



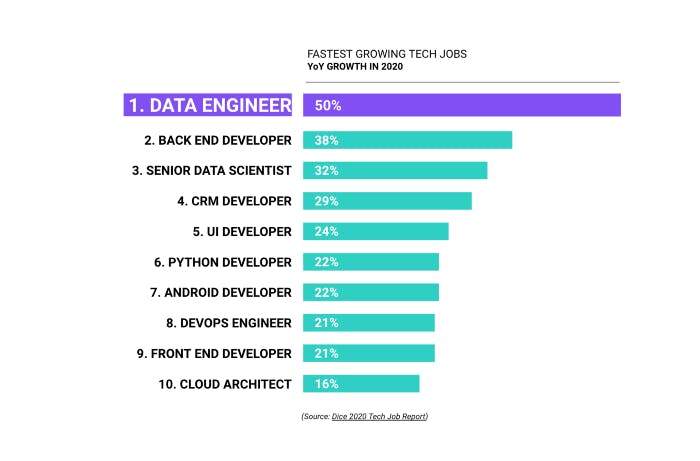
Dice’s 2020 tech jobs report cites data engineering as the fastest-growing job in tech in 2020, increasing by a staggering 50%.
But this “unicorn data scientist” expectation still continues to live strong in many circles. Here’s a great article by Chip Huyen about the topic. It’s one of the best takes on this pain point that I’ve seen in a long while. We need defined roles and realistic expectations, otherwise, we’ll be disappointed in project outcomes.
You can rest assured that the influx of data engineering will not regress anytime soon. This is something that we’re witnessing every day at Validio.
The rise and evolution of the data engineer
But let’s get back to the fastest-growing job in tech: data engineering.
It was in the early 2010s — almost exactly 10 years back — that the then-nascent term “data engineering” started to pop up in modern highly data-driven scaleups and fast-growing tech companies such as Facebook, Netflix, LinkedIn and Airbnb. As these companies harnessed massive amounts of real-time data that could provide high business value, software engineers at these companies had to develop tools, platforms and frameworks to manage all this data with speed, scalability and reliability. From this, the data engineer job started evolving to a role that transitioned away from using traditional ETL tooling to developing their own tooling to manage the increasing data volumes.
As big data evolved from a much-hyped boardroom buzzword to actually becoming reality, data engineering evolved in tandem to describe a type of software engineer who was obsessed about data; from data infrastructure to data warehousing, data modeling, data wrangling, and much more.
As Matt Turck notes in the latest Machine Learning, AI and Data Landscape analysis:
"Today, cloud data warehouses (Snowflake, Amazon Redshift and Google BigQuery) and lakehouses (Databricks) provide the ability to store massive amounts of data in a way that’s useful, not completely cost-prohibitive and doesn’t require an army of very technical people to maintain. In other words, after all these years, it is now finally possible to store and process Big Data."
The cloud has grown into something very powerful when it comes to harnessing data. As noted by Zach Wilson: a lot of data engineering tasks that were cumbersome in the Hadoop world are simpler to do with tools like Snowflake or BigQuery. They allow you to do what took hundreds of lines of Java in dozens of lines of SQL.
As we’re finally realizing the true potential of big data beyond the hype, data engineers have become a hot commodity in any modern data-driven company no matter size — from startups and scaleups to large enterprises.
Everything is trending towards a bright future for data engineering
In addition to the highly quoted Dice’s 2020 tech jobs report — there’s plenty of statistics showing that the momentum for data engineering is palpable with no signals of stagnation.
E.g. Mihai Leric analyzed in his blog post “We Don’t Need Data Scientists, We Need Data Engineers” from January, which made waves in the data startup and community, that there are 70% more open roles at companies in data engineering as compared to data science. He did this analysis based on the data roles being hired for at every company coming out of Y-Combinator since 2012.
Furthermore, the Seattle Data Guy has in a recent blog post found numbers that show that as of May 9th, 2021, with over eight thousand salaries reported, Indeed.com indicates that data engineers make $10,000 more per year than data scientists.
The benefits of data engineering do not stop at pay alone. A study from The New Stack indicates that there is less competition for data engineering roles than other tech positions. The New Stack found that for LinkedIn and Indeed.com job posts, for every open data science position there were 4.76 viable applicants, while data engineering roles experience only 2.53 suitable competitors per job opening. Nearly, doubling the chances of obtaining a data engineering role for applicable candidates.
