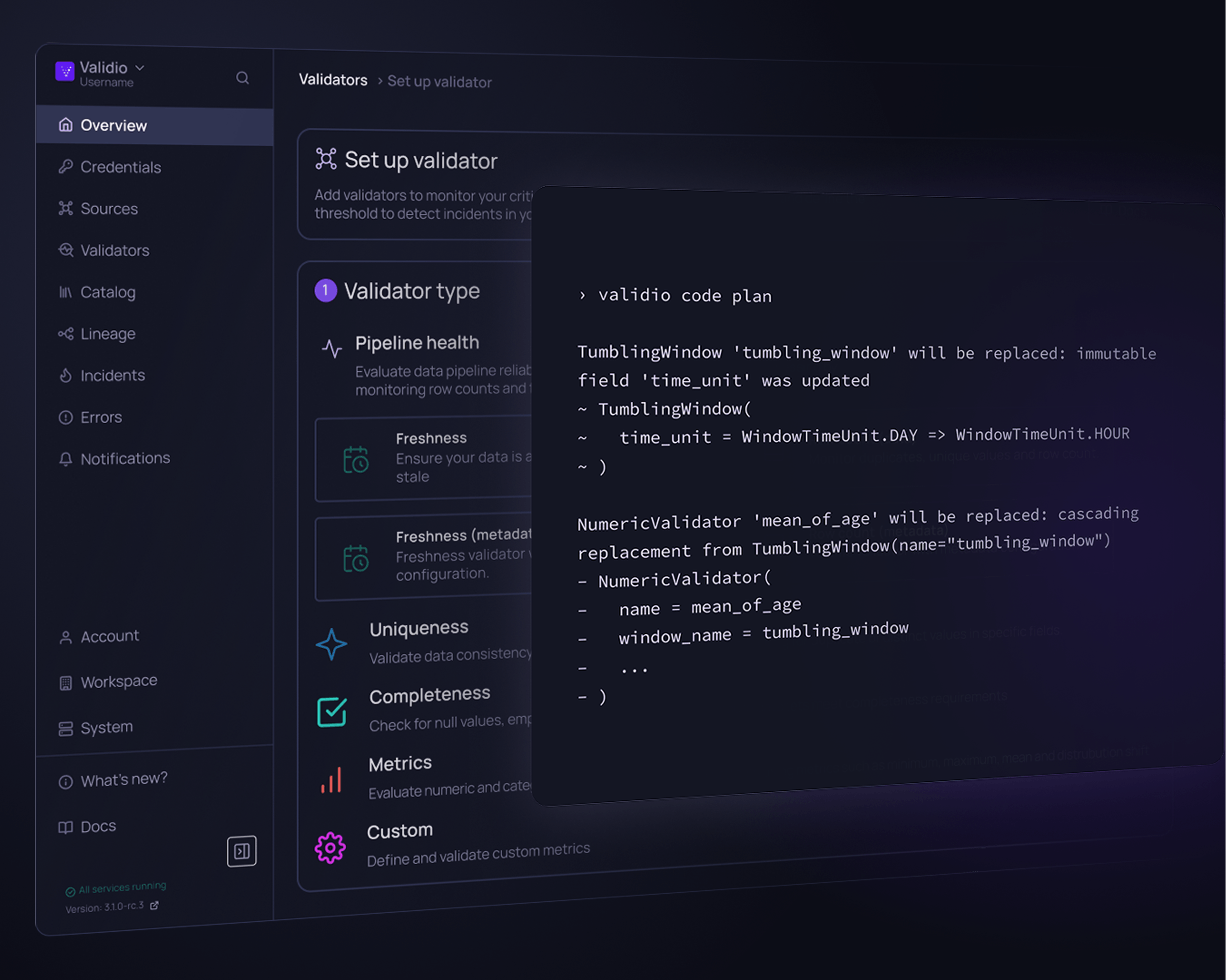
Multiple interfaces
Built for collaboration
Align data- and business teams with interfaces for all stakeholders.
Effortless configuration
Easy set up, zero maintenance
Get instant value from your data and stop wasting time on tool maintenance.

Security & compliance
Scalable security
Stay on top of security and compliance with enterprise grade standards.
Sleep better at night
knowing your data is right