



Heroes of Data is an initiative by the data community for the data community (apply here to join). We share the stories of everyday data practitioners and showcase the opportunities and challenges that arise daily. Sign up for the Heroes of Data newsletter on Substack and follow Heroes of Data on Linkedin.
About Dhiana and Ylva at EQT
Dhiana Dheva, Sr. ML Engineer
Dhiana is originally from Brazil but moved to Switzerland in 2011 to work with detecting and analyzing electrons at CERN, using Artificial Neural Networks. Later, she moved back to Brazil to continue with software development and consulting for a number of years. In 2016, she returned to Europe, this time by moving to Sweden to join Spotify as a Software Developer, later transitioning to a role as Machine Learning Engineer. In April 2020, Dhiana joined EQT where she is now working as a Senior Machine Learning Engineer in the Motherbrain team.
Ylva Lundegård, Data Engineering Lead
Hailing from Värmland, Ylva has been a Data Engineer for around three years, starting off at the e-sports company G-loot. As of January 2022, Ylva is working as a Data Engineering Lead in the Motherbrain team.
What is Motherbrain?
Motherbrain is a proprietary, AI-driven investment platform that embeds decision intelligence into EQT’s deal-making process. It uses data and machine learning to find startups that are potential investment opportunities for EQT. Investment professionals are interacting with the platform on a daily basis, which analyzes around 50 million companies across the world; basically finding needles in a haystack.

Motherbrain doubles as a CRM system
Motherbrain scans over 50 data sources and uses machine learning to look at metrics and find patterns that may indicate a good investment opportunity. It also works as a CRM for its users who use the platform to log and track their assessments. The platform currently holds more than 40,000 of these assessments across EQT Ventures, Growth, and Private Equity–which also provide valuable information for the machine learning models to train on.
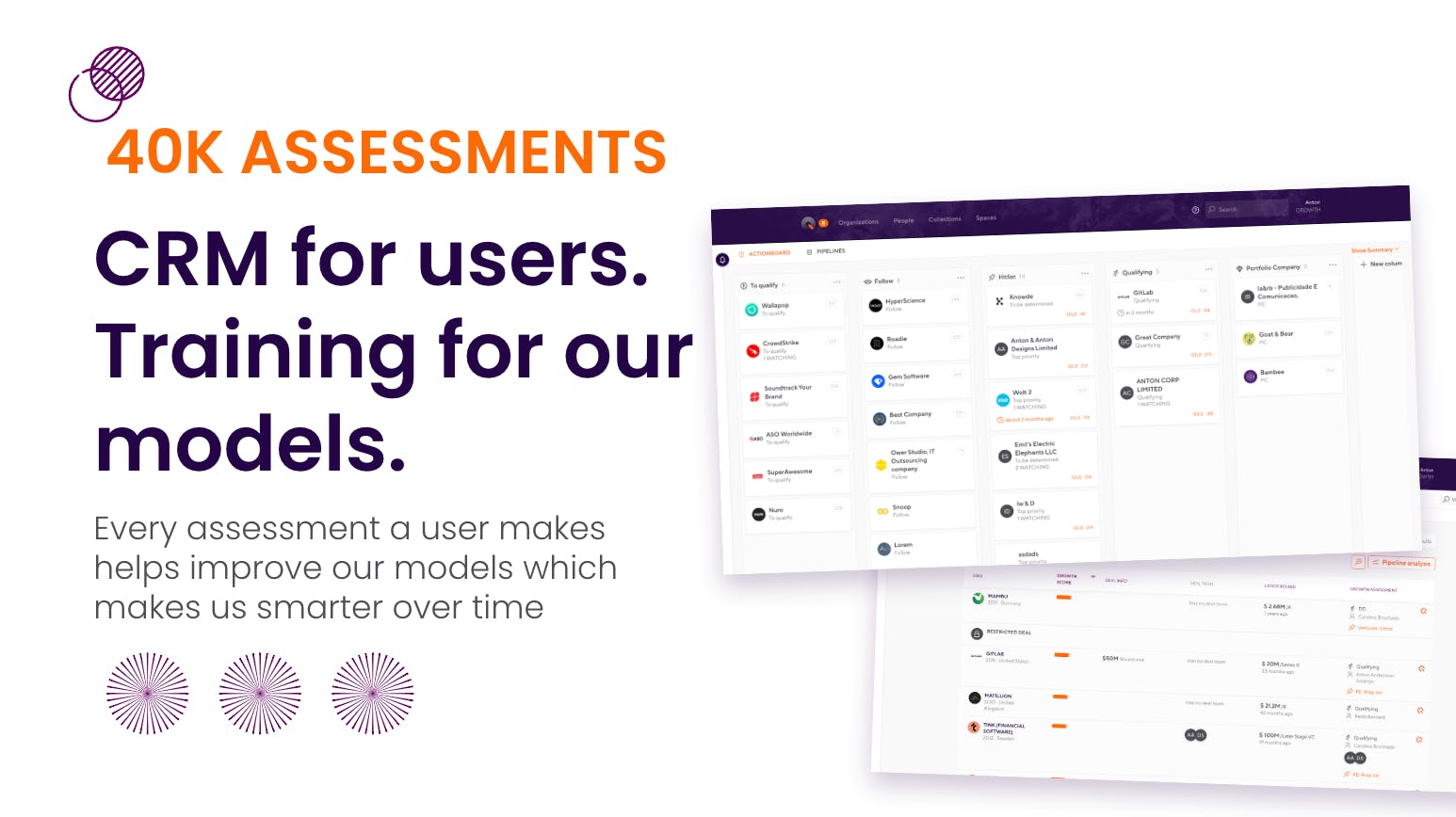
Motherbrain’s team and investments

Motherbrain has an impressive track record of enabling 15 profitable investments for EQT, three of which have become unicorns (a privately held startup with a value of over $1 billion) and one that has been acquired by another company. These investments are shown in the image below.

