


In today's data-driven landscape, the correctness of data is crucial. But not all data quality issues are created equal. Let's look at "loud" and "silent" data quality issues, understanding their nuances and impact on data observability and quality.
Loud data quality issues: a roar impossible to ignore
Picture this: tables with vast amounts of missing data, glaring inconsistencies, or tables that haven't been updated in months. These are the loud data quality issues that happens to all data in a data asset, making the issues relatively easy to spot, and therefore chances that they will be resolved are quite high.
Consider these examples:
- A broken pipeline causing a significant drop in data volumes
- An error in a dbt model causing Null values in a whole column
- A schema change resulting in downstream broken data products
- A broken pipeline causing a data table to no longer update
Resolving such issues is important, and here's where many data observability and quality tools shine. They target and fix these loud data quality issues. Often, they do this by focusing on metadata level checks, like freshness, volume and schema validation. These tests are done on the entire data table as a whole. We refer to this as “shallow data observability” or “shallow data validation”. This is because it doesn’t go deep enough in terms of segmenting the data into sub-segments, and because the types of validations isn’t advanced enough to uncover silent data quality issues.
The sneaky nature of "silent" data quality issues
Unlike their loud counterparts, "silent" data quality issues operate incognito, often staying—you guessed it—silent. These subtle issues might appear harmless, but can result in significant errors in operational decisions if the data used to inform those decisions contains silent data issues. With silent data quality issues, the downside can be multiplied, because errors might exist in the data for a long time without being noticed.
But what’s worse is that silent data quality issues run the risk of damaging data trust within an organization. Data consumers that use data on a regular basis might be horrified to find out that weeks or months of decisions have been based on incorrect data. Aside from having negative business consequences, it also erodes trust and causes lower data adoption in the longer term.
Let’s have a look at some examples of silent data quality issues. Consider the following:
- A table collects website data consolidated from multiple markets. The website data collection from one of the smaller markets has gone down, resulting in no data being collected from that market. This goes undetected since the table as a whole is still receiving data of reasonable volume. Shallow data validation that looks at volume and freshness on the whole table will not notice these silent issues.
- A bug in a dbt model causes a currency error in only a subset of the data from the German market. Since the German market only accounts for 5% of the total data volume in this case, the data error is not noticeable in the averages on the whole table.
- A company is using customer data to generate personalized discount offers based on machine learning. Over time, the distribution of the customer data starts to drift, which causes the models to become less accurate. Shallow data quality checks will not be able to look at the nuances of the data distribution in this manner.
In summary, data validation aimed at identifying loud data quality issues will not catch any of these silent data quality issues. The silent data quality issues are affecting subsets of the data whereas the loud data quality issues check the data on an overall and aggregated level.
Worth noting is also, that if your company is relying on data for business critical decisions and operations, the need to know about silent data quality issues is much higher than if the data isn’t critical for your business. Data observability that can successfully identify silent data quality issues is referred to as “deep data observability.”
Why does it matter?
Differentiating between silent and loud data quality issues becomes important when selecting the right tooling. "Loud" data quality issues are easily noticeable due to their nature and can be caught relatively easily with custom-built solutions or open-source tools like Great Expectations. On the contrary, the detection of "silent" data quality issues requires more sophisticated methods and tooling to identify.
OfferFit—a lifecycle marketing platform—is an example of a company that successfully made a transition away from Great Expectations to Validio to handle not only “loud” data quality issues, but also “silent” ones. As OfferFit experienced, effective insurance against “silent” data quality issues requires a different level of automation and sophistication. Let’s have a look at what this means in practice for deep data observability that can catch silent data quality issues.
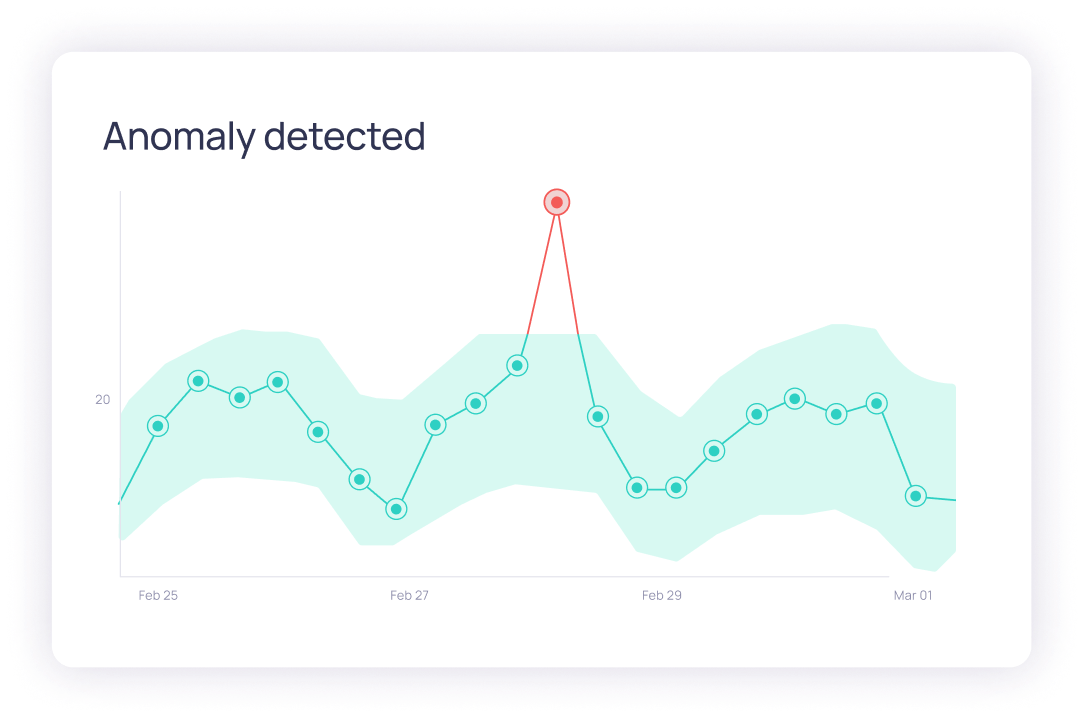
State-of-the-art algorithms
Real data changes over time. Deep data observability is able to identify patterns in the data, including seasonality patterns, and warn data teams if something out of the ordinary happens. Deep data observability is using dynamic thresholds to understand what data is expected and what is an anomaly.