



By this point we at Validio have spoken with over 100 data teams — from early-stage startups to fast-growing scaleups and large corporations revamping their data strategies to reflect the new reality they operate in. Most of the companies that we’ve interacted with have modern data teams with engineering-led decision-making. One player in the Modern Data Stack that we see appearing time and time again in our discussions is dbt. So what is that all about?
The rise of Fishtown Analytics and the dbt community
Fishtown Analytics’ data build tool (known as dbt) has made pretty sizable waves in the analytics and data space during the past few years. Fishtown Analytics (today dbt Labs) pioneered the practice of analytics engineering, built the primary tool in any analytics engineering toolbox (dbt) and has seen a fantastic community emerge around the analytics engineering workflow. Today there are over 5,000 companies using dbt; there are 13k+ data professionals in the dbt Slack community; and 800+ companies are paying for dbt Cloud.
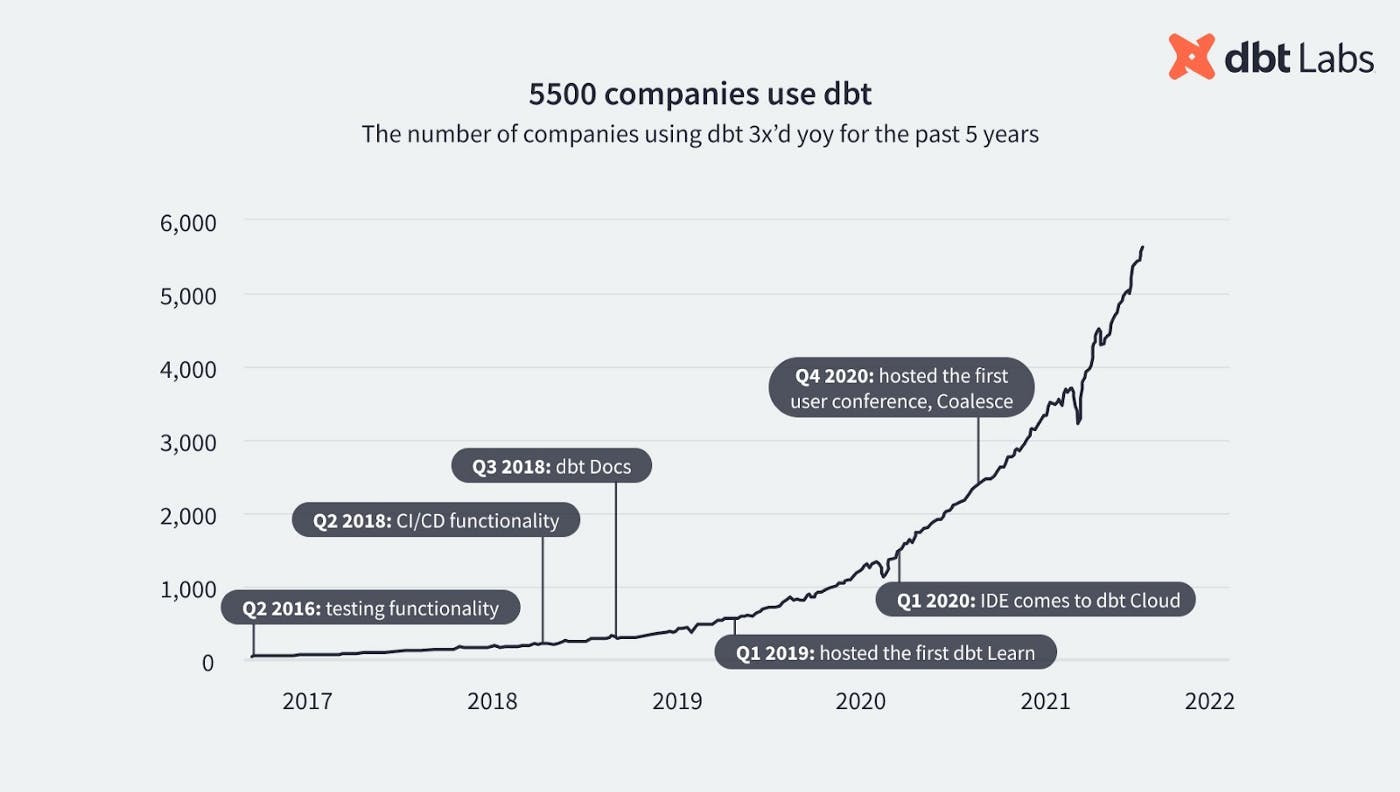
This progress has not gone unnoticed by the investor community and last year Fishtown Analytics (the company behind dbt) raised a $13M Series A led by Andreessen Horowitz and, 7 months later, a $29M Series B led by Sequoia Capital. Rumors are that they’re currently raising a round valuing the company at $1.5B. So it’s fair to say that the momentum around dbt is palpable. The rise of the “Analytics Engineer” is a very real movement born out