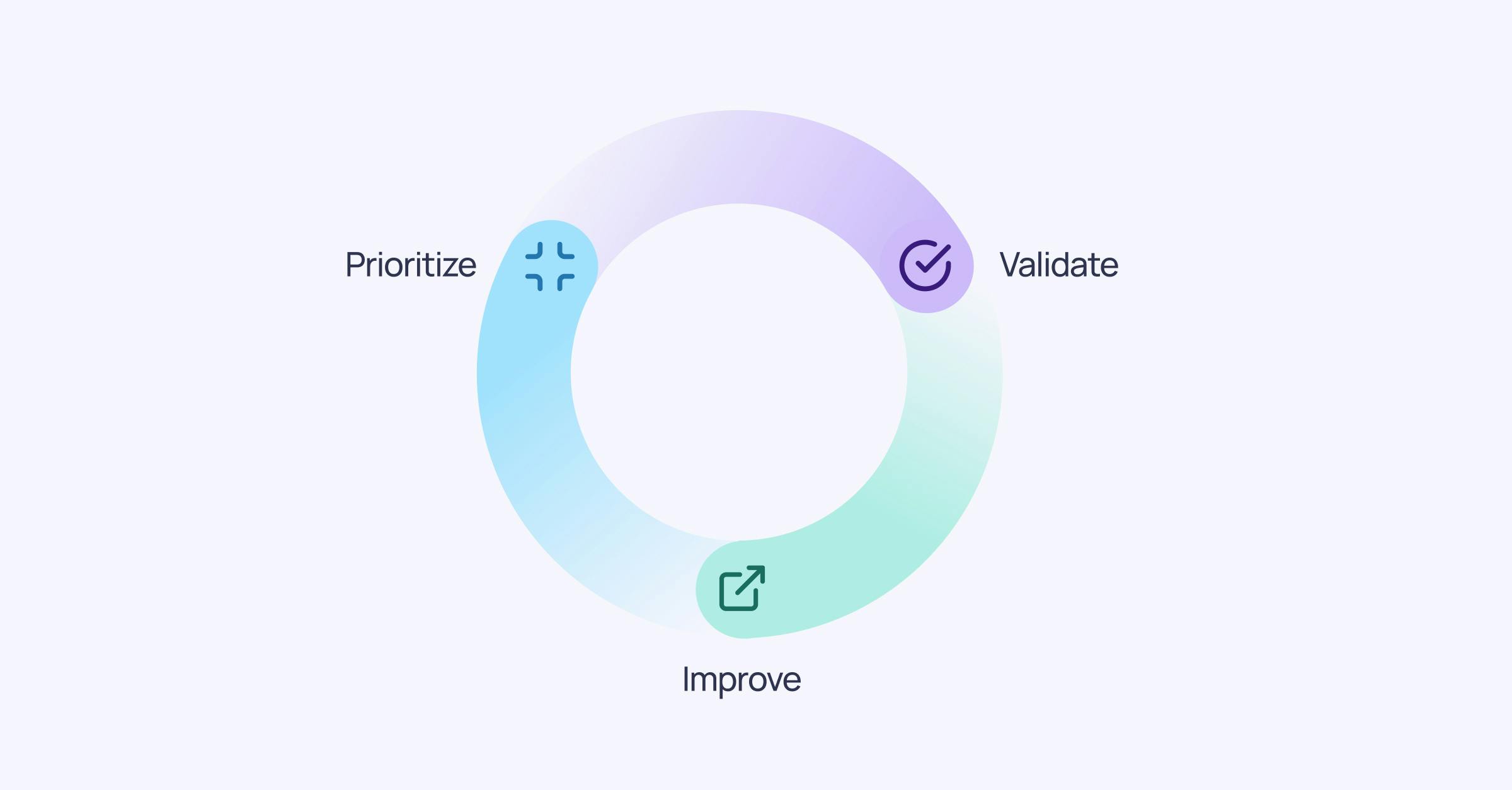
Prioritize the data
The first step of the workflow is to prioritize the data assets. This is done by first understanding what data assets exist, how they’re being used, and what business value they’re contributing to. The outcome should be a list of all data assets ranked by importance based on:
- Business importance (i.e. what data use cases does the data asset enable)
- Utilization rate (i.e. how often the asset is being used/queried)
- Upstream and downstream dependencies (data assets feeding into high priority assets should also be prioritized)
- Compliance and regulatory requirements for data such as GDPR, CCPA, and the European AI act.
Both data teams and business teams must ensure they have full alignment on the ranking of data assets based on business value. If this is not the case, prioritization won’t help combat data debt.
For data assets that are ranked as non-prioritized, the organization should consider whether it can reduce the organizational and financial burden of maintaining these data assets altogether. Appropriate actions can include:
- Updating the data assets less frequently to reduce compute spend
- Deleting the data assets completely to reduce storage-, compute- and data management costs
- Tagging assets as “archived” to make it clear to other data stakeholders that they should put less emphasis on them
For the data assets that are ranked as prioritized, the organization should make sure to establish ownership and Service Level Agreements (SLAs) for each one. Ownership is critical for step 2—Validate.
