


Company information
About Babyshop Group
Babyshop Group is a global premium and luxury retailer of children's clothing and products to the modern family. Babyshop Group offers more than 500 prestige brands along with a number of proprietary brands like e.g. Kuling, STOY and a Happy Brand.
Industry
E-commerce
Datastack





Key takeaways
Data validation across the modern data stack
Babyshop Group uses Validio to validate data used for operational machine learning use cases across their modern data stack.
Reduced time to discovery
Validio helped Babyshop reduce the time to discover and fix bad data from weeks to minutes, mitigating the risks of algorithmic marketing, and increasing organizational trust in data as a bonus.
Automated segmentation
One favorite Validio feature is dynamic segmentation; Babyshop Group uses it to validate website events data and loves how easy it is to set up and use.
"We use Validio to validate data for our most critical applications. Since we invest millions of EUR in algorithmic performance marketing, Validio becomes a central part in our line of defence against bad data."
Marcus Svensson, Head of Data Science at Babyshop Group
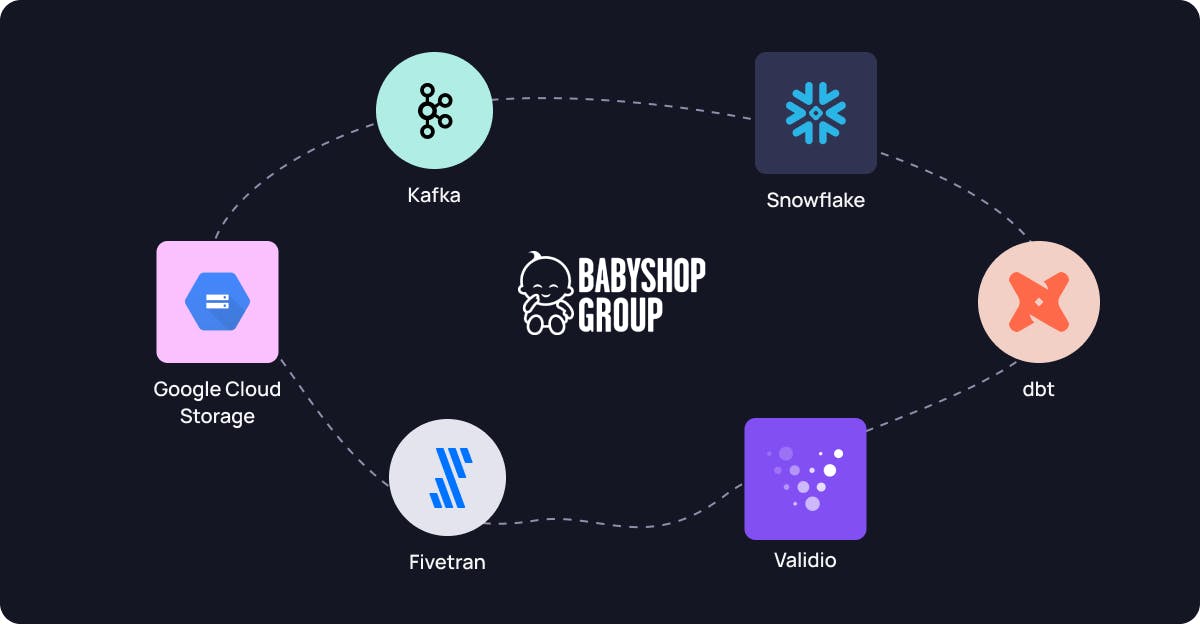
Can you describe Babyshop Group’s data stack and how Validio fits in?
Babyshop Group currently uses an ELT approach, with Fivetran, Snowflake and DBT. This is used for traditional BI-reporting, as well as data science and ML use cases. We use Validio in a number of different ways, some of the most important being:
- Validating GCS data used for CLV bidding in performance marketing: Here, we connect Validio to CSV files for both training and prediction data in buckets in Google Cloud Storage.
- Validating GCS data used for demand forecasting. Similarly, we connect Validio to CSV files for both training and prediction data in buckets in Google Cloud Storage.