of a very real necessity (and genius branding, some might say). As portrayed in the recent Medium post “Become an Analytics Engineer in 90 Days”: If a Data Engineer marries a Data Analyst and they have a baby girl, that baby girl will be an Analytics Engineer. Naturally, it doesn’t work like that, but you get the point.
The rise of dbt and the analytics engineer
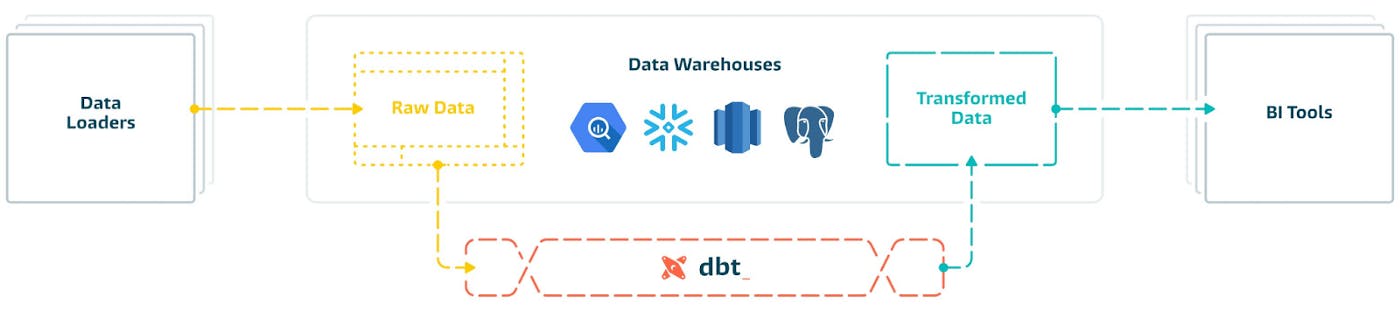
In short, dbt or data build tool is a full-stack data tool that allows data analysts and analytics engineers to own the “Transform” step in the Extract, Load, Transform (ELT) pipeline. Described as the “T in ELT”, dbt lets you write SQL models that can be executed in order (specifically a DAG). It’s also open source and has developed a thriving community around it, proven by the numbers mentioned earlier. The main drivers behind this technology are the rise of cloud-based data warehouses and the SQL knowledge available on the market.
In essence, dbt is a flexible command-line data pipeline tool that allows e.g. Analytics Engineers to collect and transform data for analytics fast and easily. With dbt, there’s no need to reprogram your pipeline. dbt is built on SQL like conventional databases, but it has additional functionality built on top, using templating engines like jinja combined with Python scripting, enabling users to build additional logic into the SQL (like loops, functions, etc.) to access, rearrange and organize data. Kind of like programming a dataset but with much more flexibility and options.
