In 2021, we saw quite an acceleration of the buzz around the rise of the Modern Data Stack. We now have a tsunami of newsletters, influencers, investors, dedicated websites, conferences, and events evangelizing it. The concept around the Modern Data Stack (albeit still in its early innings) is tightly connected with the explosion of data tools in the cloud. The cloud comes with a new model of infrastructure that will help us build these data stacks fast, programmatically, and on-demand, using cloud-native technologies like Kubernetes, infrastructure as code like Terraform and cloud best practices of DevOps. So, infrastructure becomes a critical factor in building and implementing a Modern Data Stack.
As we’ve entered 2022, we can clearly see how software engineering best practices have begun to infuse data: data quality monitoring and observability, specialization of different ETL layers, data exploration, and data security all thrived in 2021 and will continue as data-driven companies from early-stage startups to multi-billion dollar Fortune 500 leaders continue to store and process data into databases, cloud data warehouses, data lakes and data lakehouses.
Below you’ll find 5 data trends we predict to establish themselves or accelerate in 2022.
1. The rise of the Analytics Engineer
If 2020 and 2021 were all about the rise of the data engineer (which according to Dice’s tech jobs report was the fastest-growing job in tech in 2020), in 2022 the analytics engineer will make its definitive entrance to the spotlight.
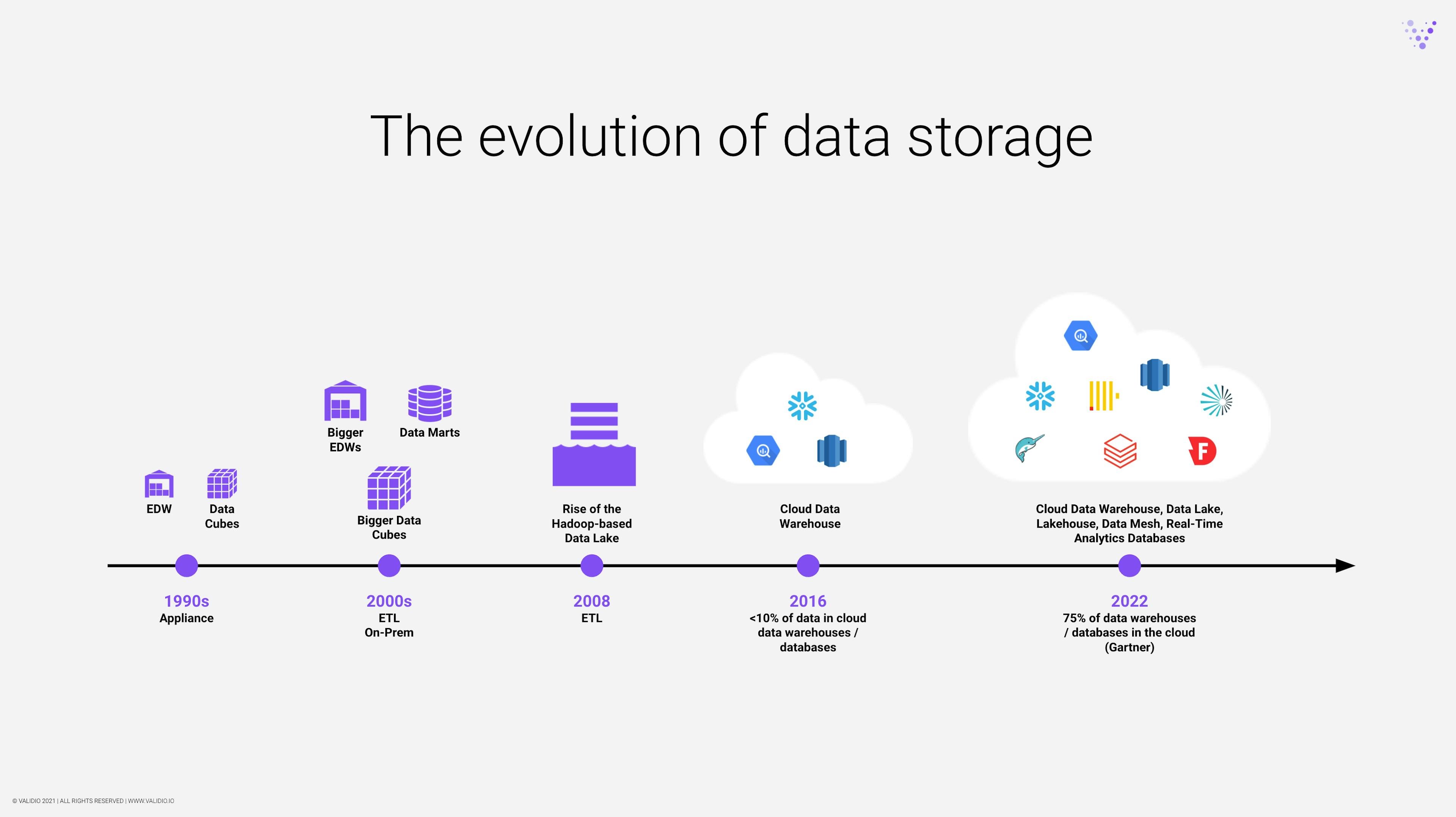
The rise of cloud data platforms has changed everything. Legacy technical constructs such as cubes and monolithic data warehouses are giving way to more flexible and scalable data models. Further, transformations can be done within the cloud platform, on all data. ETL has to a large extent been replaced by ELT. The one controlling this transformation logic? The analytics engineer.
