TL;DR
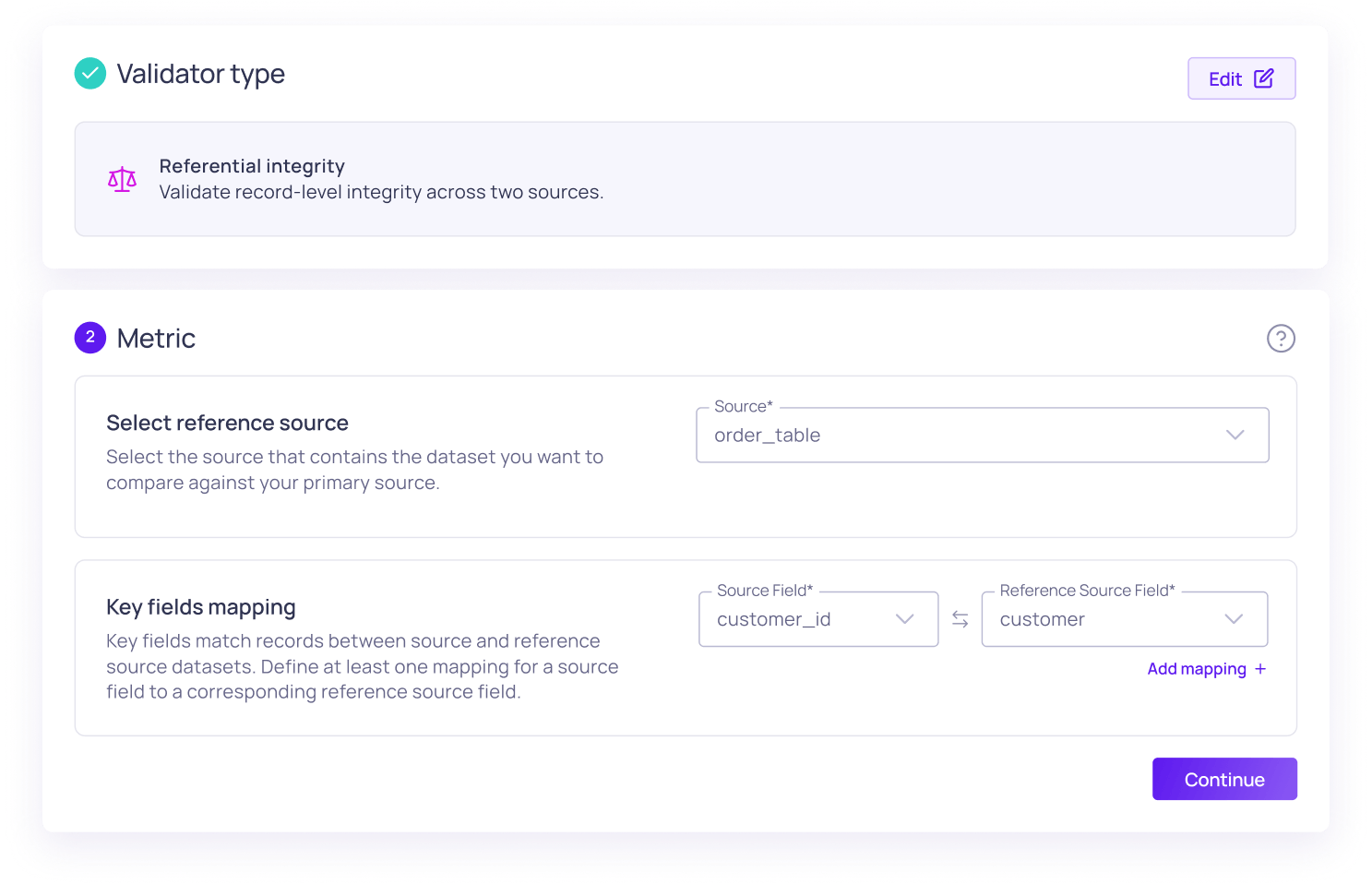
Referential integrity is what keeps your data relationships logical and reliable. When it fails, you end up with orphaned records and mismatched reporting. Here is why it happens, and how Validio’s new functionality lets you validate it without writing custom SQL.
