

Amit Sharma is a Data Product Manager, and top voice on Linkedin for Data Quality & Data Governance. This blog post is one of Validio's community collaborations. For more, follow Amit on Linkedin, and join the heroesofdata.com community.
Have you ever attempted to cross a road, bustling with traffic while blindfolded? The odds are quite high that you won't make it across unscathed; you're likely to encounter an injury or a major mishap. Likewise, when it comes to making crucial business decisions, training machine learning models, or building GenAI applications we should avoid relying on data that hasn't been rigorously validated for quality. According to this article, low data quality costs organizations 15 to 25% of their revenue.
Data teams are likely to try and fix these problems with tools and code. However, most data quality problems can be attributed to broken processes in the organization and to communication gaps between data producers and data consumers. In other words, low data quality is not just a tooling problem—it’s also a people and a communication problem.
In this article, I explore how tools — like Data Observability and Data Contracts can help organizations build more inclusive data-driven cultures. Framed differently, I will be exploring how I see that these technologies can help drive a change in organizational culture.
First, we’ll cover some terminology and context. Then, we’ll dive into a proposed step-by-step process that can be followed to build a data-driven culture.
Context on data quality, data contracts, and data observability
Before diving into the meat of this article, let’s start with a few definitions and some context settings for key terminology: data quality, data contracts, and data observability.
Intro to Data Quality
Data quality is defined by Validio in their whitepaper as
“The extent to which an organization’s data can be considered fit for its intended purpose. Data quality should be observed along five dimensions: freshness, volume, schema, (lack of) anomalies, and distribution. It is always relative to the data’s specific business context“
When it comes to the effects of bad data, the 1-10-100 Principle of Data quality, developed by George Labovitz, Yu Sang Chang, and Victor Rosansky in 1993, is a framework used for this purpose.
According to this framework:
- $1 represents the initial cost of assessing data as soon as it's created. Skipping this step increases the cost to $10.
- The $10 signifies the expense that businesses have to bear to remediate the data.
- The initial $1 dramatically escalates to $100 in the third and final phase. This $100 reflects the amount businesses will have to pay when they fail to clean the data promptly.
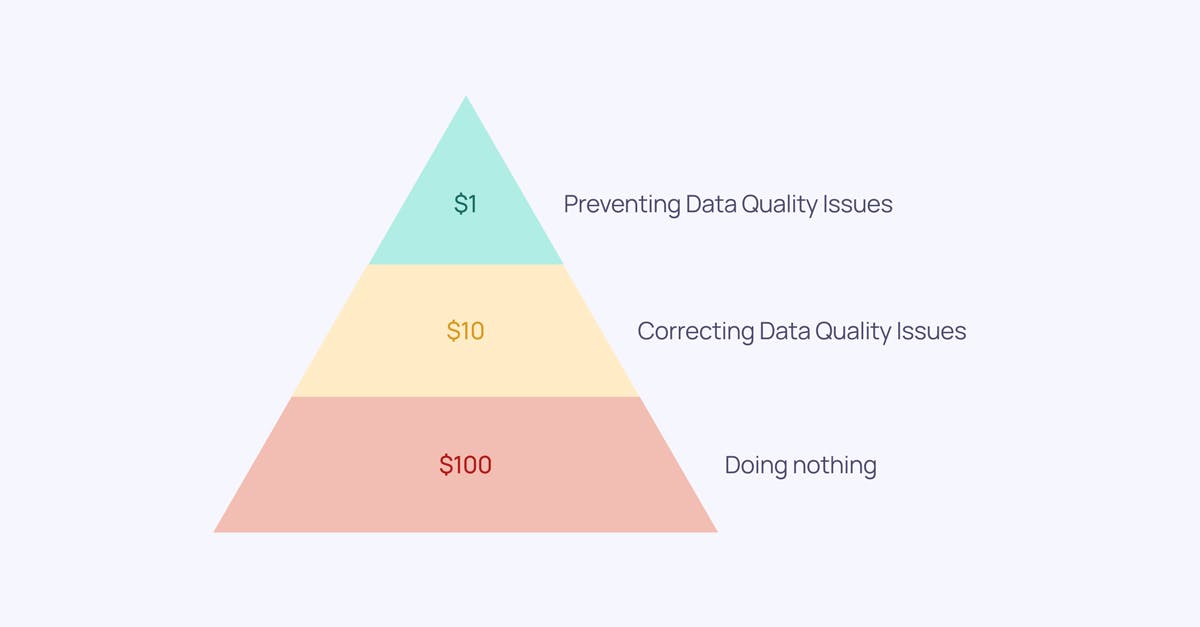
Image by the author. Inspired by Prashanth Southekal.
Keeping this framework in mind, we should continuously work on improving data quality right from the data source, before it undergoes transformations for building various data products. The longer we delay this, the more expensive and challenging it becomes to fix data issues.
Taking a proactive approach, rather than a reactive one, is the most effective way to achieve a high level of data quality. Next up is data contracts.
