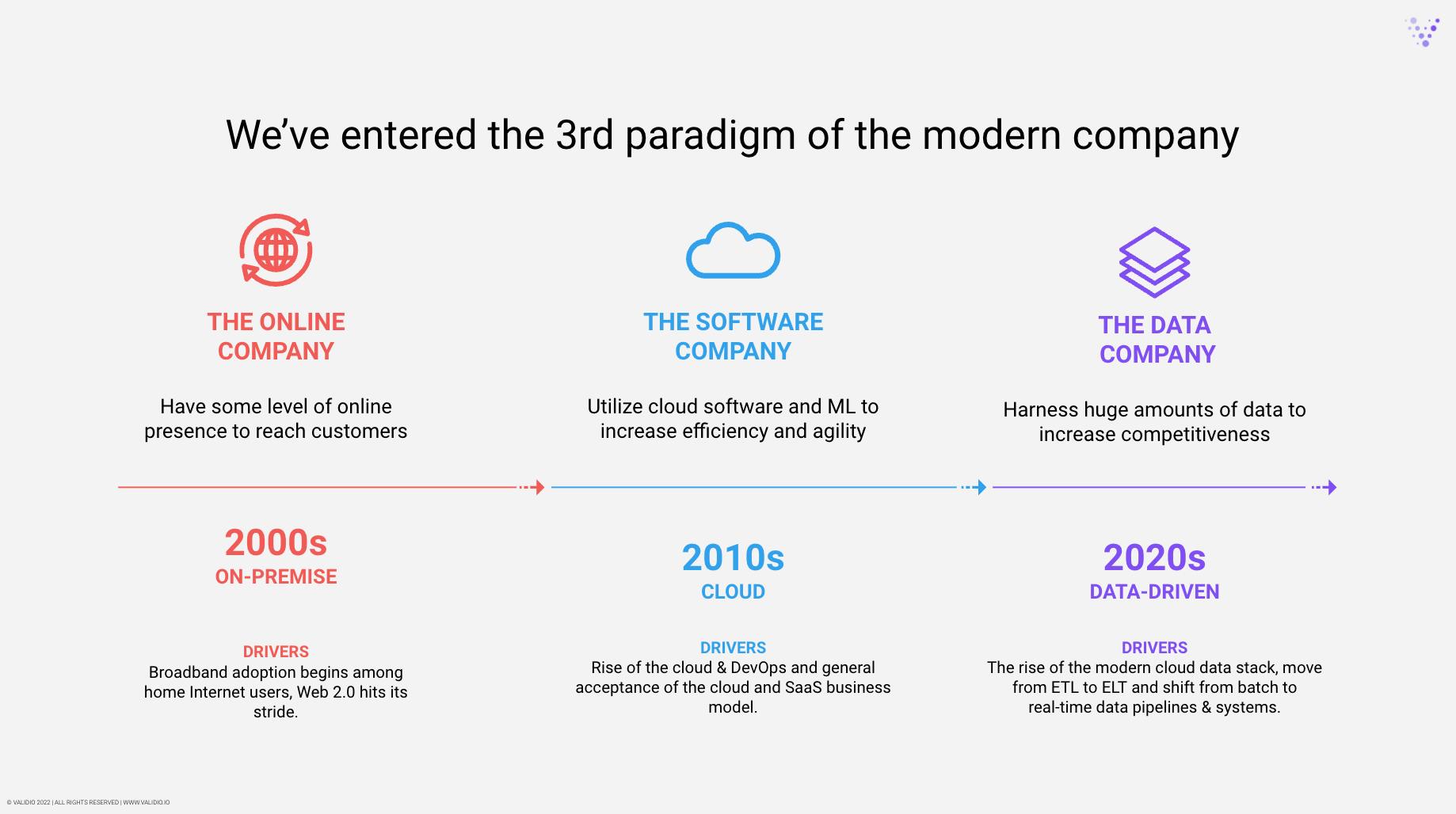
2020 brought a digitalization explosion across the world. Microsoft estimates that the first two months of the pandemic (March & April) drove two years’ worth of digitalization. Throughout the rest of the year, the pandemic accelerated a wake-up call to the markets, which had been a long time coming: every successful modern company will need to be not only a software company, but also a data company.
