



In a survey by O’Reilly from 2019, 26% of the respondents with a mature machine learning practice stated poor data quality as the nr 1 bottleneck holding them back from further AI/ML adoption.
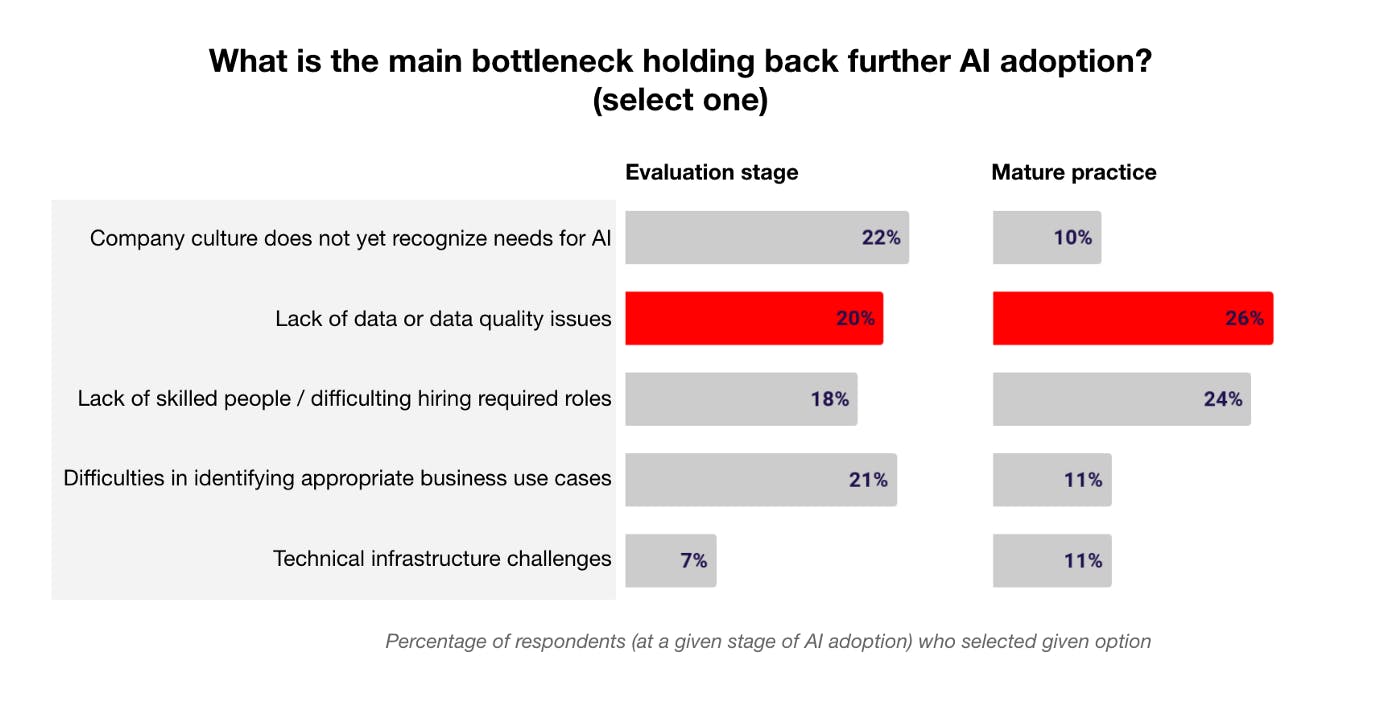
Fast forward to 2021 and the situation seems to only have worsened: 34% of the respondents in a recent Rackspace survey, which included 1,870 organizations in a variety of industries, stated poor data quality as the main reason for the failure of machine learning R&D, and another 31 percent said they lacked production-ready data.

We can see a multi-year plague emerging within ML, which is becoming a peril rather than a problem: data quality.
We need data engineers
The results from the January 2021 Rackspace survey highlighted how data engineering problems pose a significant problem for companies of all sizes. Data being siloed, lack of talent to connect disparate data sources, and not being fast enough to process data in a meaningful way… the list goes on.
Data engineers are the people who move, shape and transform data from the source to the tools that extract insight. Data engineers are charged with ensuring that data can be trusted — that it’s delivered consistently, on-time, and of the expected quality.
For such a critical role, we don’t think data engineers receive the love and appreciation they truly deserve. Data engineering doesn’t get the same hype or have the same number of prep programs as e.g. data science, yet it’s just as important. Many would argue that it’s much more critical today.
We believe that data engineers are the change agents and unsung heroes in a decade-long process that will revolutionize data. Unsurprisingly (at least for us), data engineering is the fastest-growing job in tech right now.
The pandemic highlighted our ML vulnerabilities
We’ve experienced first hand from companies such as Uber, Facebook and Amazon the impact performance issues can create for data-driven companies with ML models in production in critical operational settings.
The COVID-19 pandemic highlighted the need for companies to manage and monitor their data and models — as operational ML models around the world broke in early 2020 as a result of rapidly changing market conditions. In many ways, 2020 was the year when all data shifted and highlighted the need for continuous machine learning and data monitoring.
As a concrete example: Instacart experienced firsthand how their inventory prediction models went bananas as consumers rapidly changed their behavior at the back heel of the pandemic.
Instacart’s model accuracy went down from 93% to 61% — resulting in misguided and irritated shoppers with purchases that didn’t go through or deliveries that fell short of customer expectations.
Machine Learning vs Software Engineering
The process of developing machine learning models is often compared to the established process of software development. However, a key differentiator between the two lies in the strong dependency between the quality of a machine learning model and the quality of the data used to train or perform predictions. In short: traditional software development is deterministic. Machine learning development is probabilistic. This results in a two-edged state of existence for ML models.