Validate the prioritized data
We now know which data assets to prioritize, and who is responsible for them. The next step is to continuously validate the prioritized data, by defining what “high quality” data looks like, and discovering data quality issues that prevent that level of quality.
To deliver data quality on the data that matters to the business, quality needs to be defined from the perspective of the person using and working with the data: the data consumer. This might sound trivial, but often data consumers and data producers have very different understandings of what “high quality data” means. For data producers or data engineers that transport the data, “high data quality” might mean that the data passes basic and surface level metadata checks like freshness and volume. I often refer to errors that these checks catch as “loud” data quality issues (because they will make themselves known). Data consumers, in addition to caring about the loud data quality issues, also care about the actual contents of the data at a granular level (they care about “silent” data quality issues). Examples of the latter include:
- whether the mean value of one subsegment of the data is unexpectedly down—for example if event data from one market’s website suddenly stops updating, but the market is so small that the change doesn’t affect the average,
- whether there are any anomalous data points—outside of expected seasonal patterns and trends,
- and whether a date in record is in the future, which shouldn’t be possible
All of these validations of silent data quality issues are non-trivial in the sense that they are very difficult for data professionals to implement themselves. They require sophisticated machine learning and AI models that train on the actual data to determine patterns—not only in the data as a whole, but also in each individual data subsegment.
Improve the data
Once data is prioritized and validated, it’s time to improve it. This work can be split into two buckets.
The first bucket is the handling and resolution of immediate data quality issues. Validation (configured in the previous step) will warn data consumers and producers whenever data doesn’t behave as expected. Data producers should investigate these issues with root-cause analysis, and resolve them according to what data assets are most highly prioritized. Data consumers can then refrain from using the data until it has been fixed. No data is often better than bad data.
The second bucket is to execute needle moving data debt initiatives that are enabled by close collaboration between data consumers and producers. Examples include:
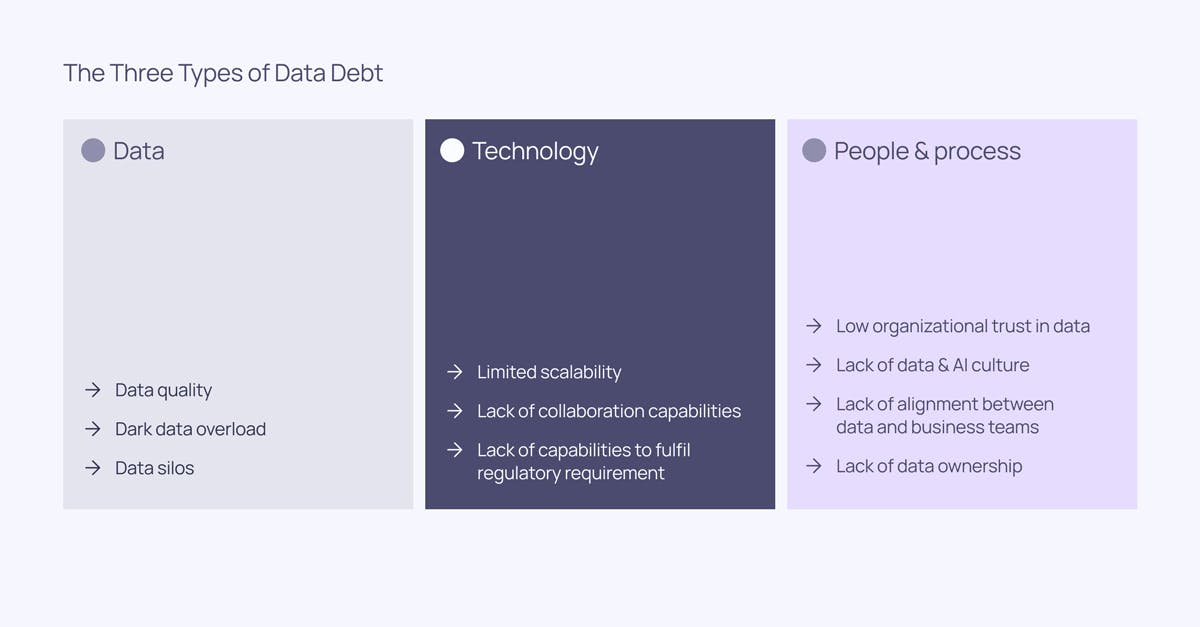
- Paying back data-related data debt: This can include things like updating designs of data models to enable new data use cases, e.g. increased granularity in reporting; simplifying orchestration jobs to make them less error prone; and deprecating data warehouse tables that aren’t being updated but that are sometimes mistakenly used by data consumers
- Paying back technology-related data debt: Increasing the stability of data producing systems (e.g. websites, applications, devices, etc.) that are known to go down and stop producing data data
- Paying back people & process data debt: Enabling upstream data producers to understand what assets are critical for downstream consumers and what validations are important for them. Over time, this leads to breaking changes happening less frequently
In short, this is an intro to the Data Trust Workflow. Make sure to stay ahead with an in-depth guide on how to apply the workflow here. Next, I’ll explain the technological enablers of the Data Trust Workflow.