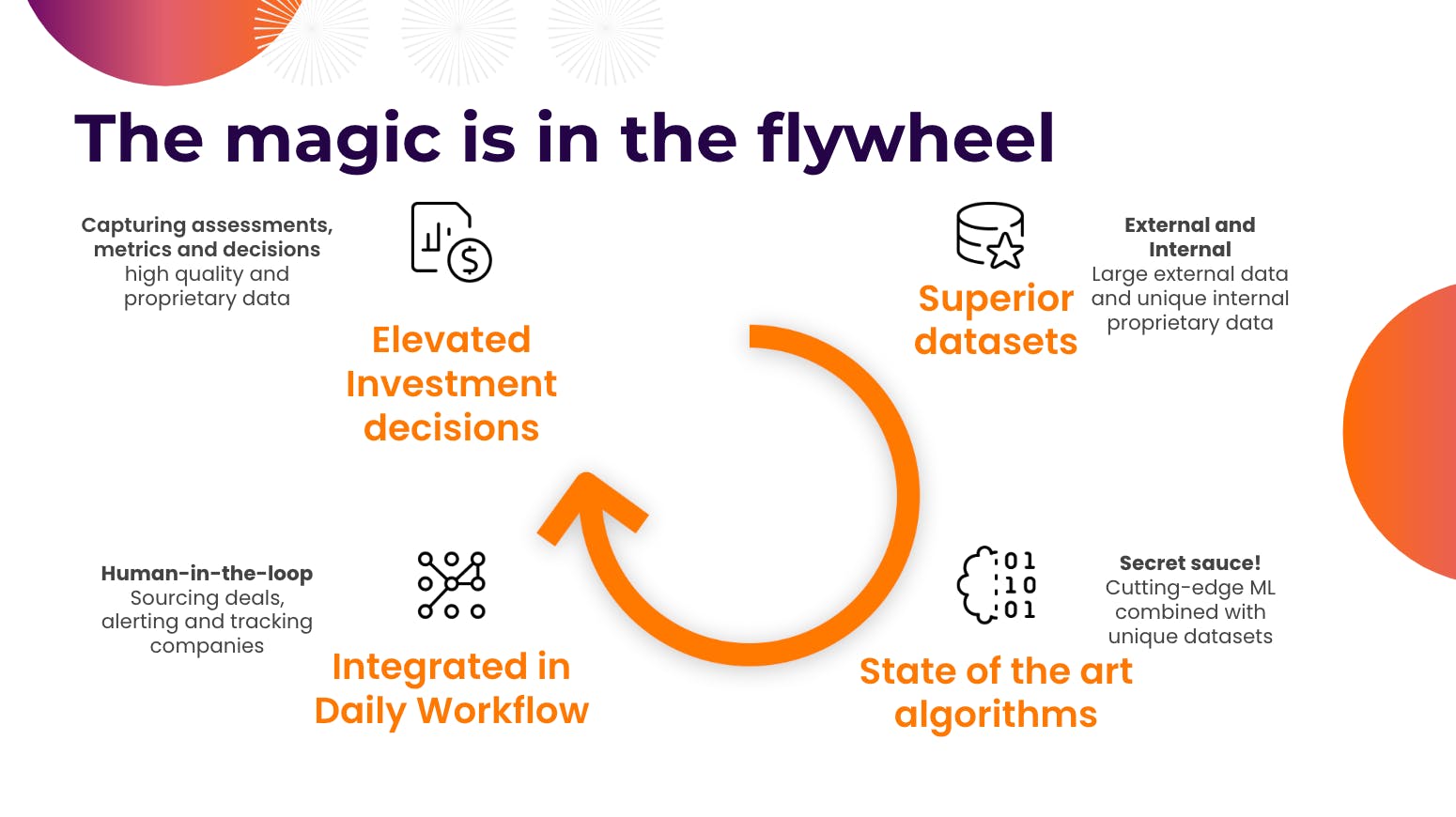
The magic is in the flywheel
Motherbrain’s process heavily relies on machine learning. It starts by ingesting large external and internal datasets, later fed into the machine learning algorithms. Next, the data integrates with the daily workflows of the investment professionals at EQT, who receive predictions to react on. In turn, they create assessments in the platform (as previously mentioned, it doubles as a CRM system for its users) that contribute to further improving Motherbrain’s models. As such, a flywheel is set in motion that keeps improving daily.
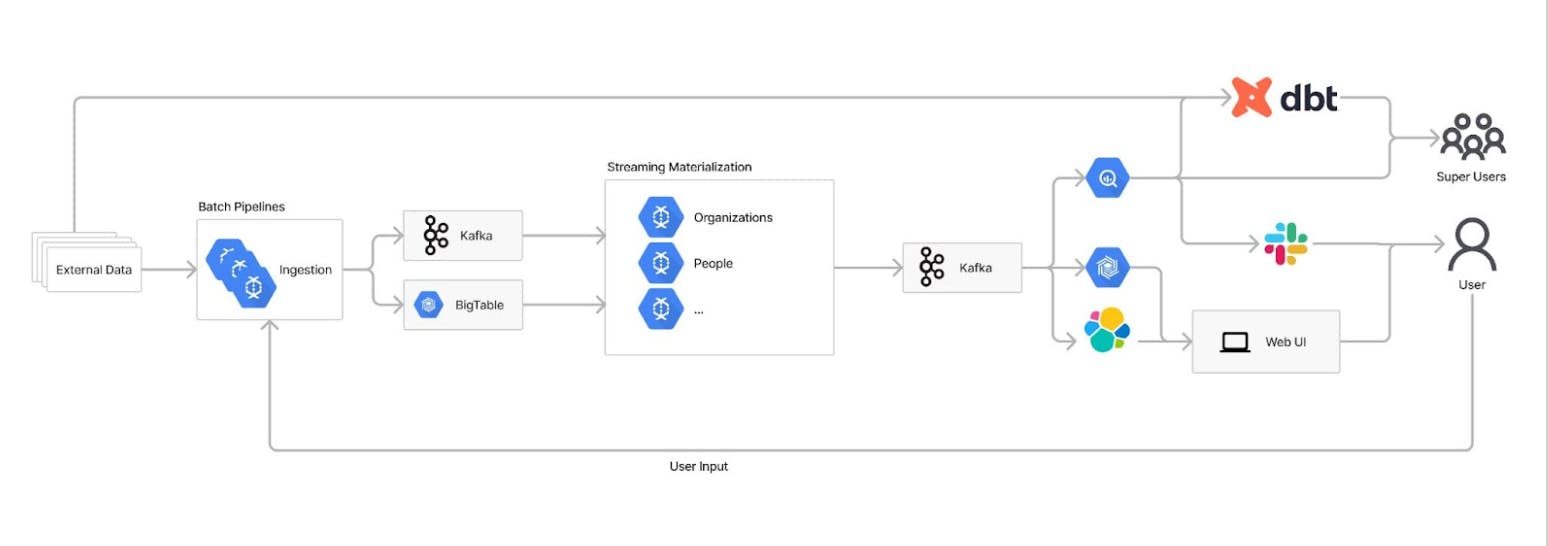
Motherbrain’s architecture is scalable and robust

Let’s look at how the Motherbrain Team has built a data platform using some of these technologies. The platform uses millions of data points as input and produces millions of daily predictions, which are also likely to increase going forward. As such, it’s critical to have an architecture built for scalability that is robust enough to withstand large volumes of noisy data.
