Heroes of Data is an initiative by the data community for the data community. We share the stories of everyday data practitioners and showcase the opportunities and challenges that arise daily. Sign up for the Heroes of Data newsletter on Substack and follow Heroes of Data on Linkedin to make sure to get the latest stories.
High-growth companies inevitably outgrow their systems as business needs change, and data stacks are no different. We’ve previously followed scaleups like Hedvig on their journeys to upgrade their modern data stack tolling, and in this article, we’ll turn to Budbee who were in a similar position. Here, we’ll follow Data Engineer Ji Krochmal and hear about his learnings along the way. Let’s dive in!
An introduction to Budbee
Budbee is a consumer-centric tech company with a clear vision to create the best online shopping experience–and do it fully sustainably. The company was founded by their CEO, Fredrik Hamilton, in 2016, and has been on an impressive growth journey ever since, to expand their logistics network and delivery services. Some of Budbee’s merchants include retail giants like H&M, Zalando and Asos. To fulfill their sustainability vision, Budbee uses fossil-free and renewable fuels, performs climate compensation, and lastly, has advanced route optimization and fill rate capabilities. Data and analytics therefore, is at the very heart of what Budbee does.
What’s more, Budbee has an exciting and bright future ahead: in September of 2022, Budbee announced the intention to join forces with Instabox, forming an even larger company called Instabee—we sure can’t wait to see what they will accomplish together, also on the data frontier.
Now, let’s turn our gaze to the star of our show: the data engineer.
Who is Ji Krochmal?
Ji is a Senior Data Engineer and Tech Lead at Budbee with a long and solid track record of data engineering roles. His tech interest was built on a foundation of embedded development, and now he (in his own words) “thinks about data all day, every day.” Although embedded development is quite far from the often abstract concepts of cloud-based data engineering and ETL, in his own words he feels that “seeing the machine through the code” has helped him absorb and implement technical concepts, and he has been able to consistently deliver results for large and small organizations through a practical low-level approach. A certain fearlessness (“we can just make this in bash”) has also helped, even though maintainability might sometimes depend on a certain technical skill set of his team (“why did he make this in bash?”). Lately, he’s also been a contributor to the Heroes of Data community by sharing his thoughts on data mesh principles and more. In the context of this article, Ji was tasked with a very special challenge that few engineers have been fortunate to have.
The ETL challenge
The exciting challenge Budbee and Ji was up against revolved around building a new ETL pipeline—basically from scratch. The updated system needed to meet four requirements, in that it should:
- Follow best practices for an ETL pipeline
- Follow solid design principles
- Lower costs of the data pipelines
- Be “Blazingly Fast™” to borrow terminology from Ji’s presentation
Ji was given quite free reins in designing the updated system and led the work alone for a large chunk of the time. In his own words: “the experience made me feel like a superstar for parts of the time, but a lot of the time it was quite painful—but I did learn a lot, as we shall see!” Sharing these learnings is a lot of what the Heroes of Data community is about, and we’re very grateful to Ji for helping the community by showcasing his experiences in detail.
The approach
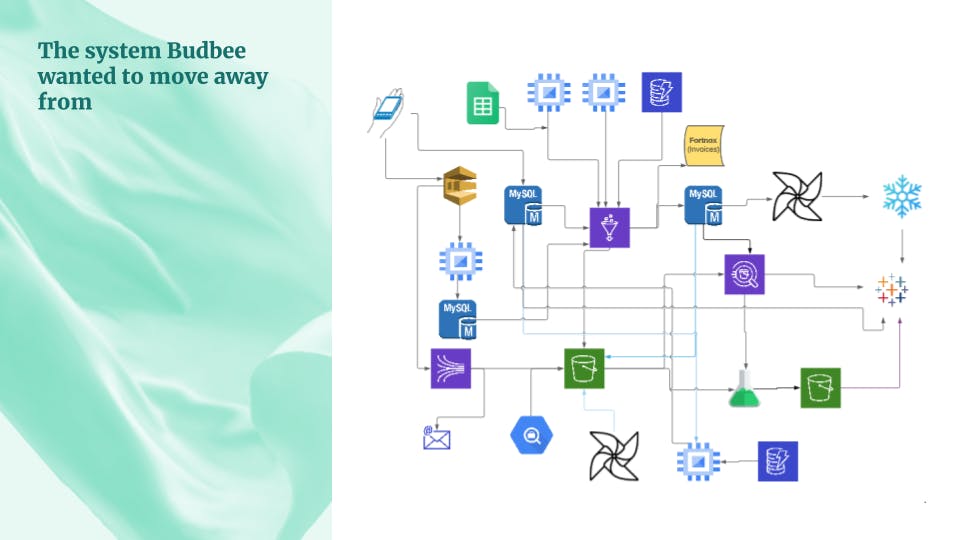
Ji’s initial thoughts for the pipeline included a quite minimalistic design. After all, what else would you need other than a message queue, some binary storage and then Tableau? However, after performing some reconnaissance in the Budbee business requirements landscape, he soon realized there needed to be some additional components in order to make the system work well. In the end, the planned design became a bit more elaborate, along the lines of the image below.