Intro to Data Contacts
Andrew Jones—the creator of data contracts—defines them as
“A data contract is an agreed interface between the generators of data and its consumers. It sets the expectations around that data, defines how it should be governed and facilitates the explicit generation of quality data that meets the business requirements.”
Once a data contract is established, it can be enforced using necessary tools like CI/CD, GIT, etc. This means that downstream data consumers will consistently receive data in the format and structure specified in the contract. If any deviations violate the contract, the upstream application teams won't be able to make these changes without informing the data consumers.
These contracts can go a step further by tagging Personally Identifiable Information (PII) at the data source, defining data quality checks, and identifying the individuals responsible for these contracts. Data contracts serve as a bridge between data producers and consumers, breaking down the silos within an organization. They improve communication and ensure that everyone is on the same page when it comes to data quality and consistency and this can be the first step an organization can take to create a more inclusive data culture.
Intro to Data Observability
Conversely, Data Observability is defined by Validio in its whitepaper as
“The degree to which an organization has visibility into its data pipelines. A high degree of Data Observability enables data teams to improve data quality.”
There are multiple aspects to data observability, such as schema, quality, freshness, volume, anomaly detection, etc. In many cases, data observability is also combined with data lineage for root-cause analysis. In the following sections, I will explain how some of these aspects can be used by organizations to become more data-driven.
The goal of data observability is to provide insights into the state and behavior of data in real-time, allowing organizations to identify and address issues promptly.
With these definitions in mind, I’ll now propose a process in four steps that can be used to build a data-driven culture using Data contracts and Data Observability platforms as enablers.
Framework to become more Data Driven:
The framework consists of four parts: First, it’s about identifying the most critical data elements and datasets. You must ask: what are the most important datasets the data team can support the business with? Second, determine the present state of data quality since you can’t improve what you can’t measure, and this is a foundation for a data-driven culture. Third, it’s about how to improve data quality. Lastly, we cover how to sustain a data-driven culture over time.
1. Identify the most critical datasets
The first step in becoming a more data-driven organization is to identify the critical data assets used within an organization. This task can be accomplished by using Data Lineage. This is a feature that is provided out-of-the-box by many data observability platforms.
Data Lineage is the process of monitoring and documenting the movement of data as it progresses through different stages of its lifecycle in an organization's data ecosystem. This includes identifying the source, alterations, and final destination of the data, which helps in understanding how the data is gathered, transformed, and utilized within the organization.
Therefore, with data lineage, it’s easy to identify and quantify the share of an organization’s data that is actively utilized. This can help organizations reduce costs and identify critical datasets that have an especially high impact on the business operations or products. In the event of a pipeline failure affecting these critical datasets, data lineage can help data teams understand the root cause and the upstream and downstream impact of these failures. The stakeholders using these datasets can then be informed proactively by the data team about these issues before they find out about these issues. This increases trust in the datasets as they know there are controls placed on these datasets by the data team. Trust between data consumers and producers is a core tenant of a data-driven culture since it helps build alignment between data consumers and producers.
Another approach can be to go through the warehouse query logs for example Snowflake Query Logs and then determine which datasets are getting most frequently queried by the users. However, the best way to prioritize data is to use a data cataloging tool and see which datasets are being used most by the stakeholders. As can be seen in the illustration below only 32% of data collected by organizations is being used.
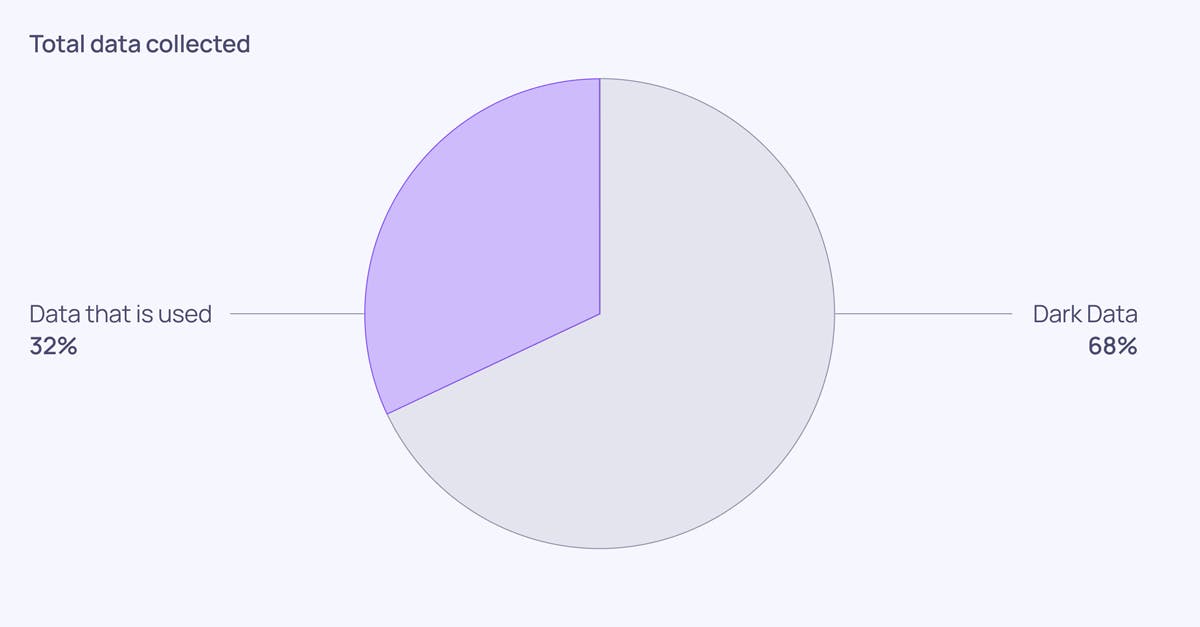
Image by the author.