So it’s safe to say that investing in data engineering capabilities is not a bad idea if one wants to ensure future employability and be highly attractive in the tech job market.
The next evolution of the data engineer
In some data circles, some are already talking (in a somewhat sarcastic tone) about the “downfall” of the data engineer and the next evolution of the role. There’s no doubt that we’re starting to see new roles branching out from data engineering such as the “Analytics Engineer”, coined by the dbt Labs team. You can read here an article I wrote back in June about the topic.
The analytics engineer is an example of natural evolution, as data engineering will most likely end up in multiple T-shaped engineering roles, driven by the development of self-serve data platforms rather than engineers developing pipelines or reports.
Looking into the crystal ball into the future development of the data engineer role — the data engineering domain will be too big for one data engineer to cover all of it, sure the unicorn data engineer exists but it is very rare to find one.
Not that long time ago, a data engineer was expected to know and understand how to use a small handful of powerful and monolithic technologies to create a data platform. Utilizing these technologies (e.g. Hadoop, Spark, Teradata, Informatica, Vertica to name a few) often required a sophisticated understanding of software engineering, networking, distributed computing, storage, or other low-level details. A data engineer’s work would be devoted to cluster administration and maintenance, managing overhead, and writing pipeline and transformation jobs, among other highly technical tasks.
With the emergence of modern cloud infrastructure and as we’re moving more and more towards decentralized data teams, self-serve data platforms, data meshes, etc, we’re also seeing data engineering becoming more like an internal platform team, optimizing various dimensions of the data stack.
But what is data engineering today?
A bit like the Modern Data Stack (the buzzword of 2021), it feels like data engineering is something of a moving target to define. E.g. a Google search for “What is data engineering” gives over 128,000 unique results as of October 2021. If you just scroll through the answers on the first result page, you get pretty varied answers when it comes to defining the topic.
So how would I define it? Data engineering is the development, implementation, and maintenance of infrastructure, systems and processes that take in raw data and produce high-quality, consistent and reliable data flows that support downstream use cases like BI, analytics and ML. Data engineering lives in the intersection of data management, DataOps, data architecture, orchestration, and software engineering.
In other words, data engineering produces reliable data that serves the business with predictable quality and meaning, built on the top of infrastructure and systems that support this data, from real-time streaming to batch data pipelines and subsequently from operational data in motion use cases to analytical data at rest use cases.
Data engineers are the people who move, shape and transform data from the source to the tools that extract insight — ensuring that data can be trusted and is of expected quality. In many ways, data engineers are the heroes in data-driven projects, the ones who preserve the credibility of BI, analytics and protect ML models.
Data engineering today = data pipelines?
At the end of the day, the biggest task data engineers currently spend doing — and is the beating heart of data engineering — is building data pipelines. Collecting and ingesting accurate and trustworthy data is naturally key for any data-driven organization.
The majority of data pipelines and data processing has been batch-based in the past. Data has been transported between systems in batch ETL snapshots, and data has been processed in a periodic cadence, which is managed by a job scheduler (Airflow, Luigi, etc). After many years in the making, we are now seeing a gradual shift to both real-time data pipelines and real-time data processing systems. As McKinsey notes, the costs of real-time data messaging and streaming capabilities have decreased significantly, paving the way for mainstream use. This development will be interesting to follow.
Batch or real-time, data engineering systems and outputs are the backbones of successful data analytics and data science. Data pipelines that move data from one place to another have become the nervous system of the modern company and subsequently data reliability and quality the beating heart. We hear at Validio time and time again how poor data quality is a tax on everything modern data-driven companies do.
But is data engineering all about building data pipelines? Naturally, data pipelines are a big part of data engineering. However, most definitions over-emphasize data pipelines — ignoring the fact that they should be perceived as a means to an end and not the sole purpose of data engineering.
So data engineers also do much more than building data pipelines and they come in different flavors. Let’s discuss that next.
Data engineers come in different shapes and colors
What a data engineer does depends on the organization and the individual. As Zack Wilson has noted, data engineers usually come in two flavors:
- The businessy one. Loves Python and SQL. Really focuses on business value. Dashboarding gurus and communicators. They often ask “what is the impact?”
