



In the first release of the semi-structured data support, Validio adds support for the following:
- Validate schema: Validio supports validation of a semi-structured schema. Because semi-structured data types have no predefined schema, Validio infers the schema from the existing data.
- Validate data: Any key-value pair inside semi-structured data can be validated just like any field. This is also true for key-value pairs deeply nested inside the data structure. However, you can validate the size of an array. For each array, Validio adds a computed field called some_array.length(), which you can validate like any numeric field.
- Validate semi-structured data from multiple sources:

What are semi-structured and complex data types, and why are they used?
Semi-structured data refers to data formats that do not conform strictly to the traditional tabular structure of relational databases, but they do have some form of organization containing tags or markers to delineate semantic elements and hierarchies. This kind of data sits between structured and unstructured data in terms of organization. A popular example of semi-structured data is JSON, as shown below.
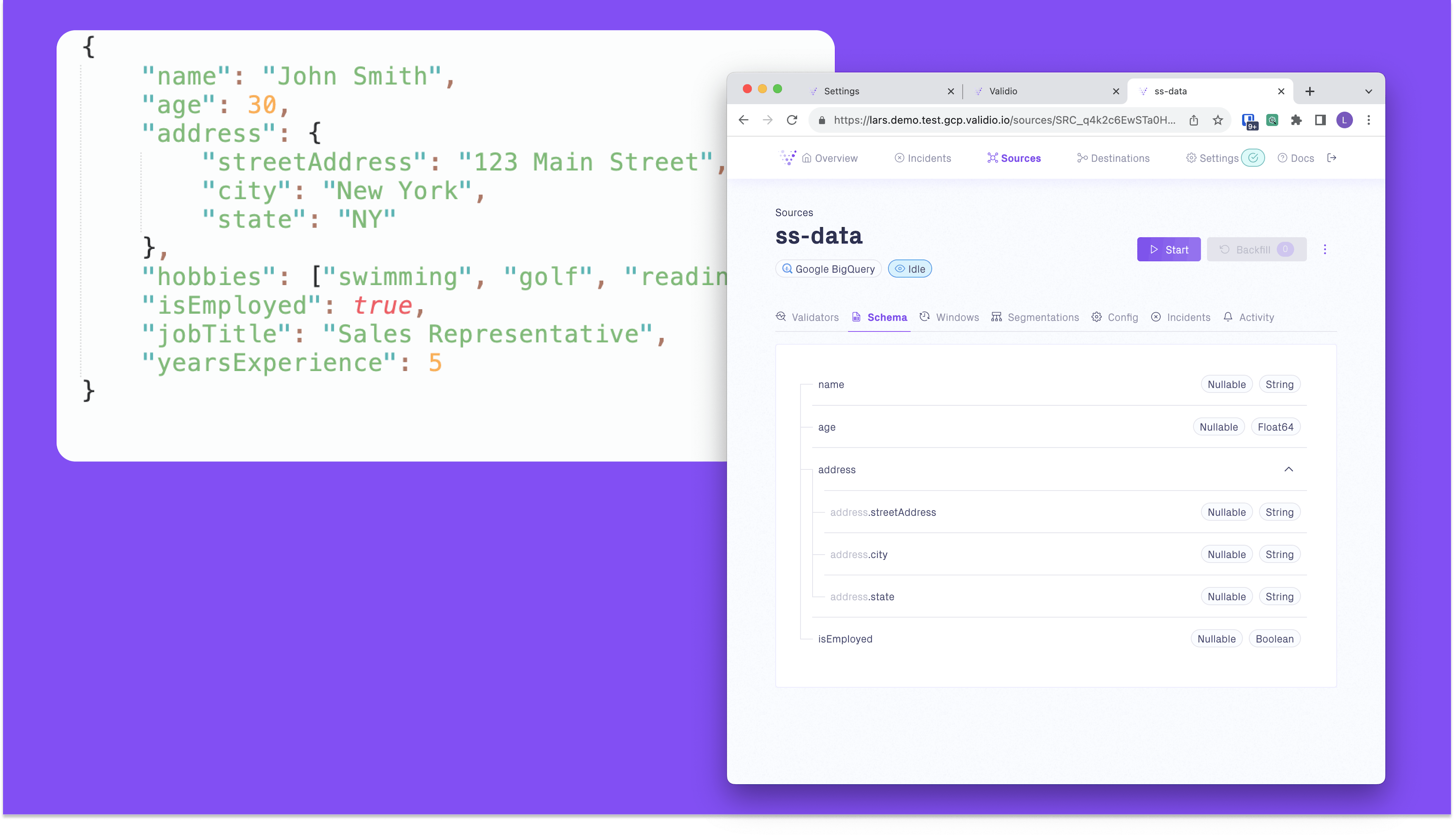
More and more services and applications use semi-structured or complex data types when communicating with each other (because of readability, compression, compatibility, ease of use, etc). Supporting this type of data in Data Warehouses, and other technologies for storing and analyzing data simplifies the entire process of data handling.