The deliverables from this phase would be the following items:
- List of datasets that are critical to business and should be the key focus area for further assessments.
- List of datasets that are not being used, popularly known as Dark Data these datasets can be phased out. This will not only result in cost savings for the organization but also help in averting compliance violations and security breaches.
2. Determine the present state of Data Quality for critical datasets
Now we've covered the first step: identifying the critical data assets with data lineage available in data observability tools and data catalogs. This means it's time to dive into the next phase: assessing data quality. As the famous proverb goes ‘You can’t improve what You don’t measure.’ Similarly, without knowing the current state of data quality it cannot be improved.
This brings us to the concept of data quality metrics which can help us measure the current state of data quality. It’s important to note that this step should not be accomplished in isolation by the data engineering team itself. As data quality is heavily context-dependent, understanding how stakeholders are using the data and data products to accomplish their daily tasks can help in coming up with data quality checks as well as the SLA/SLO these data products must adhere to. Hence, the data quality metrics that a data team decides to track should be relevant to stakeholders and tied to the business initiatives identified by the organization. That might mean that metrics should be segmented by e.g. country or product to be relevant to business users.
The data quality dashboards provided by Data Observability tools can be a good place to start the assessment of the critical datasets identified as part of Step 1. A data observability tool can also be used to profile the data and check data against different data quality dimensions like anomalies, data completeness, data freshness, and business rules. These results can be analyzed to get the current state of data quality for critical datasets (the ones identified with the help of lineage and/or catalog in step 1).
At the end of this phase, the following should be determined.
- Data quality metrics: The metrics relevant to an organization that will be tracked to improve data quality, including any segmentation relevant to data consumers.
- Current State of data quality quantified according to the metrics.
- Target state of data quality: Where do we want to be?
- Stakeholders: Who should be informed when a dataset fails validation?
- SLA: Service Level Agreements according to which data incidents should be fixed and by what timelines.
- Communication Channels: The methods of informing the stakeholders—Slack, email, API, or having the notification on the dashboards itself?
3. Achieve the Desired State of Data Quality:
To reach the desired state of data quality, the data team should validate the data as soon as possible after it has been produced. This might mean validation in the data warehouse, but it could also mean validating data directly in the data source or data lake. Data teams should monitor the results of the validations to identify and optimize data pipelines and processes causing data quality issues. All data quality issues should be raised as incidents and expected to be solved within the SLA/SLOs identified in Step 2.
Data producers should be educated about how data is used downstream to build various data products. Processes should be implemented to address data quality issues at the data source level, reducing the cost of data quality assurance later in the data lifecycle. Data literacy programs can play a crucial role by making data producers aware of data consumers' expectations and the consequences of not meeting these requirements.
Data Observability platforms can be used to monitor the health of data flowing through data pipelines. They can also be used for anomaly detection and data profiling to prevent data issues from slipping through and affecting data consumers. In this way, these platforms are necessary for closing the loop between identifying and fixing data quality issues over time. This in turn helps build a data-driven culture; data consumers feel they can trust the data they rely on in their day-to-day jobs.
4. Sustain the required Level of Data Quality:
Once we have data validations in place at different stages of the data pipelines and have reached the desired level of data quality, the project should move to the “sustain phase.” Built-in data quality dashboards provided by data observability tools can be used to track the progress made against each data quality metric and to determine if this state has been reached for a particular data asset or data product.
Data quality review should take place regularly, e.g. bimonthly, where the data quality metrics should be tracked via this data quality dashboard. A detailed root-cause analysis of all identified data issues should be conducted. The findings from the root-cause analysis should be used to set up more data validation that addresses the issues that caused these failures. Processes should also be re-designed to avoid these failures in the future.
The most important functionality provided by data observability tools is that whenever a data incident occurs, it can be easily acted upon by the data engineering team. The incident management process and stakeholder communication can be triggered using the data observability platform.
Conclusion
In this article, I've explained the significance of data quality, emphasizing its importance and the need to tackle it at the source or in the early stages of the data lifecycle. I've outlined a systematic approach to addressing data quality by leveraging data observability platforms and data contracts. Additionally, I've highlighted how these tools can impact the organizational culture and emphasized the importance of making data quality a collective responsibility for everyone within the organization.
Any thoughts on this article? Reach out on Linkedin.