- The techy one. Focuses unconditionally on engineering best practices and scalability. They’re software engineering gurus and builders. They often ask “is this architecture or infrastructure scalable?”
Both definitely have their place, however, in this post, we’re wearing a bit more the glasses of the latter data engineer type, e.g. the techy one.
A data engineer, quite obviously, applies the discipline of data engineering into an organization — taming raw data and ensuring the data is useful for downstream users, like e.g. data scientists, data analysts and ML engineers.
If looking at the highly quoted data science hierarchy of need pyramid below by Monica Rogati from 2017, especially the collect and move/store dimensions fall in the data engineers territory and large parts of the explore/transform dimension (depending on the organization).
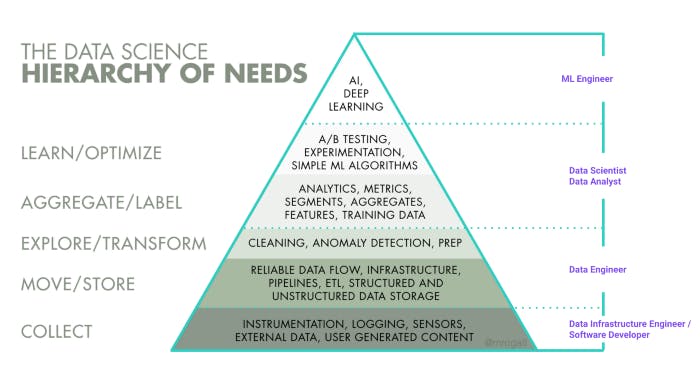
In simplified terms: a data engineer manages the data engineering lifecycle from source systems to the serving of data for downstream use cases (such as BI, advanced analytics or machine learning as mentioned before). They’re responsible for the data platform/data infrastructure and that data flows seamlessly through the organization and e.g. data analysts and data scientists have the tooling, datasets and guidelines needed to execute their work efficiently.
Data engineers also focus on making data accessible. What do we mean by this? As the Seattle Data Guy notes — data engineers often build data pipelines so that it’s easy to re-model the data, which makes it easy to understand and accessible for e.g. data analysts or data scientists who are maybe not too familiar with languages such as SQL. Thus needing a simplified dataset so that they can actually access and interact with certain data assets. So depending on the organization, data engineers also spend time cleaning, wrangling and pre-processing data — in order to make data easier to access for colleagues who might not be so familiar with how to manage and/or manipulate data.
It’s important to know that this varies widely depending on organizations and data analysts and data scientists come with varied skill sets in terms of their level working with e.g. SQL or ability to work with Pandas and other tooling that is used for data manipulation.
A real-world example from a fast-growing scaleup with a modern data team
As a concrete example, online grocery company Oda’s data team — which is one of the fastest-growing scaleups in the Nordics — have below done a generalized visualization in a Medium article of how they’ve defined the tasks of the data analyst, data scientist and data engineer roles in broad strokes.
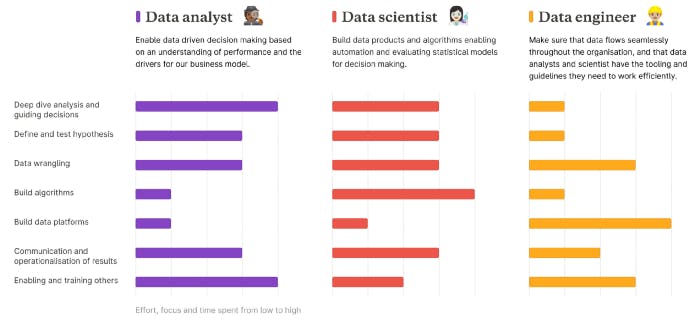
Here we can see, in the context of a fast-growing European scale-up with a modern data team and data infrastructure, that a data engineers top 3 high-level focus areas are:
- Building and maintaining the data platform/data infrastructure
- Data wrangling and ETL/ELT pipelining
- Enabling and training others in the data team and the wider organization
The third point about enabling and training others might be surprising for some. Even though many data engineers might want to spend more time copy-pasting from Stack Overflow (wink wink), based on our experience data engineers spend a significant time interacting with people. They are conversing on what different teams’ needs are and helping them understand what the limitations are on e.g. different datasets or data streams and what time is needed to pull out datasets that they’re asking for among many other things.