Let’s jump over to the Analytics Engineer. Is it another new term in the data world or is it an example of clever marketing? Analytics Engineering is a term pushed by the team behind dbt (albeit Fishtown Analytics Head of Marketing Janessa Lantz says they wouldn’t take credit for coining it). Analytics engineering is the data transformation work that happens between loading data into your warehouse and analyzing it. In simplified terms, dbt allows anyone comfortable with SQL to own that workflow.
To put the Analytics Engineer role in context it’s useful to look at a few other core roles in a modern data team:
- Data Engineers: manage core data infrastructure, ensuring data is available and accessible across the organization at the expected time at the expected quality.
- Data Analysts: partner with business stakeholders to answer questions with data, build dashboards and reporting, and carry out exploratory analysis.
- Data Scientists: use e.g. statistics and machine learning to explore and extract value from data: solving optimization problems, building prediction models, running A/B experiments, etc.
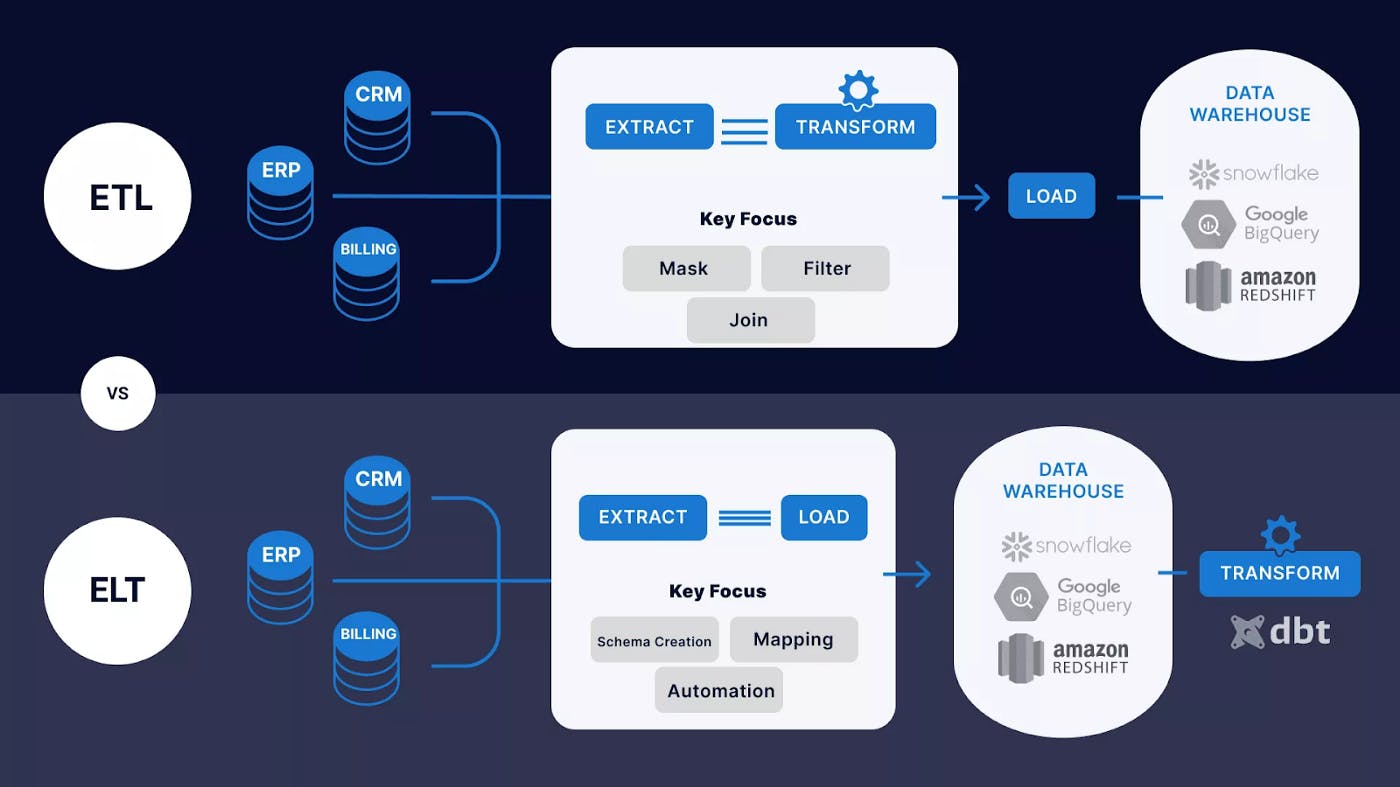
So the shift from ETL to ELT means that data now lands in the cloud data warehouse before it has been transformed. This presents an opportunity for very technical analysts who understand the business well to model the raw data into clean, well-defined datasets to step up — enter the Analytics Engineers. If one wanted this kind of analyst under the ETL paradigm, they would need to be a software engineer and a data analyst — and that would be a tricky hybrid to find. Finding a technical analyst under the ELT paradigm is much more realistic. And with this trend, dbt has risen as almost the de-facto standard for doing transformations on modern cloud-native data warehouses.