Complex data types, on the other hand, are versatile data structures that can encapsulate properties of both structured and semi-structured data. They can hold multiple data types in nested or repeated configurations. For instance, the RECORD in BigQuery is a complex data type, as it is structured but can also contain various nested and repeated data types within it.
Consider a scenario where you want to record a list of individuals and the cars they own. In a traditional relational data model, capturing this relationship would typically require two separate tables: one for 'people' and another for 'cars'. These tables would then be linked using primary and foreign keys. In contrast, with hierarchical and repeated data patterns, information about both individuals and their cars can coexist within a single dataset. This can provide a more intuitive representation, and other advantages such as more optimized storage and query performance.
Common issues in semi-structured data
The schema in semi-structured data is not enforced. For example, in JSON, the records {"a": "b"} and {"a": [1,2]} can exist in the same data set, even if the key “a” holds a string in the first record and an array of integers in the second.
Another example is that it’s allowed for new keys to suddenly appear or be removed between different records.
This flexibility is one of the advantages with semi-structured data, but also one of the challenges.
For structured data, the constrained schema naturally acts like an agreement between the producer and consumer of the data. Conversely, for semi-structured data, there is no such agreement intrinsically. Note, however that there exist other tools and frameworks that facilitate this, such as JSON Schema.
Without a well-defined, or even enforced schema, mismatches between producer and consumer can easily occur and cause severe downstream issues.
A common example is when semi-structured data is ingested raw into a Data Warehouse and then flattened using, for example, SQL Views or Procedures. Even if only one record of incoming data has a different schema than expected by these Views or Stored Procedures, it might completely break the pipeline.
Validio alerts you as soon as any issues occur
Validio can continuously monitor and validate if a semi-structured schema conforms to expectations defined at initial inference. You can then tailor the expectations on the schema further if required.
For example, if you have a JSON field that contains an array of objects, each object should have the same number and name of fields. Validio can infer the expected schema from the first batch of data and compare it with the subsequent batches. If there are any changes in the schema, such as missing or extra fields, Validio will alert you accordingly.
Validio validates nested data
In addition to validating schemas, Validio can validate data at any level in a nested structure, just as if it was a regular field in a flat table. For example, if you have JSON data containing dates, each date should have the same format and be within a valid range. Validio can check if there are any invalid values or formats in the nested fields and notify you accordingly. You can also apply various other validation rules to the nested fields, related to uniqueness, completeness, consistency, accuracy, etc. Validio will then verify if the nested fields meet these rules and alert you of any issues.
Use cases for validating nested data
To illustrate this, let’s look at some use cases where Validio identifies common errors specifically related to nested fields:
- Missing or extra keys: Sometimes, keys are missing, or new keys are unexpectedly added inside a nested structure, e.g. in JSON. Validio can detect if there are any such discrepancies in the semi-structured schema and alert you accordingly.
- Missing or extra array elements: Sometimes, you have expectations on the number of elements in an array. You might e.g. expect an exact number of elements or a range of elements, or you might just know that there should be more than zero elements. Validio can validate array length, just like any other numeric field.
- Invalid values or formats: Sometimes, nested fields may have values or formats that are not valid or consistent. For example, if you have a JSON field that contains an array of dates, each date should have the same format and be within a valid range. Validio can check if there are any invalid values or formats in the nested fields and notify you accordingly
Benefits of validating all data in one place and as early as possible
One of the benefits of validating all data in one place and as early as possible is that it reduces the risk of propagating errors downstream. For instance, imagine that you have a web API that sends JSON data to your BigQuery Data Warehouse. If there is an error in the JSON data, such as a missing field or an invalid value, it will affect your Data Warehouse and any downstream processes or applications that rely on it. By validating the JSON data before it enters your Data Warehouse using Validio, you can catch and fix the error at the source and prevent it from affecting your entire data pipeline.
Another benefit is that it simplifies the communication and collaboration between the data producers and consumers. For example, suppose you have a service that produces JSON data and another service that consumes it. In that case, you can use Validio to define the validation tests for the JSON data, which acts as a contract between the two services. This way, you can ensure that the data meets the expectations of both parties and avoid any misunderstandings or conflicts.
How Validio can validate non-flattened or hard-to-reach data
Some data is never flattened or flattened in a place that is hard to validate. For example, semi-structured data comes from an API into BigQuery, which uses BigQuery’s nested and repeated structures to keep the nested structure. The data might then be further transformed before it is flattened or not flattened at all. With support to validate nested and repeated data, Validio can validate this type of data anywhere in its pipeline.
For example, if you have nested JSON data representing people and their cars, you can use Validio to validate the data at any level of nesting. You can check if each person has a valid name, age, and gender and if their cars have a valid model, color, and price. You can also check for any duplicates, missing values, or outliers in the data. Validio will then report any issues or anomalies in the data and help you resolve them.
Closing thoughts
If you want to validate your nested data with ease and confidence, try Validio. It helps you ensure that data is accurate, consistent, and complete and alerts you of any issues or anomalies. Validio’s deep data observability platform lets you validate all your data in one place and as early as possible. Explore our website or request a demo today to learn more about Validio and how it can help you with your data quality needs.
Curious?
Learn how Validio can catch issues in any data format, in any location, and in real-time.