When discussing what data engineers do it’s important to also mention maintenance. For e.g. any data pipeline or data model a data engineer creates they also end up creating a lot of maintenance tasks for the future. These tasks are often coupled with areas such as pipelines failing because of e.g. upstream changes in an application or API, which is more common than one might think. This is one of the reasons many companies are moving towards the automated connectors space and why startups such as Fivetran and Airbyte, who are fighting in this space, have raised significant funding rounds lately. Having to maintain and keep connectors up is a very expensive and time-consuming (read: non-stimulating) task, hence many data-driven companies are happy to outsource it.
Being a data engineer = shiny new tools?
Regardless of the Cambrian explosion we’ve lately witnessed in modern data infrastructure tooling space, the data infrastructure landscape is dramatically less complicated to manage and deploy nowadays compared to 10 years ago.
Recent tools and platforms greatly abstract complexity away from data engineering and simplify workflows, and as a result, the role of a data engineer is evolving from being an expert in a handful of complicated technologies, toward balancing the simplest and most cost-effective best-of-breed solutions that deliver real tangible value for the business with time-to-value as a guiding star.
As Petr Janda, CTO at FinTech scaleup Pleo notes in his recent Medium post, it doesn’t take months to build a company-wide analytics data stack anymore. Today, you can funnel large volumes of data to your cloud data warehouse and put it into action in days. All of this is made possible by the modern cloud data infrastructure, e.g. the Modern Data Stack. But as Petr notes, despite these newly acquired superpowers, it’s not a silver bullet. There are several challenges that you need to address to set it up successfully for long-term success.
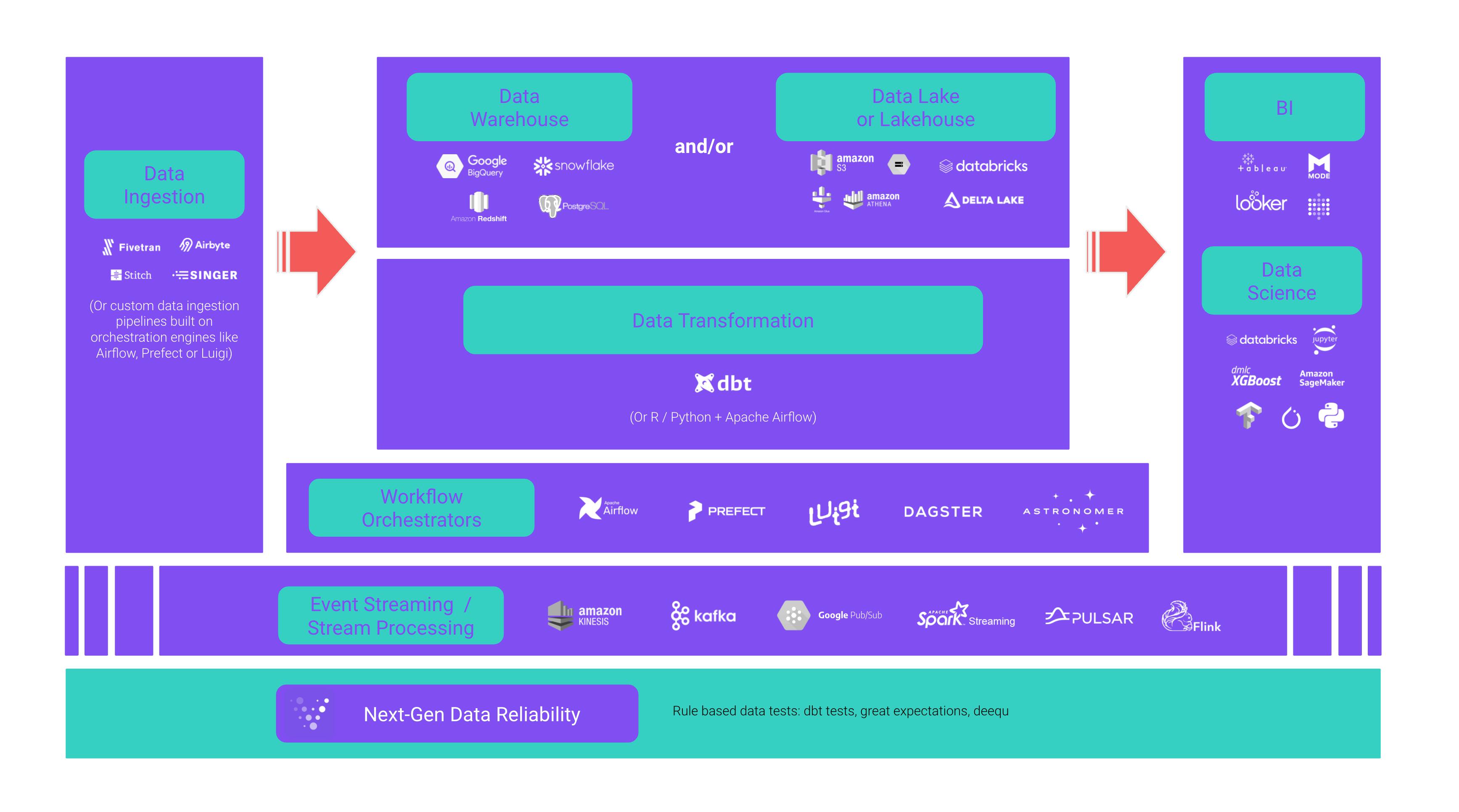
A question I hear more and more (and I see heated discussions about on e.g. Hacker News or Reddit) is what technologies should a data engineer master?
More often than not this might really be the wrong question to ask.
The data engineer is expected to balance the technology hype with the underlying complexity to create agile data architectures that evolve as new trends emerge.
I’ve seen countless times how people get distracted by shiny objects and think that data engineering is the equivalent of using the latest “X factor technology” (X factor = Databricks, Snowflake, dbt, Airflow, Fivetran, Airbyte, etc., etc.) — especially in today’s data ecosystem where tools, technologies, and practices are evolving at a blinding rate, to say the least.