An Analytics Engineer often starts off as a Data Analyst, creating dashboards and doing ad-hoc queries. When we’ve spoken with modern data teams, people that have become Analytics Engineers often wanted to be able to do more, more independently, as they felt dependent on their data engineer colleagues. Data Analysts turned Analytics Engineers usually not only know the analytics part, but also know the data, having spent hours navigating it daily with their advanced SQL skills; while also knowing the business inside out.
The intensifying buzz around the Modern Data Stack is inevitably fueling the rise of the Analytics Engineer. To summarize, there are a few key trends that are pushing this:
- The shift from ETL to ELT means people who know SQL have the power to transform and clean data once it arrives in the warehouse. Cloud data warehouses are powerful enough to handle the transformation workload.
- Tools like dbt enable analysts with SQL-based workflows and give them the picks and shovels to work like software engineers do.
- Data consumers have come to simply expect good and usable data at their fingertips at all times.
- Organizations (large and small) are recognizing the need to invest more resources in data modeling.
As Koen Verschaeren from ML consulting firm ML6notes:SQL, because of the declarative nature and knowledge available in the market, is a continuous theme in the data and ML world. Initially, data processing and machine learning were only possible by developing programs in Java, Scala, Python etc.The trend these days is to add SQL support to avoid or minimize programming.Great examples are ApacheKafka with KSQL, Apache SparkSQL, FlinkSQL, BigQuery ML, BlazingSQL, BeamSQL.
Why is this the case? Simply put, it’s easier to find people with SQL skills in the job market versus developers with big data engineering and/or machine learning experience. Individuals who work with data visualization are familiar with or learn SQL faster than Python or Java. Data Analysts that morph into Analytics Engineers usually want to use SQL versus programming or being heavily reliant on a separate data engineering team in the organization.
What’s next for dbt and the Analytics Engineer
We at Validio see increasing adoption levels of dbt and a thriving future for analytics engineering, just like with data engineering, which was the fastest-growing job in tech in 2020.