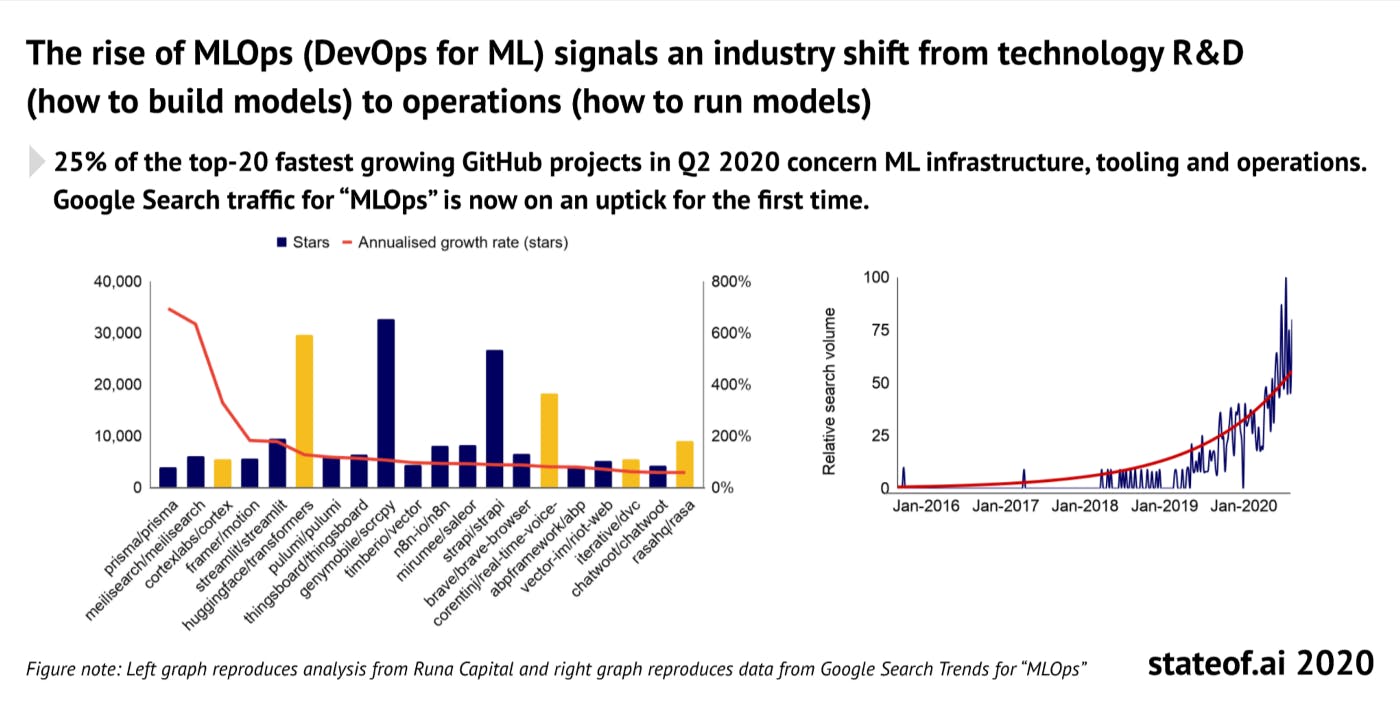
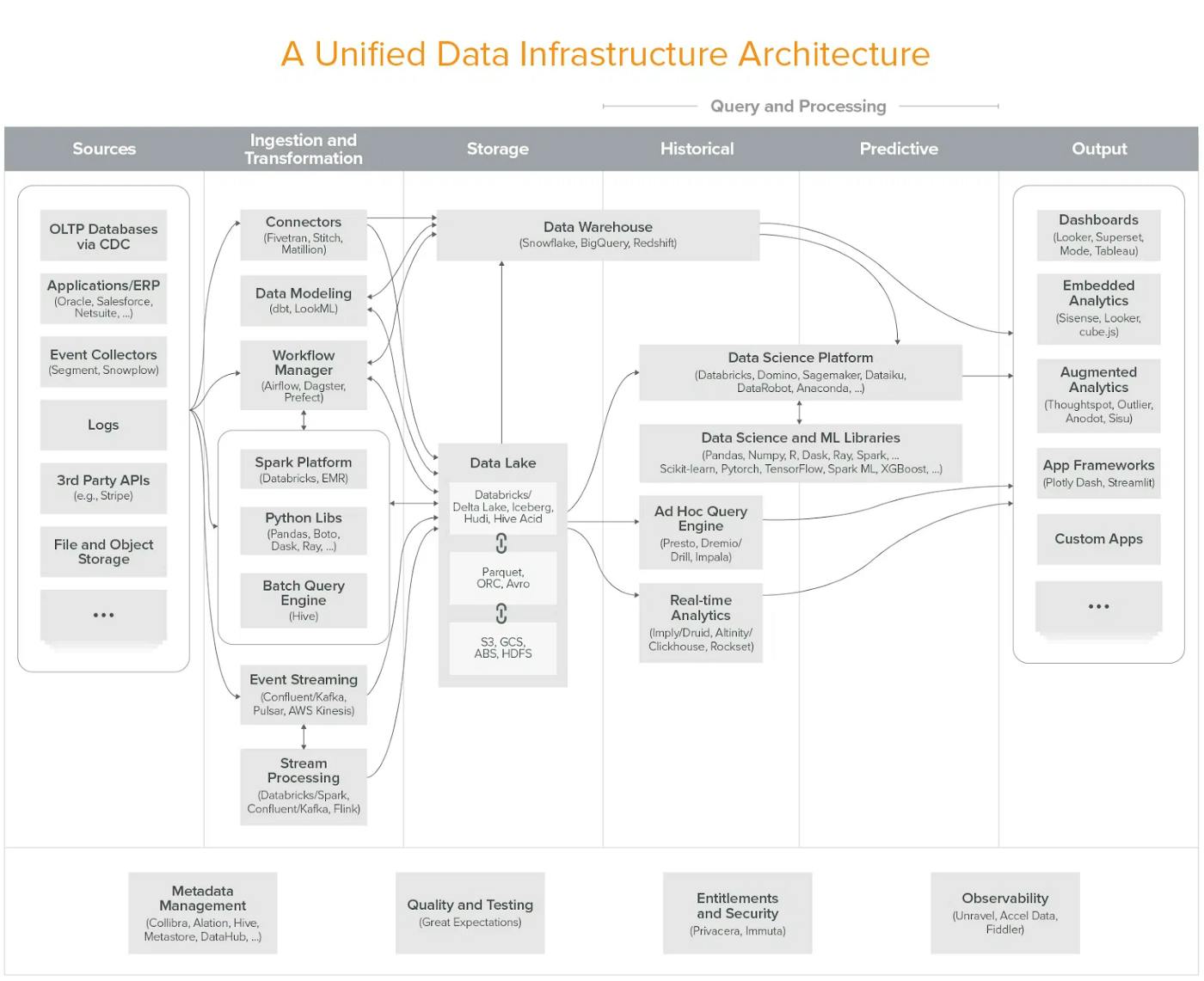
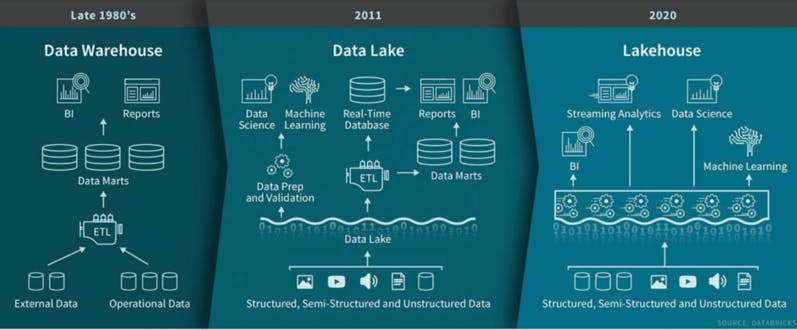
The accelerated digitalization and our ever-increasing appetite for and generation of data fuelled a lot of development in the Data + ML landscape in 2020. As companies have started to reap the benefits of the last few years’ predictive analytics and ML initiatives, they clearly show a healthy appetite for more in 2021. “Can we process more data, faster and cheaper? How do we deploy more ML models in production? Should we do more in real-time?” … the list goes on. We’ve experienced an amazing evolution in the data infrastructure space during the past few years. Data-driven organizations have moved from ETL (Extract, Transform, Load) to ELT (Extract, Load, Transform), where raw data is copied from a source system and loaded into a data warehouse/data lake and then transformed. There’s now even a new paradigm early in the making called reverse ETL, showcasing the velocity of the evolution in this space.