On one hand, productionized machine learning models should in a perfect scenario get better over time. As the data they process increases, their predictive accuracy should also increase. On the other hand, models usually start to deteriorate when they’re productionized. Why? The main reason for this is usually tied to data drift. When a machine learning model is deployed into production, the top concern is usually the model relevancy over time. Is the model still capturing the pattern of the new incoming data, and is it still performing as well as during the design, training and testing phase? Data drift happens naturally as the real “dirty” world is always changing and different from a closed model training environment.
Data drift can result in serious and usually invisible machine learning system failures. The problem here is often that when traditional software systems fail, one usually gets a warning, e.g. systems crash or runtime error or 404. However, ML systems fail silently. Users don’t even know that the system has failed and might have kept on using it as if it was working. This often results in poor user experience and ultimately different levels of financial losses.
In the vast majority of cases, data quality issues (and the subsequent financial losses) occur behind the scenes in organizations and are not publicly exposed — in contrast to the data quality issue Hawaiian Airlines experienced in 2019 due to a software update glitch, which led to dozens of customers being charged hundreds of thousands of dollars in credit card fees for almost a week.

Data-driven companies should monitor and validate their data (at dataset and data point levels) proactively for both data quality issues and data drift. Data quality problems can e.g. stem from data values being broken (data is missing/incomplete, data is erroneous or just simply doesn’t fall within the expected ranges) or there’s a breach from expected schemas. Data drift happens when data that is being fed to the ML model in production diverges from the model’s training data or the distribution of the data (e.g. poor data quality) shifts so that that the model is no longer representative.
What every modern data team with ML models in production should be asking themselves is: are the data and statistical properties what we expect?
Your model was never your IP, it’s your data
ML quality requirements are high, and bad data can cause double backfiring: when predictive models are trained on (bad) data and when models are applied to new (bad) data to inform future decisions. Poor data quality is the archenemy of widespread, profitable use of machine learning. Together with data drift, poor data quality is one of the top reasons ML model accuracy degrades over time.
As ML models and algorithms are becoming increasingly commoditized the key differentiator is the data.
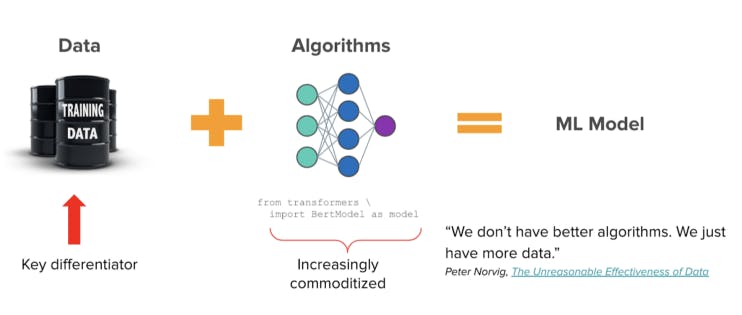
As we’ve started to distance ourselves from the AI hype that reached its peak at the end of the 2010s, modern companies are realizing that their ML models were never their IP; it’s their data and subsequently how they ensure the quality of the data continuously and in real-time.
One of the best-kept “secrets” to better model performance is high-quality data.
Google published earlier this year the research paper “Everyone wants to do the model work, not the data work”. Google’s team concludes in the paper that paradoxically, data is the most under-valued and de-glamorized aspect of ML — viewed as ‘operational’ relative to the lionized work of building novel models and algorithms. They conclude that intuitively, AI/ML developers understand that data quality matters, often spending inordinate amounts of time on data tasks BUT still most organizations fail to create or meet any data quality standards, from under-valuing data work vis-a-vis model development.
The persistent peril of poor data quality is by no means isolated to ML: it affects all data-driven decision-making, from BI tools and dashboards to customer experience optimization, business analysis, and business operations.
Who are the unsung heroes we don’t deserve but need to get us out from this peril?
You’ve guessed it: data engineers.