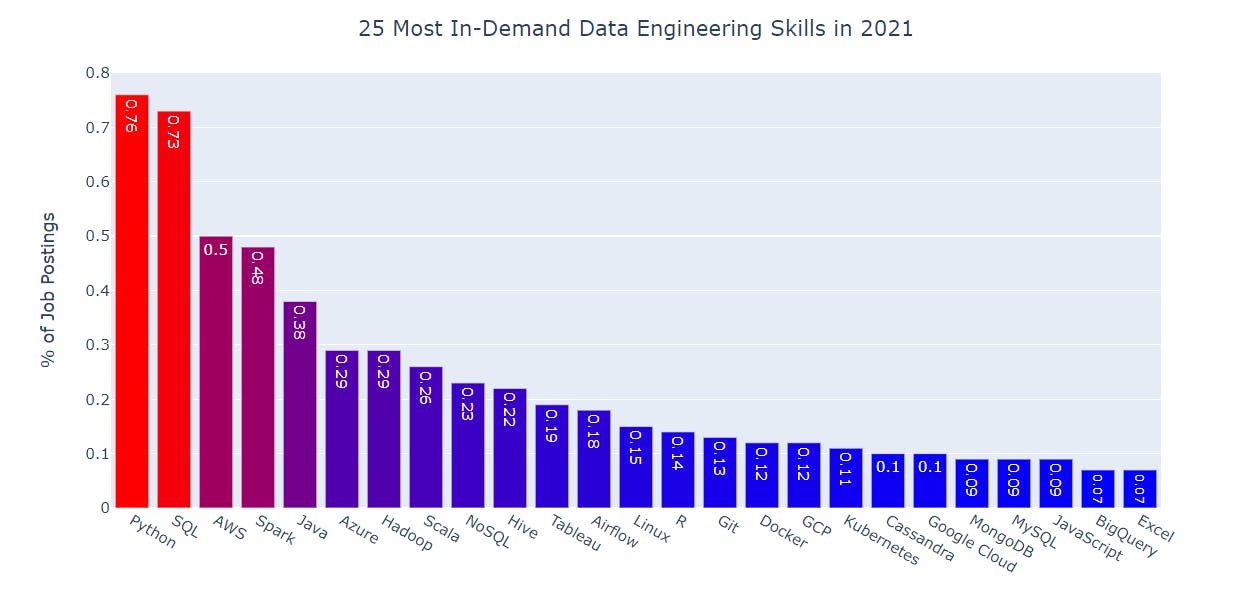
If data engineering trends are at all indicative of the future of dbt and analytics engineering, SQL is not leaving the spotlight anytime soon. Below are the top 25 most in-demand data engineer skills in 2021, ranked from highest to lowest:
To get a more granular look, the chart below shows thetop programming languages for data engineers:
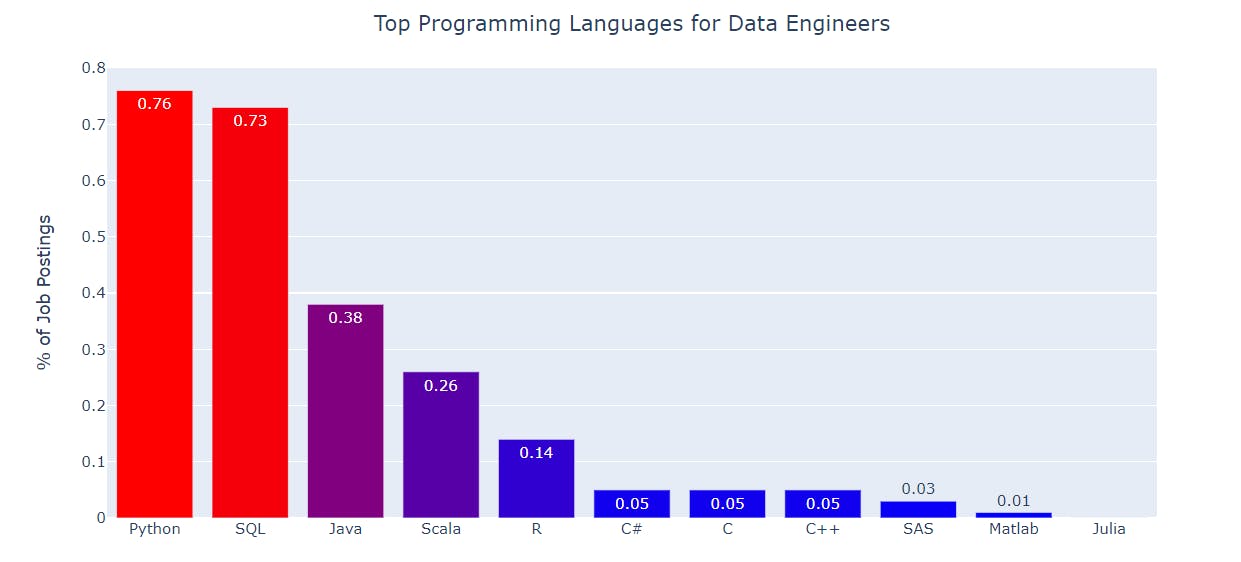
It’s fair to say that Python and SQL dominate the charts with a clear margin. However, we’re the first to admit that the vogue architecture/technology 5 years ago wasn’t SQL. The massive scale that the Internet brought with it a family of databases that were non-relational, document-based, spoke a dialect other than SQL, used data lakes, etc. Not that these were bad technologies, they were just very different from the MySQL, Postgres, or Oracle-style of relational SQL databases. And in 2016, these databases felt like fax machines in the 2010s. Nice relics and reminders of how the previous generation used to work.