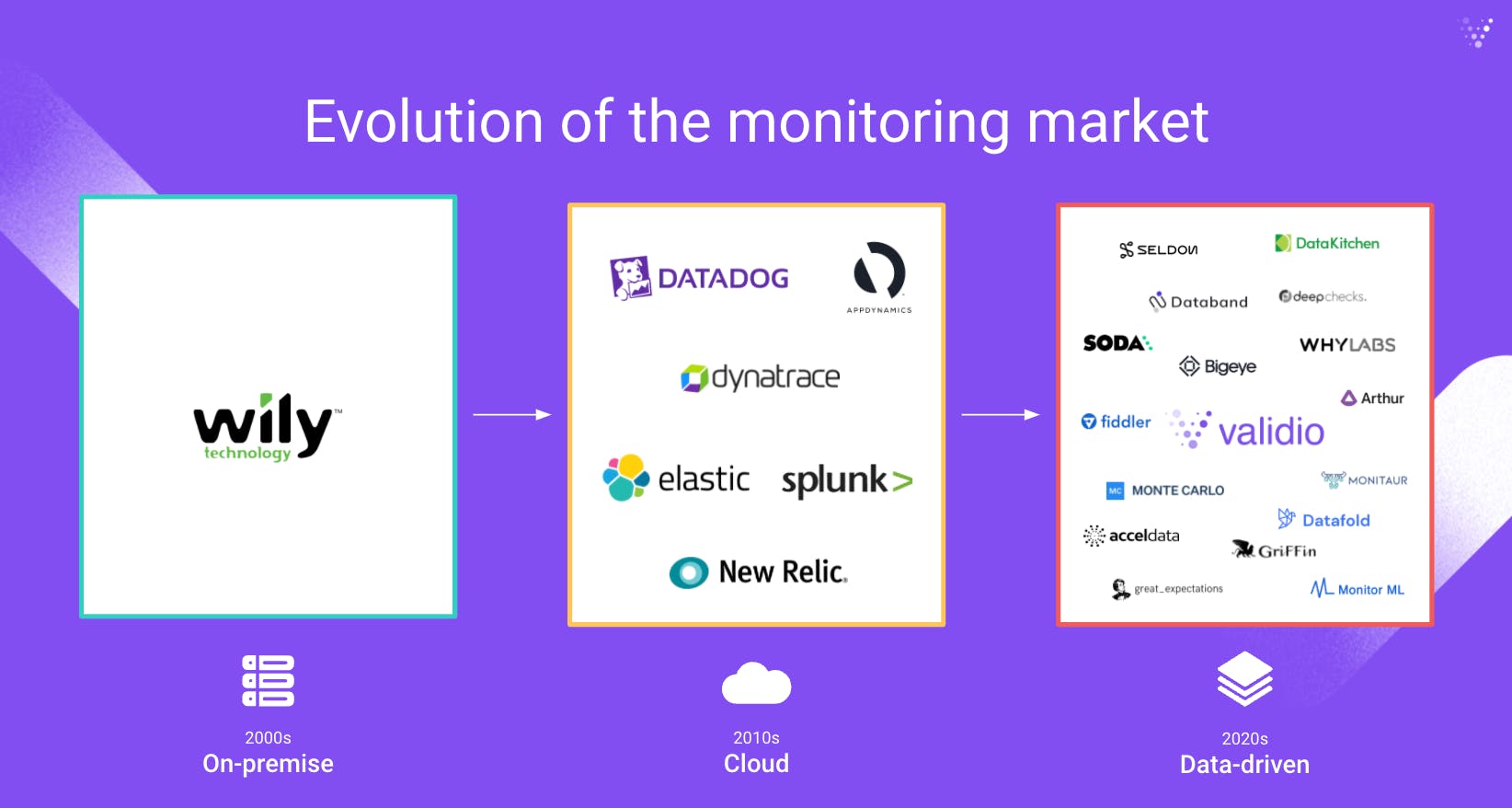
The concept of the “modern data stack” is many years in the making — it started appearing as far back as 2012, with the launch of Redshift, Amazon’s cloud data warehouse. But over the last couple of years, and perhaps even more so in 2020 spearheaded by Snowflakes blockbuster IPO, the popularity of cloud warehouses has grown explosively, and so has a whole ecosystem of data & ML tools and companies around them.
The 2020s is becoming the data decade. While the 2010s was the decade of SaaS — e.g. when Salesforce became the first SaaS company to breach the $100B market cap mark — the 2020s will be the era of data companies growing on strong secular tailwinds (database startups, data quality startups, data lineage startups, machine learning startups, etc.).