Amit Sharma is a Data Product Manager, and top voice on Linkedin for Data Quality & Data Governance. This blog post is one of Validio's community collaborations. For more, follow Amit on Linkedin, and join the heroesofdata.com community.
Have you ever attempted to cross a road, bustling with traffic while blindfolded? The odds are quite high that you won't make it across unscathed; you're likely to encounter an injury or a major mishap. Likewise, when it comes to making crucial business decisions, training machine learning models, or building GenAI applications we should avoid relying on data that hasn't been rigorously validated for quality. According to this article, low data quality costs organizations 15 to 25% of their revenue.
Data teams are likely to try and fix these problems with tools and code. However, most data quality problems can be attributed to broken processes in the organization and to communication gaps between data producers and data consumers. In other words, low data quality is not just a tooling problem—it’s also a people and a communication problem.
In this article, I explore how tools — like Data Observability and Data Contracts can help organizations build more inclusive data-driven cultures. Framed differently, I will be exploring how I see that these technologies can help drive a change in organizational culture.
First, we’ll cover some terminology and context. Then, we’ll dive into a proposed step-by-step process that can be followed to build a data-driven culture.
Context on data quality, data contracts, and data observability
Before diving into the meat of this article, let’s start with a few definitions and some context settings for key terminology: data quality, data contracts, and data observability.
Intro to Data Quality
Data quality is defined by Validio in their whitepaper as
“The extent to which an organization’s data can be considered fit for its intended purpose. Data quality should be observed along five dimensions: freshness, volume, schema, (lack of) anomalies, and distribution. It is always relative to the data’s specific business context“
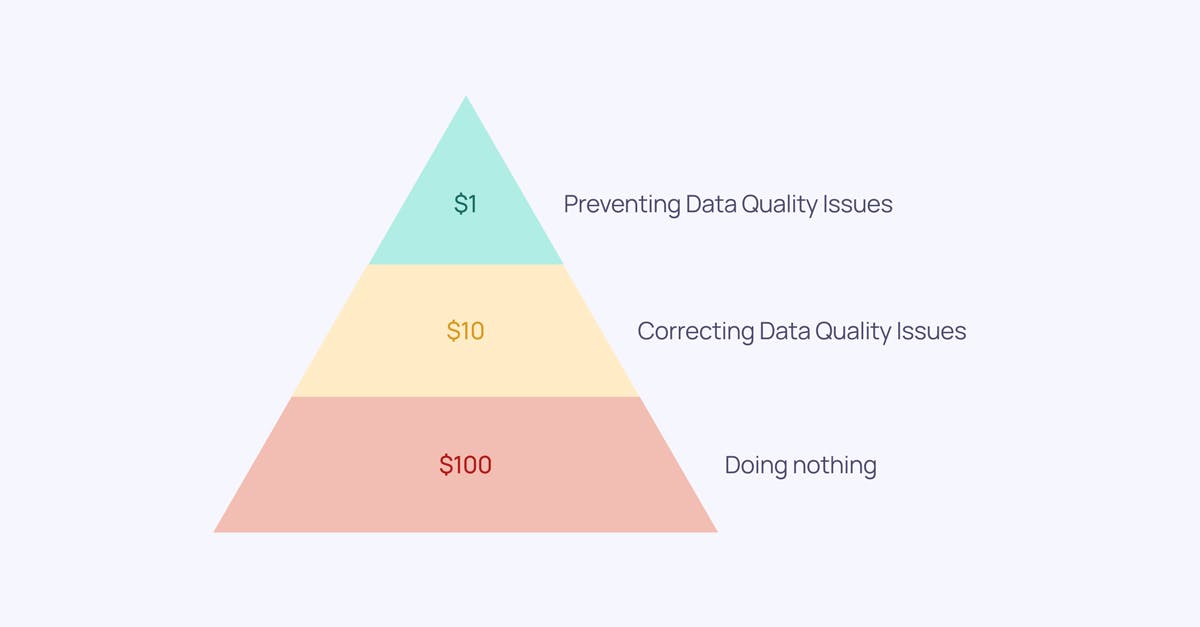
When it comes to the effects of bad data, the 1-10-100 Principle of Data quality, developed by George Labovitz, Yu Sang Chang, and Victor Rosansky in 1993, is a framework used for this purpose.
According to this framework:
- $1 represents the initial cost of assessing data as soon as it's created. Skipping this step increases the cost to $10.
- The $10 signifies the expense that businesses have to bear to remediate the data.
- The initial $1 dramatically escalates to $100 in the third and final phase. This $100 reflects the amount businesses will have to pay when they fail to clean the data promptly.