Since Hadoop came around in the late 2000s, people were offloading workloads from their data warehouses to the new and “shiny” data lakes. And it didn’t take long before Spark, which was open sourced in 2010, became the standard processing engine on data lakes. Now we see with Snowflake, BigQuery, Redshift, etc. a reverse trend, we’re moving back to the data warehouse. And as mentioned earlier: with that trend dbt has risen as almost the de-facto standard for doing transformations on modern cloud-native data warehouses.
The discussions gravitate towards the evolution of data warehouses & lakes and how machine learning will influence analytics in the future, when trying to look into the crystal ball and predict how the future of dbt and the analytics engineer looks like in the context of the modern data stack. What do different industry leaders and veterans think?
Bob Muglia, former CEO of Snowflake and investor & board member of Fivetran, sees that in a long-term perspective, data lakes won’t have a place in the modern data stack. Muglia underlines that you have to look at the evolution of how infrastructure changes over time to take on new capabilities. He predicts that five years from now, data is going to sit behind a SQL prompt by and large, and then over time evolve into relational. He predicts that relational will dominate and SQL data warehouses will replace data lakes.
On the other hand, Muglia has some vested interests in his worldview via Snowflake and Fivetran. Martin Casado, partner at a16z, conversely speculates that one could argue that over time, it’s the data lake that ends up consuming everything. He sees that at the end of the day, we have technologies and companies that optimize around use cases. Like us at Validio, he sees operational machine learning use cases as a big fish — supporting the notion that data lakes could end up consuming everything.
Surely, Muglia and Casado represent two pretty extreme positions. But still, there is a need to bring the world of machine learning, Python and Scala closer to the world of analytics, SQL and BI tools. Fivetran CEO & Co-founder George Fraser argues that there are essentially three competing ideals:
1) Putting machine learning into SQL (like BigQuery),
2) Putting SQL into Python or Scala (like Databricks), or
3) Keeping SQL and ML (Python/ Scala) separate and using Apache Arrow, where everyone implements an interchange format and everything talks together.
Which do you think will win out?
Final thoughts
The rise of the Modern Data Stack has transformed the data industry in a fast pace. A lot of job titles like analytics engineer, operations analyst were virtually non-existent up until a few years back. The fact is that the role of the Analytics Engineer is still very much in its early innings (like almost all parts in the Modern Data Stack). As Spotify's Peter Gilks & Paul Glenn discuss in their Medium post “Analytics Engineering at Spotify” — while it may sound like they have analytics engineering all figured out at Spotify, one of the most exciting parts of the job is that they are in fact constantly evolving the definition of the role — something that seems to be happening all over the industry. With every new blog post that comes out, whether from Michael Kaminsky, Fishtown Analytics, Netflix or the many others who have written on this topic, they see both echoes of the journey Spotify has already taken and ideas for new opportunities they can take on.
While some people are betting that dbt will become bigger than Spark, we won’t take a stance on that. What we can say for sure is that, based on our continuous discussion with data teams, dbt has really impressive adoption rates. And no matter how the future pans out, we salute Tristan Handy and the Fishtown Analytics team for what they’ve built and the fast-growing community they’re nurturing and engaging with — truly an inspiration for any product-led start-up in the data space and beyond!