The rise of this role can be directly attributed to the rise of cloud data platforms and data build tool (dbt). Dbt labs, the company behind dbt, actually coined the role. The dbt community started with five users in 2018. As of November 2021, there were 7,300 users.
The analytics engineer is an example of natural evolution, as data engineering will most likely end up in multiple T-shaped engineering roles, driven by the development of self-serve data platforms rather than engineers developing pipelines or reports.
Analytics engineers first appeared in cloud natives and startups such as Spotify and Deliveroo, but recently started gaining ground in enterprise companies such as JetBlue. You can read here an article by the Deliveroo engineering team about the emergence and evolution of analytics engineering in their organization.
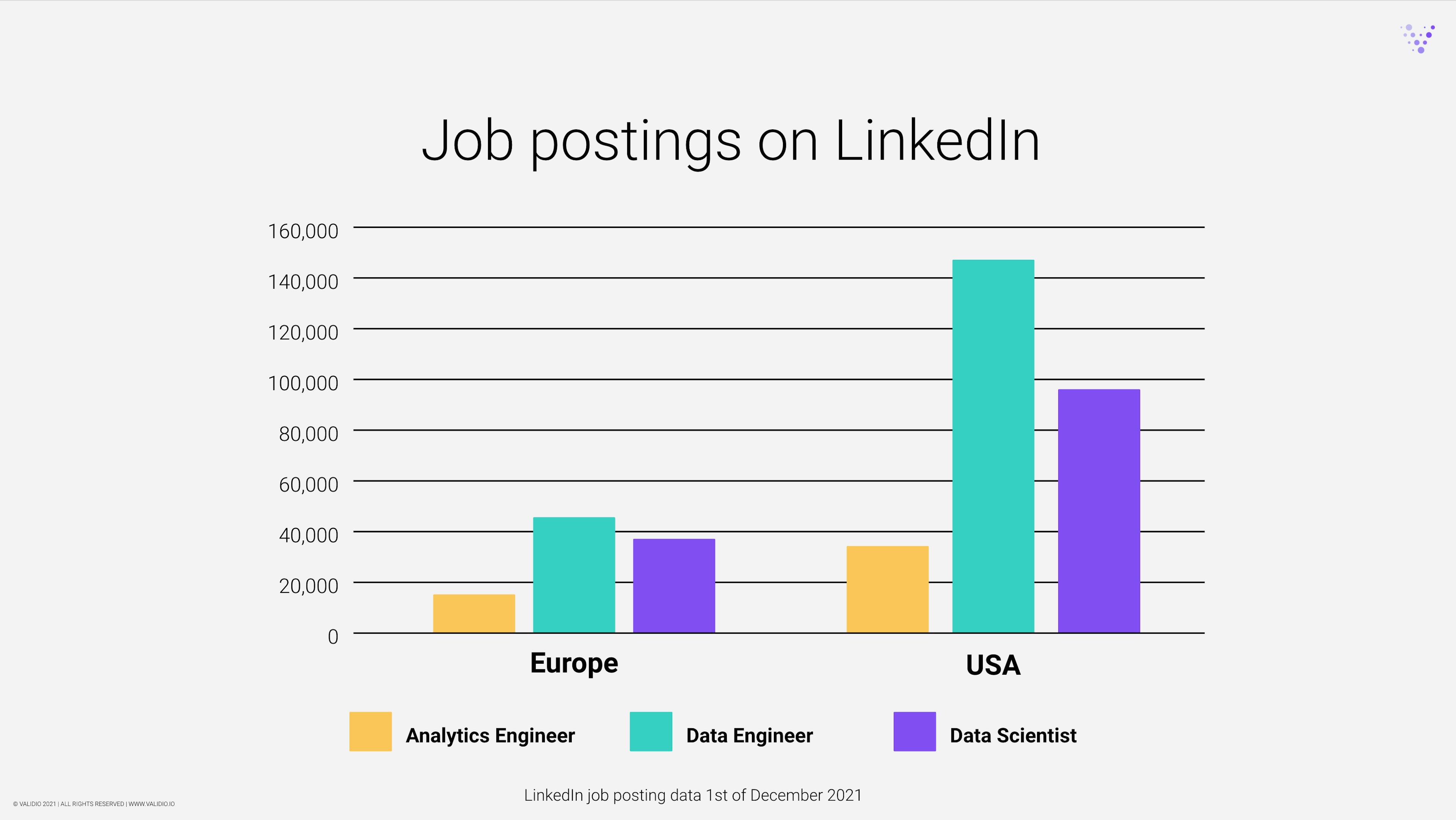
We’re seeing an increasing number of modern data teams adding analytics engineers to their teams as they’re becoming increasingly data-driven and building self-serve data pipelines. Based on data from LinkedIn job posts, typical must-have skills for an analytics engineer include SQL, dbt, Python and tooling connected to the Modern Data Stack(e.g. Snowflake, Fivetran, Prefect, Astronomer, etc).