External data sources
The external data is ingested through batch pipelines that clean, normalize and store the data in a uniform way. All data pipelines are written in Apache Beam, and run on Dataflow.
Data logs
To make the architecture fit with all types of data formats, the data is reduced to small pieces of information on an attribute level, together with metadata. It is then stored in BigTable, while a Kafka message is triggered to notify there is new or updated data.
This abstraction makes it possible to keep the data loosely coupled and easily merge data entities into a single entity downstream. This also enables flexibility when changing either ingestion jobs or entity structures downstream.
Materializers
Next up is what the Motherbrain team calls materializers, the streaming pipelines responsible for putting together the entities again after listening to the Kafka messages. Two things are essential for the materializers to decide here; (1) what should go into the entity and (2) what is the most likely correct information. There can be contradictory information from different sources, e.g. one data source saying that a company is named “Vandelay Industries” while another is saying “Vandelay Ind.”. This is where Motherbrain needs to make a decision about which one to pick.
Consumers
After entities have been built, they are sent to Kafka to be consumed by other applications. The primary consumers are using the data in Motherbrain’s web interface, which makes the data easily accessible with Elasticsearch. Other consumers are the superusers, mainly the Motherbrain Labs team, who access the data from BigQuery and usually do more ad-hoc analysis.
User input
Apart from the external data, there is internal data put in the system by EQT users. This goes through a similar flow as the external data but is generally prioritized higher by Motherbrain when putting the entities together and training models.
Motherbrain’s event-driven architecture supports machine learning predictions in three ways
- Motherbrain supports online predictions, where real-time resolutions are required, by having both materializers (the streaming pipelines) and online users (the humans interacting with the web UI) able to trigger the prediction service.
- It also supports streaming predictions, where resolutions only are required whenever a variable affecting the prediction of a company has changed. This is done by listening to Kafka messages, triggering the service as soon as an impactful change occurs.
- Lastly, Motherbrain also supports batch predictions. Often it is not necessary to have predictions in real-time. It might be enough to deliver freshly updated information to consumers once every day, e.g. providing investment professionals with the current top-ranked companies, according to Motherbrain’s algorithms, when they arrive at work in the morning.
Parting thoughts
- Machine learning models are not always correct, which is why Motherbrain is designed to learn from wrongful data points and use them to improve its predictions every day.
- The architecture of Motherbrain needs to be dynamic to react to the ever-changing world. EQT’s solution to this has been to build an event-driven architecture that can break down data into smaller bits and pieces whenever needed, add intelligence to it, and put it back together into a format that makes sense for investment professionals to act on.
- It’s also not enough to just rely on raw data. Digging through the data of 50 million companies means large data volumes and a lot of noise. The machine learning parts are needed to cut through the noise of bad data and fill in the gaps wherever possible. The users and the machine learning models will benefit from each other's input in empowering the flywheel that will continuously improve and evolve Motherbrain over time.

At Heroes of Data, we’re grateful to Ylva and Dhiana for sharing their experiences and learnings with the broader data community so others can learn from them. We can’t wait to see what they will achieve with EQT and Motherbrain in the future.
If you found this topic interesting, the Motherbrain team recently wrote a short Medium post about using Deep Learning to find the next Unicorn–make sure to check it out here!
This article was summarized by Emil Bring, based on a presentation by Ylva and Dhiana from EQT at a Heroes of Data meetup in October 2022.