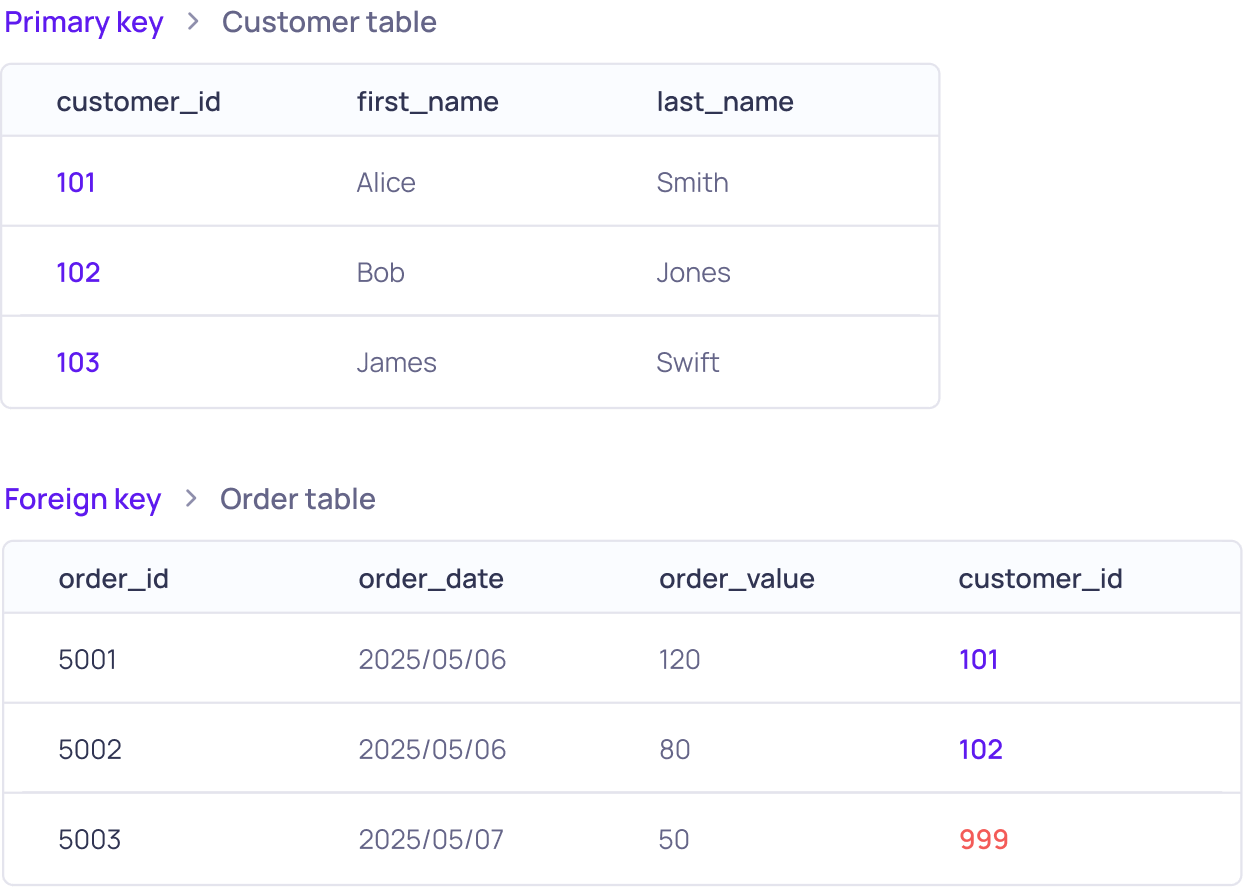
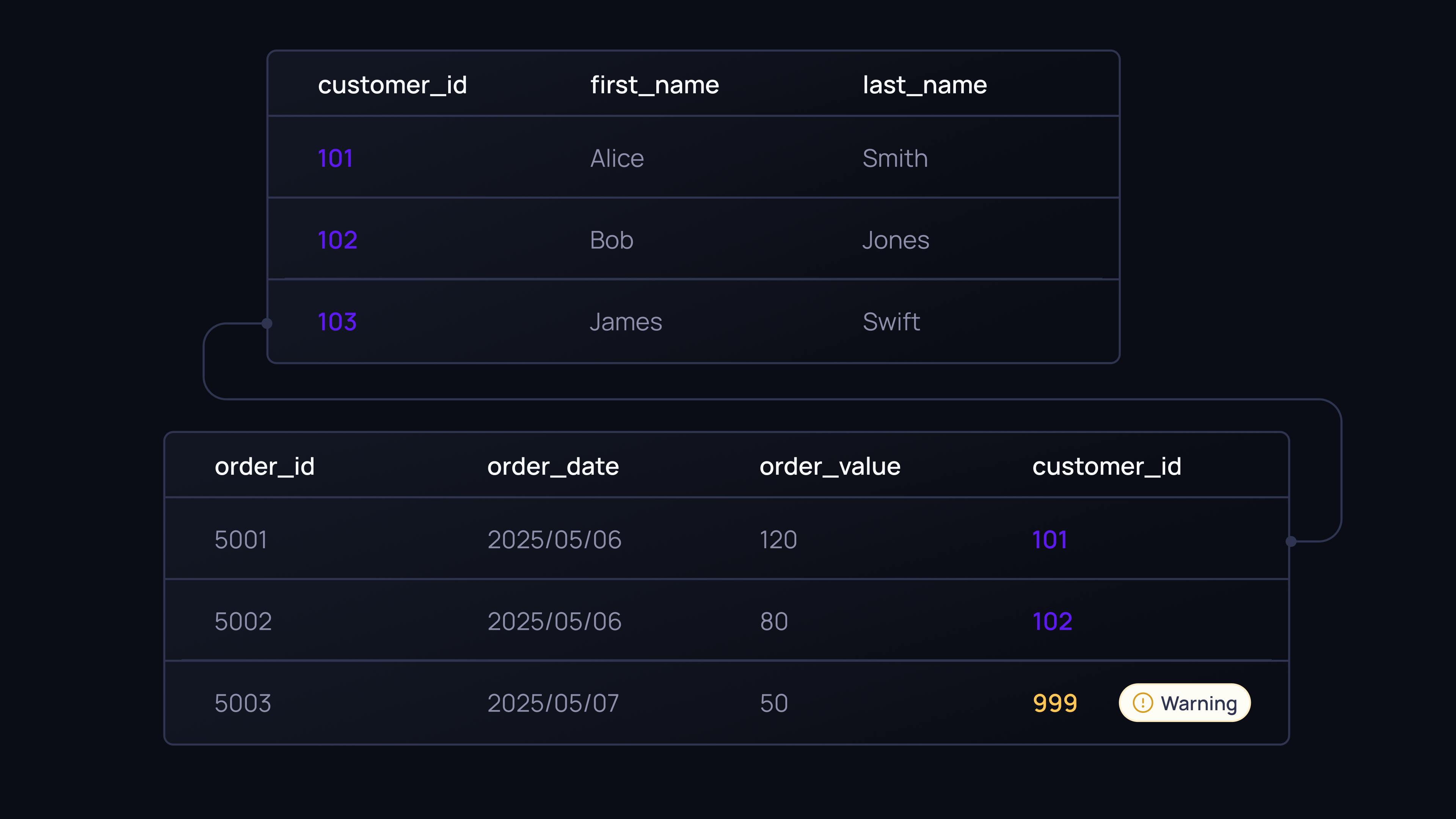
Data is rarely isolated. It is distributed across dozens of tables, schemas, and platforms. Referential integrity is about ensuring that the relationships between these datasets make sense.
While metrics like freshness or null values are about individual fields, referential integrity is about the structure of your data model. If the relationship between tables is broken, you will produce inaccurate results, regardless of how "clean" the individual rows are.