Data engineering is not — and never has been — about any particular technology. Data engineering is about designing, building, and maintaining systems and data platforms that incorporate best-of-breed technologies and practices in an agile and cost-effective way. Tools need to provide value, the right type of deployment optionality and abstract complexity away from data engineering.
As Bessemer Venture Partners highlights, integrations across tools are important for enhancing the usability of a particular piece of software. For modern cloud data infrastructure and the modern data stack, such interoperability is a must. Data moves through pipelines from source to output, interacting with and being manipulated by a range of tools in the modern data stack. No new technology that is targeting to abstract complexity away from data engineering can act as an isolated island.
Does data engineering exist for the sake of data science?
Short answer: no.
But data engineering as a core part of any modern data-driven organization was for sure solidified at the latest when data scientists on the back of the most recent AI/ML-hype realized that they’re spending more time overcoming data challenges than doing actual data science.
I think most of us have heard about the over-quoted stat from 2016 how data scientists spend 80% of their time cleaning and wrangling data. Data scientists still spend about 45% of their time on data preparation tasks, including loading and cleaning data, according to a survey of data scientists conducted by Anaconda from 2020.

So data engineers came to the rescue. But during the past years, data engineering has evolved to so much more and I think we need more articles discussing data engineering’s right to exist without data science.
Final thoughts
The role of the data engineer will only get more prolific and important in organizations of all sizes, as we’re managing an ever-increasing amount of data sources and data pipelines in modern data-driven companies.
How to then measure a data engineering team?
Below are some very concrete high-level examples that data-driven organizations utilize:
- Data quality (amount of known or unknown data failures and anomalies that impact downstream teams or applications)
- Time-to-production (how long does it take to productionize new data sources and data streams)
- Data uptime (% of the time a dataset is delivered on time, relative to e.g. the expected frequency or mutually agreed SLA requirements)
Today, good data trumps more data in almost every single case. Want to assess a company’s data maturity? Ask how they evaluate the quality of their data, rather than how much data they have.
I want to disclaim that I’m not a data engineer myself. This post and the observations made are based on numerous discussions I’ve had with data teams — from fast-growing startups and scaleups to large publicly traded companies.