- Validating site tracking data in Snowflake. Here we use Validio’s powerful dynamic segmentation feature on null value and row counts (more on this later).
What were some of the challenges Babyshop Group was facing before Valdio?
Machine learning plays a very central role in our business, which means we’ve made a very conscious decision to go broad with these use cases (as have many other e-com companies). Naturally then as our data maturity increases and we become more advanced, this increases the scope of the data team’s work. This in turn increases the need for more structure and automation for data quality if we want to continue to sleep well at night without bloating the size of the data team.
“When the ML models are critical for operational decision making—like for our performance marketing bidding based on customer lifetime value—the data quality quickly becomes very very hard to manage without good tooling.”
One example of this is in our machine learning models; it’s relatively easy to ensure high data quality during the development phase of the models, but once they’re in production there’s no guarantee that data will not significantly shift or deteriorate. When the models are critical for operational decision making—like for our performance marketing bidding based on customer lifetime value—the data quality quickly becomes very very hard to manage without good tooling.
How has Validio helped Babyshop Group?
“We use Validio to validate data for our most critical applications. Since we invest millions of EUR in algorithmic performance marketing, Validio becomes a central part in our line of defense against bad data.”
The first benefit from using Validio boils down to reduced costs of our operational decision-making. We rarely own the production of the data since that might happen in an ERP system or similar. Therefore, since we only consume the data, Validio has helped us get alerted when things don’t behave as expected. Without Validio, it could have taken us 1-2 weeks of consuming bad data before we would have noticed anything, with direct impacts on marketing costs, sales efficiency and forecasting accuracy. Since we invest millions of EUR in algorithmic performance marketing, Validio becomes a central part in our line of defense against bad data. Now, we get alerted right away if there’s an issue and can be much more proactive.
“Rather than stakeholders pinging us on Slack and asking ‘Hey why is this wrong?’ Validio has put us in the position to reach out to them proactively and say ‘We’ve discovered there’s an issue and we’re working on fixing it’ “
A secondary benefit of using Validio is a direct consequence of this proactivity: In the data team, we’re much better positioned to manage stakeholders. Rather than them pinging us on Slack and asking “Hey why is this wrong?” Validio has put us in the position to reach out to them proactively and say “We’ve discovered there’s an issue and we’re working on fixing it.” This is a great way of building trust in data in the organization overall.
Why did you choose Validio over another data quality solution?
The first decision we had to make was whether we would build or buy a data quality platform. In hindsight, I can say building this ourselves would have been infeasible from both a competence and resource perspective. Some of Validio’s features would have been fairly straightforward to implement ourselves (like statistical tests, we are a data science team after all!). However, the performance, scalability, reusability and usability of Validio would have been impossible to do ourselves. Also, specific features like dynamic segmentation and validation of individual sub-segments of the data is very powerful and very technically complex to implement.
Second, the Validio team is very technically competent which has built high confidence and trust on our end. The problems I face in my role are deeply technical but the Validio team understands them right off the bat and do everything they can to help me. They’re also extremely open to product feedback and are already working on implementing some of our suggestions.
What is your favorite Validio feature?
It is definitely segmentation which I’ve mentioned a few times. Segmentation helps us analyze individual sub-segments of data individually in a dynamic way. It’s not a revolutionary concept from a BI perspective, but from a data quality point of view it is!
The feature is very useful to validate the quality of website tracking data. There are many different event types (page view, add to cart, order placed, etc) and the data structures vary. We load everything into one table and then segment on the event type field in combination with the country field. It’s a very nice way of making sure the data quality is okay without having to manually create a table for each event type. This enables us to see that perhaps in Germany there’s issues with one type of click event being empty. With millions of events per day this would have been impossible to discover without segmentation!
“[Segmentation] enables us to see that perhaps in Germany one type of click event is empty. With millions of events per day this would have been impossible to discover without segmentation!”
What advice would you give to other data teams who are just getting started on their data quality journey?
I’d say it’s most important to just start somewhere. It might sound obvious, but there’s a lot that can be gained from implementing a data quality platform starting with the data sources where there’s “most to lose.” Then, if you implement that validation in a scalable way, it’s easy to expand data validation to other use cases.
Want to try it out?